
 Technology peripherals
AI
VectorFlow: Combining images and vectors for traffic occupancy and flow prediction
Technology peripherals
AI
VectorFlow: Combining images and vectors for traffic occupancy and flow prediction
VectorFlow: Combining images and vectors for traffic occupancy and flow prediction

arXiv paper "VectorFlow: Combining Images and Vectors for Traffic Occupancy and Flow Prediction", August 9, 2022, working at Tsinghua University.

# Predicting the future behavior of road agents is a key task in autonomous driving. Although existing models have achieved great success in predicting the future behavior of agents, effectively predicting the coordinated behavior of multiple agents remains a challenge. Recently, someone proposed occupancy flow fields (OFF) representation, which represents the joint future state of road agents through a combination of occupancy grids and flows, supporting jointly consistent predictions.
This work proposes a new occupancy flow fields predictor, an image encoder that learns features from rasterized traffic images, and a vector encoder that captures continuous agent trajectory and map state information, both Combined to generate accurate occupancy and flow predictions. The two encoding features are fused by multiple attention modules before generating the final prediction. The model ranked third in the Waymo Open Dataset Occupancy and Flow Prediction Challenge and achieved the best performance in the occluded occupancy and flow prediction task.
OFF representation ("Occupancy Flow Fields for Motion Forecasting in Autonomous Driving", arXiv 2203.03875, 3, 2022) is a space-time grid in which each grid cell includes i) The probability that any agent occupies a unit and ii) represents the flow of movement of the agent occupying that unit. It provides better efficiency and scalability because the computational complexity of predicting occupancy flow fields is independent of the number of road agents in the scene.
The picture shows the OFF frame diagram. The encoder structure is as follows. The first stage receives all three types of input points and processes them with PointPillars-inspired encoders. Traffic lights and road points are placed directly on the grid. The state encoding of the agent at each input time step t is to uniformly sample a fixed-size point grid from each agent BEV box, and combine these points with the relevant agent state attributes (including the one-hot encoding of time t ) placed on the grid. Each pillar outputs an embedding for all points it contains. The decoder structure is as follows. The second level receives each pillar embedding as input and generates per grid cell occupancy and flow predictions. The decoder network is based on EfficientNet, using EfficientNet as the backbone to process each pillar embedding to obtain feature maps (P2,...P7), where Pi is downsampled 2^i from the input. The BiFPN network is then used to fuse these multi-scale features in a bidirectional manner. Then, the highest resolution feature map P2 is used to regress the occupancy and flow predictions for all agent classes K at all time steps. Specifically, the decoder outputs a vector for each grid cell while predicting occupancy and flow.
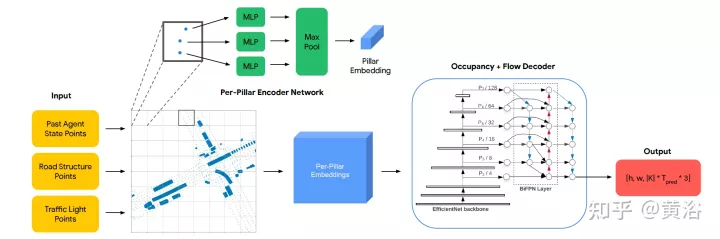
For this article, the following problem setting is made: given the 1-second history of the traffic agent in the scene and the scene context, such as map coordinates, the goal is to predict i) future observations occupancy, ii) occupancy of future occlusions, and iii) future flows of all vehicles at 8 future waypoints in a scene, where each waypoint covers an interval of 1 second.
Process the input into a rasterized image and a set of vectors. To obtain the image, a rasterized grid is created at each time step in the past relative to the local coordinates of the self-driving car (SDC), given the observation agent trajectory and map data. To obtain a vectorized input consistent with the rasterized image, the same transformations are followed, rotating and moving the input agent and map coordinates relative to the SDC's local view.
