
 Technology peripherals
AI
The road to practical implementation of Soul intelligent voice technology
Technology peripherals
AI
The road to practical implementation of Soul intelligent voice technology
The road to practical implementation of Soul intelligent voice technology

Author | Liu Zhongliang
Compilation| Lu Xinwang
Reviewer| Yun Zhao
In recent years, intelligent voice language technology has developed vigorously, gradually changing the way people produce and live. In the social field, it has put forward higher requirements for intelligent voice technology.
Recently, at the AISummit Global Artificial Intelligence Technology Conference hosted by 51CTO, Liu Zhongliang, the head of Soul voice algorithm, gave a keynote speech "The Road to Practicing Soul Intelligent Voice Technology", based on Some of Soul's business scenarios share some of Soul's practical experience in intelligent voice technology.
The speech content is now organized as follows, hoping to inspire everyone.
Soul’s voice application scenario
Soul is an immersive social scene recommended based on interest graphs. In this scene, there are a lot of voice exchanges, so in A lot of data has been accumulated over the past period of time. At present, there are about millions of hours in a day. If you remove some silence, noise, etc. in voice calls, and only count these meaningful audio clips, there will be about 6 to 7 billion audio clips. Soul's voice service entrances are mainly as follows:
Voice Party
Groups can create rooms where many users can conduct voice chats.
Video Party
In fact, most users of the Soul platform do not want to show their faces or expose themselves, so we made a self-developed 3D The Avatar image or headgear is given to users to help users express themselves better or express themselves without pressure.
Werewolf Game
is also a room, where many people can play games together.
Voice Matching
A more distinctive scenario is voice matching, or it is the same as calling on WeChat, that is, you can chat one-on-one.
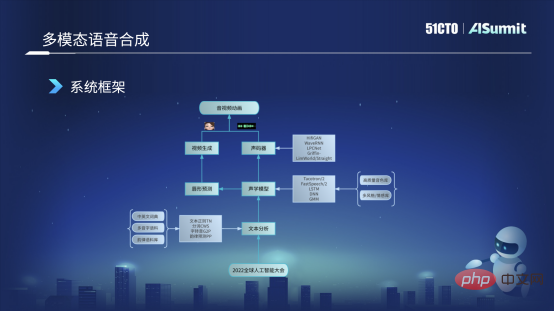
Based on these scenarios, we have built self-developed voice capabilities, mainly focusing on two major directions: the first is natural human-computer interaction, and the second is content understanding and generation. There are four main aspects: the first is speech recognition and speech synthesis; the second is speech analysis and speech animation. The picture below shows the common speech tools we use, which mainly include speech analysis, such as sound quality, sound effects, and music. Then there is speech recognition, such as Chinese recognition, singing voice recognition, and mixed reading of Chinese and English. The third is related to speech synthesis, such as entertainment conversion, voice conversion, and singing synthesis related matters. The fourth is voice animation, which mainly includes some text-driven mouth shapes, voice-driven mouth shapes and other voice animation technologies.
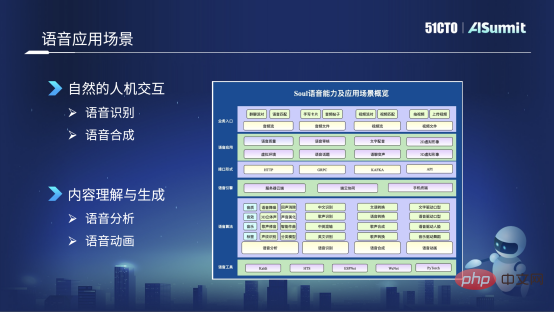
#Based on these speech algorithm capabilities, we have many speech application forms, such as speech quality detection, including enhancement, speech review, text dubbing, and speech Topics, virtual environment sounds, such as these 3D spatial sound effects, etc. The following is an introduction to the technologies used in the two business scenarios of voice review and avatar.
Voice content review
Voice content review is to label audio clips for content related to politics, pornography, abuse, advertising, etc., or to Identification, through the detection and review of these violation tags, to ensure network security. The core technology used here is end-to-end speech recognition, which assists in converting the user's audio into text, and then provides secondary quality inspection to downstream reviewers.
