
 Technology peripherals
AI
Tsinghua University releases CurML, the first open source library for course learning
Technology peripherals
AI
Tsinghua University releases CurML, the first open source library for course learning
Tsinghua University releases CurML, the first open source library for course learning

In the development process of machine learning, human learning methods often inspire the design of various algorithms. As an important paradigm of human learning, learning through courses has been borrowed from machine learning to form a research direction called Curriculum Learning.
Generally speaking, human education is completed through highly organized courses. Each course or subject will start with simple content and gradually present students with more complex concepts. For example, before accepting the concepts of calculus in college, a student should first learn arithmetic in elementary school, functions in middle school, and derivatives in high school. However, unlike human education, the training of traditional machine learning models involves randomly inputting data samples into the model, ignoring the different complexities between data samples and the current learning status of the model. Therefore, curriculum learning was proposed in the field of machine learning precisely to imitate human learning from easy to difficult, provide better training strategies for the model, and thereby improve the performance of the model.

Course Learning Concept Map
Currently Curriculum learning has been widely used in various tasks of machine learning, including image classification, target detection, semantic segmentation, machine translation, audio recognition, audio enhancement, video question and answer, etc. It is also used in supervised, unsupervised and semi-supervised learning and Reinforcement learning and other scenarios have received a lot of attention and research.
As the applications and scenarios of course learning become increasingly rich, it is particularly necessary to conduct a detailed sorting and summary in this field, so as to promote in-depth exploration by researchers and improve the application experience of users. .
Therefore, based on the accumulation and foundation of publishing a number of academic papers on course learning, the Media and Network Big Data Laboratory led by Professor Zhu Wenwu of Tsinghua University, laboratory member Wang Xin IEEE TPAMI published a review paper on curriculum learning, and the laboratory further released the world's first open source library for curriculum learning, CurML (Curriculum Machine Learning).
Professor Zhu Wenwu and Assistant Researcher Wang Xin’s curriculum learning research work includes curriculum meta-learning method applied to urban interest location recommendation, curriculum decoupling product recommendation based on noisy multiple feedback information , Shared parameter neural architecture search based on course learning, and combinatorial optimization problem solving based on course difficulty adaptation, etc. Research results have been published in high-level international machine learning conferences such as SIGKDD, NeurIPS, and ACM MM.

##Framework diagram of some research results
The course learning review paper comprehensively reviews all aspects of course learning, such as the emergence, definition, theory and application, designs a unified course learning framework, and divides course learning algorithms into two major categories and multiple categories based on the core components within the framework. This subcategory distinguishes the differences and connections between curriculum learning and other machine learning concepts, and points out the challenges faced by this field and possible future research directions.

Course Learning Method Classification
Course The learning open source library CurML is a support platform for course learning algorithms. It has integrated more than ten course learning algorithms and supports both noisy and non-noisy application scenarios, making it easier for researchers and users to reproduce, evaluate, compare and select course learning. algorithm.
The main module of CurML is CL Trainer, which consists of two sub-modules Model Trainer and CL Algorithm. The two interact through five interface functions to realize a machine for course learning guidance. learning process.

CurML framework diagram
Main module: CL Trainer
This module is the main part of the entire open source library. By calling this module, users can implement the course learning algorithm with just a few lines of code. After given the data set, model and hyperparameters, the module will train for a certain period of time and output the trained model parameters and test results of the task. This module is mainly designed to meet the requirements of ease of use, so it is highly encapsulated and provided to users who want to use the course learning algorithm but do not care about the specific implementation details.
Sub-module 1: Model Trainer
This module is used to complete the general machine learning process, such as training An image classifier or a language model. At the same time, it reserves positions for five interface functions for interacting with the second sub-module CL Algorithm, and also supports custom input functions.
Sub-module 2: CL Algorithm
This module encapsulates all course learning algorithms supported by CurML. As shown in the following table:

The module is implemented through five interface functions, which are used to obtain data and model information from the machine learning process. and the learning strategy to guide the model, as shown in the figure below.