The encoder consists of two parts: the VGG-16 model that encodes rasterized representation, and the VectorNe model that encodes vectorized representation. The vectorized features are fused with the features of the last two steps of VGG-16 through the cross attention module. Through the FPN-style network, the fused features are upsampled to the original resolution and used as input rasterized features.
The decoder is a single 2D convolutional layer that maps the encoder output to the occupancy flow fields prediction, which consists of a series of 8 grid maps representing each time in the next 8 seconds Step occupancy and flow prediction.
as the picture shows:
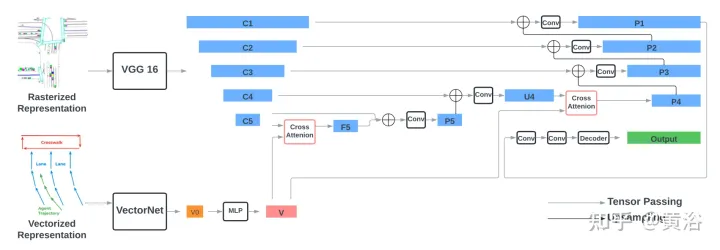
Use torchvision’s standard VGG-16 model as the rasterization encoder and follow VectorNet (code https://github.com/Tsinghua -MARS-Lab/DenseTNT) implementation. The input to VectorNet consists of i) a set of road element vectors of shape B×Nr×9, where B is the batch size, Nr=10000 is the maximum number of road element vectors, and the last dimension 9 represents each vector and the vector ID The position (x, y) and direction (cosθ, sinθ) of the two endpoints; ii) a set of agent vectors with a shape of B×1280×9, including vectors of up to 128 agents in the scene, where each agent With 10 vectors from the observation position.
Follow VectorNet, first run the local map according to the ID of each traffic element, and then run the global map on all local features to obtain vectorized features of shape B×128×N, where N is the traffic element’s Total, including path elements and intelligence. The size of the feature is further increased four times through the MLP layer to obtain the final vectorized feature V, whose shape is B × 512 × N, and its feature size is consistent with the channel size of the image feature.
The output features of each level of VGG are represented as {C1, C2, C3, C4, C5}, relative to the input image and 512 hidden dimensions, the strides are {1, 2, 4, 8, 16} pixels. The vectorized feature V is fused with the rasterized image feature C5 of shape B×512×16×16 through the cross attention module to obtain F5 of the same shape. The query item of the cross attention is the image feature C5, which is flattened into a B×512×256 shape with 256 tokens, and the Key and Value items are the vectorized feature V with N tokens.
Then connect F5 and C5 on the channel dimension, and pass through two 3×3 convolutional layers to obtain P5 with a shape of B×512×16×16. P5 is upsampled through the FPN-style 2×2 upsampling module and connected to C4 (B×512×32x32) to generate U4 with the same shape as C4. Another round of fusion is then performed between V and U4, following the same procedure, including cross-attention, to obtain P4 (B × 512 × 32 × 32). Finally, P4 is gradually upsampled by the FPN style network and connected with {C3, C2, C1} to generate EP1 with a shape of B×512×256×256. Pass P1 through two 3×3 convolutional layers to obtain the final output feature with a shape of B×128×256.
The decoder is a single 2D convolutional layer with an input channel size of 128 and an output channel size of 32 (8 waypoints × 4 output dimensions).