End-to-end speech recognition system
The picture below is an end-to-end speech recognition framework we are currently using. First, it will capture a fragment of the user's audio For feature extraction, there are many features currently used. We mainly use Alfa-Bank features. In some scenarios, we try to use pre-trained features such as Wav2Letter. After obtaining the audio features, an endpoint detection is performed, which is to detect whether the person is speaking and whether there is a human voice in the audio clip. Currently used are basically some classic energy VD and model DNVD.
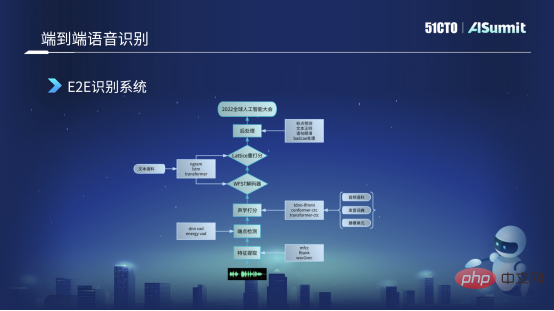
After getting these features, we will send it to an acoustic scoring module. We used Transformer CDC at the beginning for this acoustic model, and it has now been iterated to Conformer CDC. After this acoustic scoring, we will send a series of sequence scores to the decoder. The decoder is responsible for decoding the text, and it will perform a second score based on the recognition results. In this process, the models we use are basically some such as the traditional EngelM model, and some currently more mainstream Transformer deep learning models for re-scoring. Finally, we will also do a post-processing, such as some punctuation detection, text regularization, sentence smoothing, etc., and finally get a meaningful and accurate text recognition result, such as "2022 Global Artificial Intelligence Conference" .
In the end-to-end speech recognition system, in fact, the end-to-end we talk about is mainly in the acoustic scoring part. We use end-to-end technology, and the other parts are mainly traditional and some classic deep learning methods.
In the process of building the above system, we actually encountered many problems. Here are three main ones:
- There is too little supervised acoustic data This is also something that everyone usually encounters. The main reasons are: First, you must listen to the audio before you can annotate it. Second, its labeling cost is also very high. Therefore, the lack of this part of data is a common problem for everyone.
- Poor model recognition effect There are many reasons for this. The first one is that when reading mixed Chinese and English or in multiple fields, using a general model to identify it will be relatively poor.
- The model is slow
To address these problems, we mainly use the following three methods To solve it.
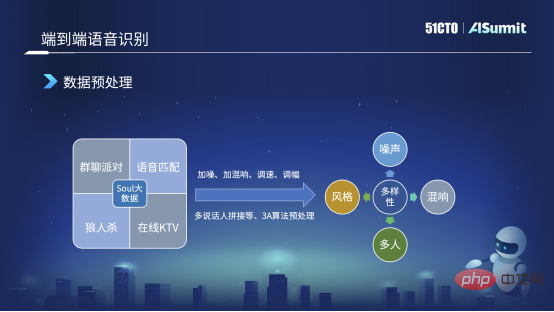
Data preprocessing
Soul has many and complex scenarios. For example, in a group chat party, there will be situations where multiple people overlap or AB has been talking. For example, in online KTV, there will be situations where people are singing and talking at the same time. But when we label data, because it is relatively expensive, we will select relatively clean data under these scenarios for labeling. For example, we may label 10,000 hours of clean data. However, the complexity of clean data is different from the data in real scenarios, so we will do some data preprocessing based on these clean data. For example, some classic data preprocessing methods include adding noise, adding reverberation, adjusting speed, adjusting the speed faster or slower, adjusting the energy, increasing or decreasing the energy.
In addition to these methods, we will do some targeted data preprocessing or data augmentation to address some problems that arise in our business scenarios. For example, I just mentioned that it is easy for multiple speakers to overlap in a group chat party, so we will make a multi-speaker splicing audio, which means we will make a cut of the audio clips of the three speakers ABC and do it together. Data augmentation.
Because some audio and video calls will do some basic 3D algorithm preprocessing on the entire audio front end, such as automatic echo cancellation, intelligent noise reduction, etc., so we also In order to adapt to online usage scenarios, we will also do some preprocessing of 3D algorithms.