##CurML flow chart
Interface function: data_prepare
This function is used to provide data set information from the Model Trainer module to the CL Algorithm module. Many course learning algorithms require an overall understanding of the data set in order to better judge the difficulty of the data sample, so this interface function is necessary.
Interface function: model_prepare
This function is very similar to data_prepare, the difference is that it does not transfer data set information It is information related to model training, such as model architecture, parameter optimizer, learning rate adjuster, etc. Many course learning algorithms guide machine learning by adjusting these elements.
Interface function: data_curriculum
This function is used to calculate the difficulty of the data sample, and based on the difficulty of the data and the current Model state provides the model with appropriate data, and most courses have similar ideas.
Interface function: model_curriculum
This function is used to update the model and adjust the model’s accuracy obtained from the data sample. The amount of information indirectly guides the learning of the model. Currently, the number of such algorithms is still small, but CurML also supports the implementation of such algorithms.
Interface function: loss_curriculum
This function is used to reweight the loss function value, and the indirect adjustment is different The impact of data on the model. This type of algorithm is more common in course learning, because the weighting of the loss value is essentially a soft sampling of the data.
Through a summary of more than ten course learning methods in recent years, different types of course learning algorithms can be unified and implemented using the above modules and interface parameters, so that they can be used in fair scenarios and Evaluate, compare and select course learning algorithms under the task.
Future Outlook
CurML’s R&D team stated that they will continue to update this open source library in the future to provide further support for the development and application of course learning.
Related links:
- CurML open source code library link: https://github.com/THUMNLab/CurML
- CurML open source software paper link: https://dl.acm.org/doi/pdf/10.1145/3503161.3548549
- Course learning summary paper link: https://ieeexplore.ieee.org/abstract/document/9392296/
- Course meta-learning paper link: https://dl.acm.org/doi/abs/10.1145/ 3447548.3467132
- Course decoupling learning paper link: https://proceedings.neurips.cc/paper/2021/file/e242660df1b69b74dcc7fde711f924ff-Paper.pdf
- Course neural architecture search paper link: https://dl.acm.org/doi/abs/10.1145/3503161.3548271
- ##Course difficulty adaptive paper link: https:// ojs.aaai.org/index.php/AAAI/article/download/20899/version/19196/20658
The above is the detailed content of Tsinghua University releases CurML, the first open source library for course learning. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 This article will take you to understand SHAP: model explanation for machine learning
Jun 01, 2024 am 10:58 AM
This article will take you to understand SHAP: model explanation for machine learning
Jun 01, 2024 am 10:58 AM
In the fields of machine learning and data science, model interpretability has always been a focus of researchers and practitioners. With the widespread application of complex models such as deep learning and ensemble methods, understanding the model's decision-making process has become particularly important. Explainable AI|XAI helps build trust and confidence in machine learning models by increasing the transparency of the model. Improving model transparency can be achieved through methods such as the widespread use of multiple complex models, as well as the decision-making processes used to explain the models. These methods include feature importance analysis, model prediction interval estimation, local interpretability algorithms, etc. Feature importance analysis can explain the decision-making process of a model by evaluating the degree of influence of the model on the input features. Model prediction interval estimate
 Identify overfitting and underfitting through learning curves
Apr 29, 2024 pm 06:50 PM
Identify overfitting and underfitting through learning curves
Apr 29, 2024 pm 06:50 PM
This article will introduce how to effectively identify overfitting and underfitting in machine learning models through learning curves. Underfitting and overfitting 1. Overfitting If a model is overtrained on the data so that it learns noise from it, then the model is said to be overfitting. An overfitted model learns every example so perfectly that it will misclassify an unseen/new example. For an overfitted model, we will get a perfect/near-perfect training set score and a terrible validation set/test score. Slightly modified: "Cause of overfitting: Use a complex model to solve a simple problem and extract noise from the data. Because a small data set as a training set may not represent the correct representation of all data." 2. Underfitting Heru
 The evolution of artificial intelligence in space exploration and human settlement engineering
Apr 29, 2024 pm 03:25 PM
The evolution of artificial intelligence in space exploration and human settlement engineering
Apr 29, 2024 pm 03:25 PM
In the 1950s, artificial intelligence (AI) was born. That's when researchers discovered that machines could perform human-like tasks, such as thinking. Later, in the 1960s, the U.S. Department of Defense funded artificial intelligence and established laboratories for further development. Researchers are finding applications for artificial intelligence in many areas, such as space exploration and survival in extreme environments. Space exploration is the study of the universe, which covers the entire universe beyond the earth. Space is classified as an extreme environment because its conditions are different from those on Earth. To survive in space, many factors must be considered and precautions must be taken. Scientists and researchers believe that exploring space and understanding the current state of everything can help understand how the universe works and prepare for potential environmental crises
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Translator | Reviewed by Li Rui | Chonglou Artificial intelligence (AI) and machine learning (ML) models are becoming increasingly complex today, and the output produced by these models is a black box – unable to be explained to stakeholders. Explainable AI (XAI) aims to solve this problem by enabling stakeholders to understand how these models work, ensuring they understand how these models actually make decisions, and ensuring transparency in AI systems, Trust and accountability to address this issue. This article explores various explainable artificial intelligence (XAI) techniques to illustrate their underlying principles. Several reasons why explainable AI is crucial Trust and transparency: For AI systems to be widely accepted and trusted, users need to understand how decisions are made
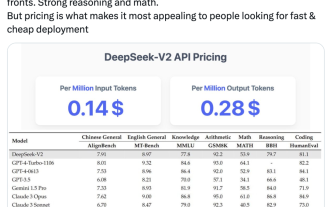 Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent
May 07, 2024 pm 05:34 PM
Domestic open source MoE indicators explode: GPT-4 level capabilities, API price is only one percent
May 07, 2024 pm 05:34 PM
The latest large-scale domestic open source MoE model has become popular just after its debut. The performance of DeepSeek-V2 reaches GPT-4 level, but it is open source, free for commercial use, and the API price is only one percent of GPT-4-Turbo. Therefore, as soon as it was released, it immediately triggered a lot of discussion. Judging from the published performance indicators, DeepSeekV2's comprehensive Chinese capabilities surpass those of many open source models. At the same time, closed source models such as GPT-4Turbo and Wenkuai 4.0 are also in the first echelon. The comprehensive English ability is also in the same first echelon as LLaMA3-70B, and surpasses Mixtral8x22B, which is also a MoE. It also shows good performance in knowledge, mathematics, reasoning, programming, etc. And supports 128K context. Picture this
 Is Flash Attention stable? Meta and Harvard found that their model weight deviations fluctuated by orders of magnitude
May 30, 2024 pm 01:24 PM
Is Flash Attention stable? Meta and Harvard found that their model weight deviations fluctuated by orders of magnitude
May 30, 2024 pm 01:24 PM
MetaFAIR teamed up with Harvard to provide a new research framework for optimizing the data bias generated when large-scale machine learning is performed. It is known that the training of large language models often takes months and uses hundreds or even thousands of GPUs. Taking the LLaMA270B model as an example, its training requires a total of 1,720,320 GPU hours. Training large models presents unique systemic challenges due to the scale and complexity of these workloads. Recently, many institutions have reported instability in the training process when training SOTA generative AI models. They usually appear in the form of loss spikes. For example, Google's PaLM model experienced up to 20 loss spikes during the training process. Numerical bias is the root cause of this training inaccuracy,