The results are as follows:
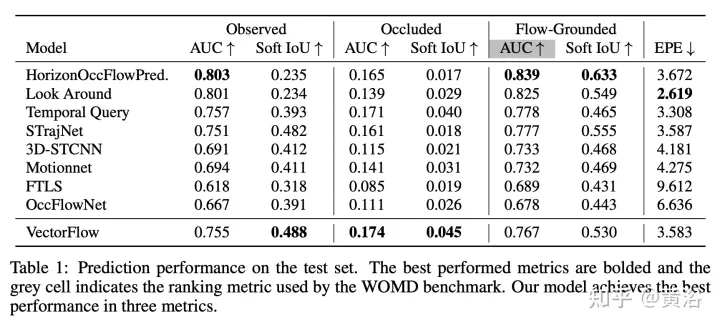
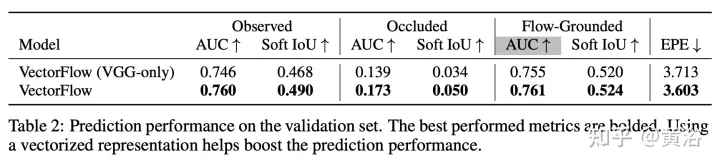
The above is the detailed content of VectorFlow: Combining images and vectors for traffic occupancy and flow prediction. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Smart App Control on Windows 11: How to turn it on or off
Jun 06, 2023 pm 11:10 PM
Smart App Control on Windows 11: How to turn it on or off
Jun 06, 2023 pm 11:10 PM
Intelligent App Control is a very useful tool in Windows 11 that helps protect your PC from unauthorized apps that can damage your data, such as ransomware or spyware. This article explains what Smart App Control is, how it works, and how to turn it on or off in Windows 11. What is Smart App Control in Windows 11? Smart App Control (SAC) is a new security feature introduced in the Windows 1122H2 update. It works with Microsoft Defender or third-party antivirus software to block potentially unnecessary apps that can slow down your device, display unexpected ads, or perform other unexpected actions. Smart application
 The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
Dec 14, 2023 pm 11:30 PM
The facial features are flying around, opening the mouth, staring, and raising eyebrows, AI can imitate them perfectly, making it impossible to prevent video scams
Dec 14, 2023 pm 11:30 PM
With such a powerful AI imitation ability, it is really impossible to prevent it. It is completely impossible to prevent it. Has the development of AI reached this level now? Your front foot makes your facial features fly, and on your back foot, the exact same expression is reproduced. Staring, raising eyebrows, pouting, no matter how exaggerated the expression is, it is all imitated perfectly. Increase the difficulty, raise the eyebrows higher, open the eyes wider, and even the mouth shape is crooked, and the virtual character avatar can perfectly reproduce the expression. When you adjust the parameters on the left, the virtual avatar on the right will also change its movements accordingly to give a close-up of the mouth and eyes. The imitation cannot be said to be exactly the same, but the expression is exactly the same (far right). The research comes from institutions such as the Technical University of Munich, which proposes GaussianAvatars, which
 MotionLM: Language modeling technology for multi-agent motion prediction
Oct 13, 2023 pm 12:09 PM
MotionLM: Language modeling technology for multi-agent motion prediction
Oct 13, 2023 pm 12:09 PM
This article is reprinted with permission from the Autonomous Driving Heart public account. Please contact the source for reprinting. Original title: MotionLM: Multi-Agent Motion Forecasting as Language Modeling Paper link: https://arxiv.org/pdf/2309.16534.pdf Author affiliation: Waymo Conference: ICCV2023 Paper idea: For autonomous vehicle safety planning, reliably predict the future behavior of road agents is crucial. This study represents continuous trajectories as sequences of discrete motion tokens and treats multi-agent motion prediction as a language modeling task. The model we propose, MotionLM, has the following advantages: First
 Do you know that programmers will be in decline in a few years?
Nov 08, 2023 am 11:17 AM
Do you know that programmers will be in decline in a few years?
Nov 08, 2023 am 11:17 AM
"ComputerWorld" magazine once wrote an article saying that "programming will disappear by 1960" because IBM developed a new language FORTRAN, which allows engineers to write the mathematical formulas they need and then submit them. Give the computer a run, so programming ends. A few years later, we heard a new saying: any business person can use business terms to describe their problems and tell the computer what to do. Using this programming language called COBOL, companies no longer need programmers. . Later, it is said that IBM developed a new programming language called RPG that allows employees to fill in forms and generate reports, so most of the company's programming needs can be completed through it.
 GR-1 Fourier Intelligent Universal Humanoid Robot is about to start pre-sale!
Sep 27, 2023 pm 08:41 PM
GR-1 Fourier Intelligent Universal Humanoid Robot is about to start pre-sale!