After data preprocessing in these ways, we can obtain diverse data, such as data with noise, some reverberation, multiple people or even multiple styles. will be expanded. For example, we will expand 10,000 hours to about 50,000 hours or even 80,000 to 90,000 hours. In this case, the coverage and breadth of the data will be very high.
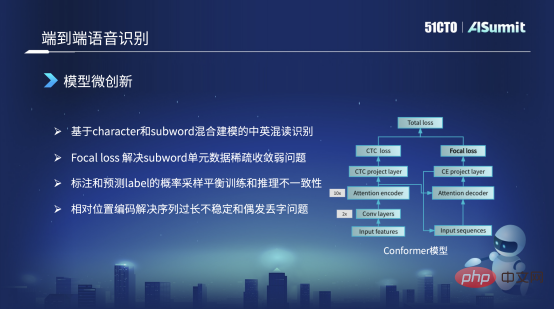
Model micro-innovation
The main framework of the model we use is still the Conformer structure. On the left side of this Conformer structure is the classic Encoder CDC framework. On the right is an Attention Decoder. But everyone noticed that in the Loss on the right, the original Conformer structure was a CE Loss, and we replaced it with a Focal Loss here. The main reason is that we use Focal Loss to solve the problem of non-convergence of sparse units and sparse data training, or the problem of poor training, which can be solved.
For example, in Chinese-English mixed reading, we have very few English words in the training data. In this case, this unit cannot be learned well. Through Focal Loss, we can increase its Loss weight, which can alleviate some quantity problems or poor training problems, and solve some bad cases.
The second point is that our training strategy will be different. For example, we will also use some mixed training methods in the training strategy. For example, in the early training, when we train the Decode part of the input, We still use precisely labeled Label sequence data as input. But as the training model converges, in the later stage we will sample a part of the predicted Labels according to a certain probability as the input of the Decoder to do some tricks. What does this trick mainly solve? It is the phenomenon that the input features of the training model and the online inference model are inconsistent. In this way, we can solve part of it.
But there is another problem. In fact, in the original Conformer model or the model provided by Vnet or ESPnet, the default is absolute position information. However, absolute position information cannot solve the identification problem when the sequence is too long, so we will change the absolute position information into relative position encoding to solve this problem. In this way, problems that arise during the recognition process, such as the repetition of some words or the occasional loss of words or words, can also be solved. This problem can also be solved.
Inference acceleration
The first one is the acoustic model. We will change the autoregressive model to this one based on Encoder CDC The WFST decoding method first solves part of the recognition results, such as NBest, 10best or 20best. Based on 20best, we will send it to Decorde Rescore for a second re-scoring. This can avoid timing dependencies and facilitate GPT parallel calculation or reasoning.
In addition to the classic acceleration method, we also use a hybrid quantization method, that is, in the process of deep learning forward reasoning, we use 8Bit for part of the calculation, but In the core part, such as the financial function part, we still use 16bit, mainly because we will make an appropriate balance between speed and accuracy.
After these optimizations, the entire inference speed is relatively fast. But during our actual launch process, we also discovered some small problems, which I think can be regarded as a trick.
At the language model level, for example, our scene has a lot of chatting text, but there are also singing. We need the same model to solve both speaking and Solve the singing. In terms of language models, such as chatting text, it is usually fragmented and short, so after our experiments, we found that the three-element model is better, but the five-element model did not bring improvement.
But for example, in the case of singing, its text is relatively long, and its sentence structure and grammar are relatively fixed, so during the experiment, five yuan is better than three yuan. In this case, we use a hybrid grammar to jointly model the language model of the chat text and the singing text. We used the "three-yuan and five-yuan" mixing model, but this "three-yuan and five-yuan" mixing is not a difference in our traditional sense. We did not make a difference, but combined the chatting three-yuan grammar with the four-yuan Take Yuan's singing and Wuyuan's grammar and merge them directly. The arpa obtained in this way is currently smaller and faster in the decoding process. More importantly, it takes up less video memory. Because when decoding on the GPU, the video memory size is fixed. Therefore, we need to control the size of the language model to a certain extent to improve the recognition effect through the language model as much as possible.
