

Text generation tasks are usually trained using teacher forcing. This training method allows the model to only see positive samples during the training process. However, there are usually certain constraints between the generation target and the input. These constraints are usually reflected by key elements in the sentence. For example, in the query rewriting task, "order McDonald's" cannot be changed to "order KFC". This plays a role in The key element of restraint is brand keywords. By introducing contrastive learning and adding negative sample patterns to the generation process, the model can effectively learn these constraints.
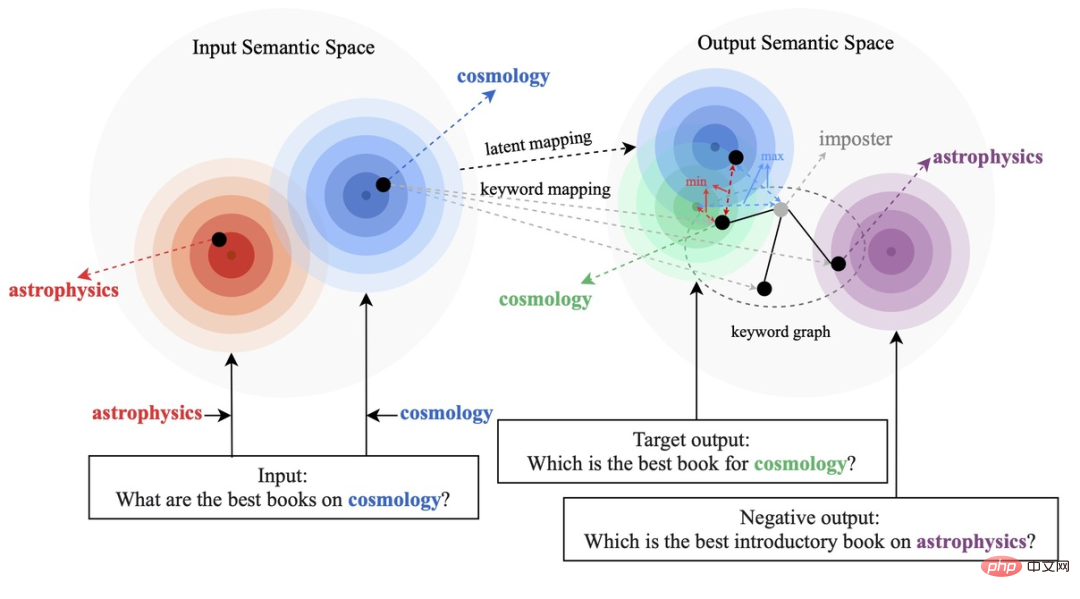
Existing comparative learning methods mainly focus on the whole sentence level [1][2], while ignoring the word-granular entities in the sentence. Information, the example in the figure below shows the important meaning of keywords in the sentence. For an input sentence, if its keywords are replaced (e.g. cosmology->astrophysics), the meaning of the sentence will change, thus in the semantic space The position in (represented by the distribution) also changes. As the most important information in a sentence, keywords correspond to a point in the semantic distribution, which to a large extent determines the position of the sentence distribution. At the same time, in some cases, the existing contrastive learning objectives are too easy for the model, resulting in the model being unable to truly learn the key information between positive and negative examples.
Based on this, researchers from Ant Group, Peking University and other institutions proposed a multi-granularity comparison generation method and designed a hierarchical comparison structure. Information enhancement is performed at the level of learning, enhancing the overall semantics of learning at the sentence granularity, and enhancing local important information at the word granularity. Research paper has been accepted for ACL 2022.