Sep 27, 2023 pm 08:41 PM
The humanoid robot is 1.65 meters tall, weighs 55 kilograms, and has 44 degrees of freedom in its body. It can walk quickly, avoid obstacles quickly, climb steadily up and down slopes, and resist impact interference. You can now take it home! Fourier Intelligence's universal humanoid robot GR-1 has started pre-sale. Robot Lecture Hall Fourier Intelligence's Fourier GR-1 universal humanoid robot has now opened for pre-sale. GR-1 has a highly bionic trunk configuration and anthropomorphic motion control. The whole body has 44 degrees of freedom. It has the ability to walk, avoid obstacles, cross obstacles, go up and down slopes, resist interference, and adapt to different road surfaces. It is a general artificial intelligence system. Ideal carrier. Official website pre-sale page: www.fftai.cn/order#FourierGR-1# Fourier Intelligence needs to be rewritten.
 Huawei will launch the Xuanji sensing system in the field of smart wearables, which can assess the user's emotional state based on heart rate
Aug 29, 2024 pm 03:30 PM
Huawei will launch the Xuanji sensing system in the field of smart wearables, which can assess the user's emotional state based on heart rate
Aug 29, 2024 pm 03:30 PM
Recently, Huawei announced that it will launch a new smart wearable product equipped with Xuanji sensing system in September, which is expected to be Huawei's latest smart watch. This new product will integrate advanced emotional health monitoring functions. The Xuanji Perception System provides users with a comprehensive health assessment with its six characteristics - accuracy, comprehensiveness, speed, flexibility, openness and scalability. The system uses a super-sensing module and optimizes the multi-channel optical path architecture technology, which greatly improves the monitoring accuracy of basic indicators such as heart rate, blood oxygen and respiration rate. In addition, the Xuanji Sensing System has also expanded the research on emotional states based on heart rate data. It is not limited to physiological indicators, but can also evaluate the user's emotional state and stress level. It supports the monitoring of more than 60 sports health indicators, covering cardiovascular, respiratory, neurological, endocrine,
 What are the effective methods and common Base methods for pedestrian trajectory prediction? Top conference papers sharing!
Oct 17, 2023 am 11:13 AM
What are the effective methods and common Base methods for pedestrian trajectory prediction? Top conference papers sharing!
Oct 17, 2023 am 11:13 AM
Trajectory prediction has been gaining momentum in the past two years, but most of it focuses on the direction of vehicle trajectory prediction. Today, Autonomous Driving Heart will share with you the algorithm for pedestrian trajectory prediction on NeurIPS - SHENet. In restricted scenes, human movement patterns are usually To a certain extent, it conforms to limited rules. Based on this assumption, SHENet predicts a person's future trajectory by learning implicit scene rules. The article has been authorized to be original by Autonomous Driving Heart! The author's personal understanding is that currently predicting a person's future trajectory is still a challenging problem due to the randomness and subjectivity of human movement. However, human movement patterns in constrained scenes often vary due to scene constraints (such as floor plans, roads, and obstacles) and human-to-human or human-to-object interactivity.
 Read the smart car skateboard chassis in one article
May 24, 2023 pm 12:01 PM
Read the smart car skateboard chassis in one article
May 24, 2023 pm 12:01 PM
01 What is a skateboard chassis? The so-called skateboard chassis integrates the battery, electric transmission system, suspension, brakes and other components on the chassis in advance to achieve separation of the body and chassis and decoupling the design. Based on this type of platform, car companies can significantly reduce early R&D and testing costs, while quickly responding to market demand to create different models. Especially in the era of driverless driving, the layout of the car is no longer centered on driving, but will focus on space attributes. The skateboard-type chassis can provide more possibilities for the development of the upper cabin. As shown in the picture above, of course when we look at the skateboard chassis, we should not be framed by the first impression of "Oh, it is a non-load-bearing body" when we come up. There were no electric cars back then, so there were no battery packs worth hundreds of kilograms, no steering-by-wire system that could eliminate the steering column, and no brake-by-wire system.