After some optimization and tricking of the acoustic model and language model, our current inference speed is also very fast. The real-time rate can basically reach the level of 0.1 or 0.2.

Virtual simulation
mainly helps users to more accurately generate content such as sounds, mouth shapes, expressions, postures, etc. One of the core technologies needed to express without pressure or more naturally and freely is multi-modal speech synthesis.
Multimodal speech synthesis
The following figure is the basic framework of the speech synthesis system currently in use. First, we will get the user's input text, such as "2022 Global Artificial Intelligence Conference", and then we will send it to the text analysis module. This module mainly analyzes the text in various aspects, such as text regularization, and Some word segmentation, the most important thing is self-transfer, converting words into phonemes, and some rhyme prediction and other functions. After this text analysis, we can get some linguistic features of the user's sentence, and these features will be sent to the acoustic model. For the acoustic model, we currently mainly use some model improvements and training based on the FastSpeech framework.
The acoustic model obtains acoustic features, such as Mel features, or duration or energy and other information, and its feature flow direction will be divided into two parts. We will send part of it to the vocoder, which is mainly used to generate audio waveforms that we can listen to. The other flow direction is sent to lip shape prediction. We can predict the BS coefficient corresponding to the lip shape through the lip shape prediction module. After getting the BS feature value, we will send it to the video generation module, which is the responsibility of the visual team and can generate a virtual avatar, which is a virtual image with mouth shape and expression. In the end, we will merge the virtual avatar and audio, and finally generate audio and video animation. This is the basic framework and basic process of our entire multi-modal speech synthesis.
Main issues in the multi-modal speech synthesis process:
- Speech sound library Data quality is relatively poor.
- The synthesized sound quality is poor.
- The audio and video delay is large, and the mouth shape and voice do not match
Soul’s processing method is in line with improving end-to-end voice Similar in recognition system.
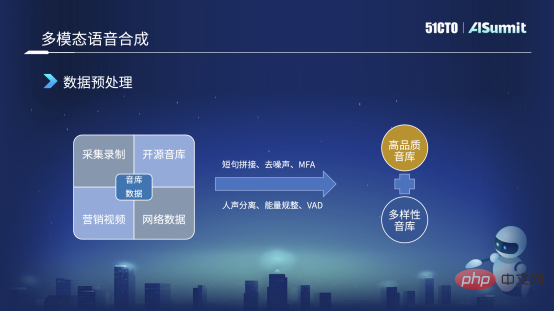
Data Preprocessing
Our sound library comes from many sources. The picture on the left is the first one we will collect and record. Second, of course we are very grateful to the open source data company, which will open source some sound libraries, and we will also use them to do some experiments. Third, there will be some public marketing videos at the company level on our platform. When making the videos, we invited some high-quality anchors to make them, so the sound quality is also very high-quality. Fourth, some public network data, such as in the process of dialogue, some timbres are of relatively high quality, so we will also crawl some and then do some pre-annotation, mainly to do some internal experiments and pre-training.
In response to the complexity of these data, we did some data preprocessing, such as splicing short sentences. As mentioned just now, during the collection process, sentences may be long or short. We In order to increase the length of the sound library, we will make a cut of the short sentence, and we will remove some silence during the process. If the silence is too long, it will have some effects.
The second is denoising. For example, in the network data or marketing videos we get, we will remove the noise through some speech enhancement methods.
Third, in fact, most of the current annotations are phonetic-to-character annotations, but the boundaries of phonemes are basically not used as annotations now, so we usually use this MFA to force Alignment method to obtain phoneme boundary information.
Then the vocal separation below is quite special, because we have background music in the marketing video, so we will do a vocal separation and give the background music Remove it and obtain the dry sound data. We also do some energy regularization and some VAD. VAD is mainly in dialogue or network data. I use VAD to detect effective human voices, and then use them to do some pre-annotation or pre-training.
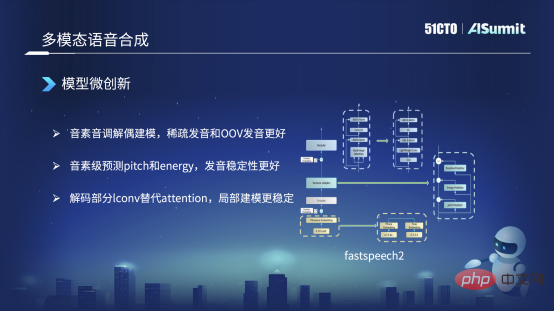
Model micro-innovation
In the process of making FastSpeech, we mainly made changes in three aspects. The type on the left of the picture on the left is the basic model of FastSpeech. The first change we made is that we will decouple phonemes and tones for modeling. That is, under normal circumstances, what our text front-end converts is a sequence of phonemes, like Same as the picture on the left, a monotonous sequence of phonemes like "hello". But we will split it into the right part, two parts, that is, the left part is a phoneme sequence, with only phonemes and no tones. The one on the right has only tones and no phonemes. In this case, we will send them to a ProNet (sound) respectively and get two Embeddings. The two Embeddings will be cut together to replace the previous Embedding method. In this case, the advantage is that it can solve the problem of sparse pronunciation, or some pronunciations are not in our training corpus. This kind of problem can basically be solved.
The second way we changed is that the original way is to first predict a duration, which is the picture on the right, and then based on this duration we expand the sound set, and then predict the energy and Pitch. Now we have changed the order. We will predict Pitch and Energy based on the phoneme level, and then after prediction, we will extend it to a frame-level duration. The advantage of this is that its pronunciation is relatively stable throughout the entire pronunciation process of the complete phoneme. This is a change in our scenario.
The third one is that we made an alternative change in the Decoder part, which is the top part. The original Decoder used the Attention method, but we have now switched to the Iconv or Convolution method. This advantage is because although Self-Attention can capture very powerful historical information and contextual information, its ability to gradually model is relatively poor. So after switching to Convolution, our ability to handle this kind of local modeling will be better. For example, when pronunciation, the phenomenon just mentioned that the pronunciation is relatively mute or fuzzy can basically be solved. These are some of the major changes we have currently.
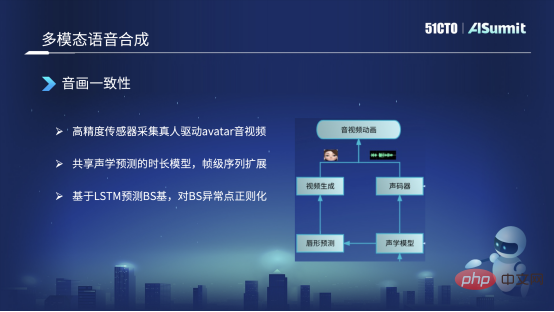
Shared acoustic model
The left side is the synthesized mouth shape, and the right side is the synthesized voice. They share some Encoder and duration in the acoustic model information.
We mainly did three actions. The first one is that we actually collect some high-precision data. For example, we will find some real people to wear some high-precision sensors to drive the Avatar image we have predicted, obtain high-resolution audio and video, and do some annotations. . In this way, you will get some synchronized data of text, audio, and video.
The second thing is, it may also be mentioned how we solve the consistency of sound and picture? Because we first synthesize the sound through text synthesis at the beginning. After getting the sound, we will make a prediction from the sound to the mouth shape. In this process, it will appear asymmetry at the frame level. At present, we use this method of sharing acoustic models between synthesized mouth shapes and synthesized sounds, and do it after the frame-level sequence is expanded. At present, it can be guaranteed to be aligned at the frame level, ensuring the consistency of audio and video.
Finally, we currently do not use a sequence-based method to predict mouth shapes or BS bases. We predict BS bases based on LSTM. After the predicted BS coefficient, but it may predict some abnormalities, we will also do some post-processing, such as regularization. For example, if the BS basis is too large or too small, it will cause the mouth shape to open too wide or even change too small. We will set a The scope cannot be too large and will be controlled within a reasonable range. At present, it is basically possible to ensure the consistency of audio and video.
Future Outlook
The first is multi-modal recognition. In high-noise situations, audio is combined with mouth shape for multi-modal recognition. , improve the recognition accuracy.
The second is multi-modal speech synthesis and real-time speech conversion, which can retain the user's emotion and style characteristics, but only converts the user's timbre to another timbre.
The above is the detailed content of The road to practical implementation of Soul intelligent voice technology. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