Paper address: https://aclanthology.org/2022.acl-long.304.pdf
Our method is based on the classic CVAE In the text generation framework [3][4], each sentence can be mapped to a distribution in vector space, and the keywords in the sentence can be regarded as a point sampled from this distribution. On the one hand, we enhance the expression of latent space vector distribution through the comparison of sentence granularity. On the other hand, we enhance the expression of keyword point granularity through the constructed global keyword graph. Finally, we use Mahalanobis distance to compare the distribution of keyword points and sentences. Contrast between construct levels to enhance information expression at two granularities. The final loss function is obtained by adding three different contrastive learning losses.
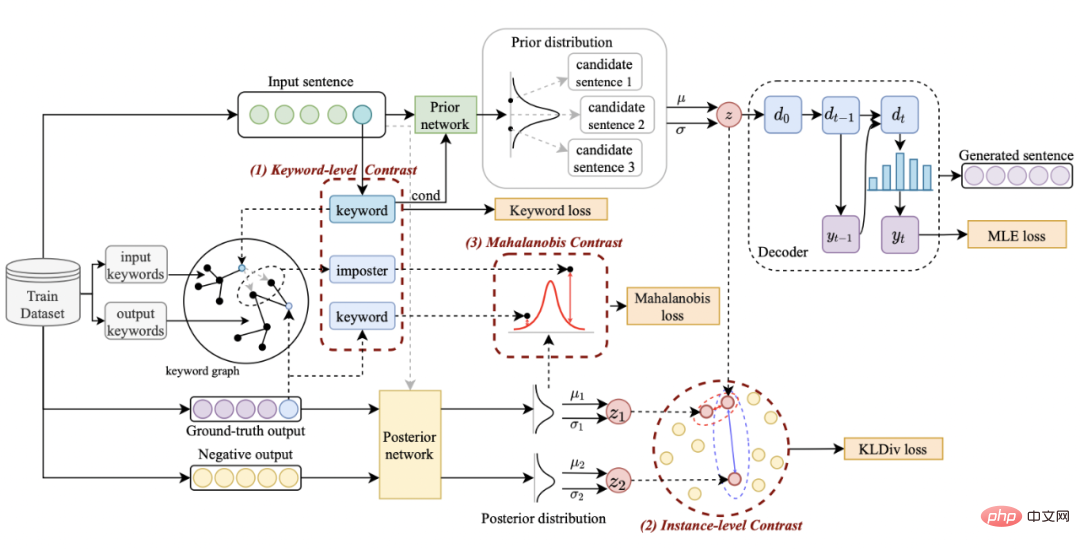
at Instance-level, we use the original input x, the target output

and the corresponding output negative sample to form the sentence granularity Compare pair
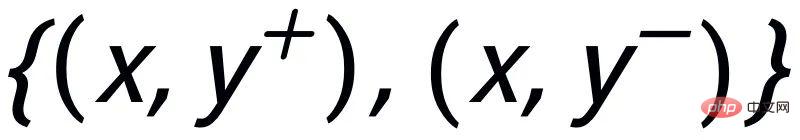
. We use a prior network to learn the prior distribution
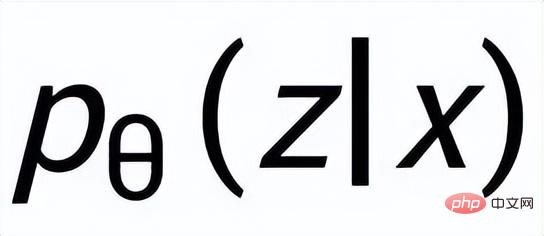
##, recorded as
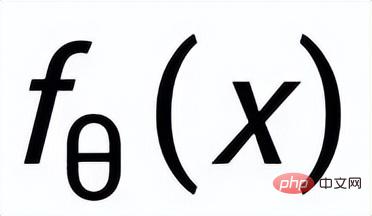
#; Learn an approximate posterior distribution through a posterior network
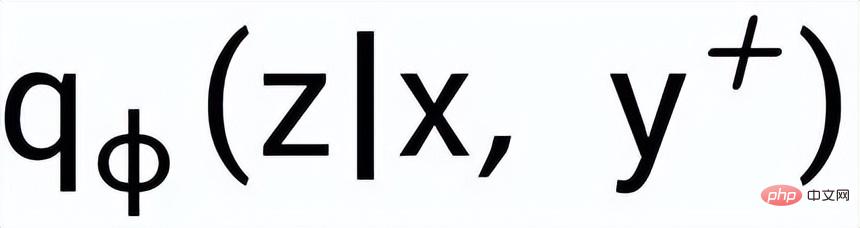
and
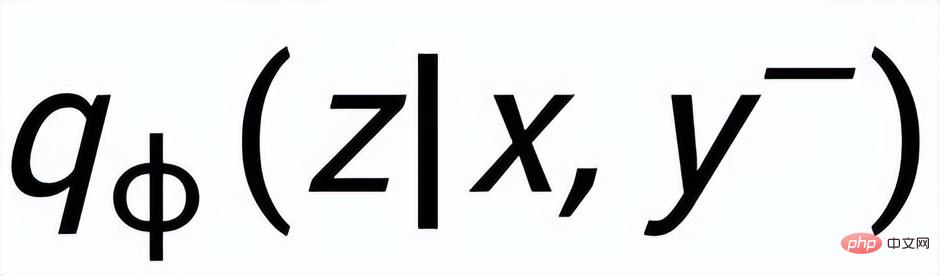
## are respectively recorded as
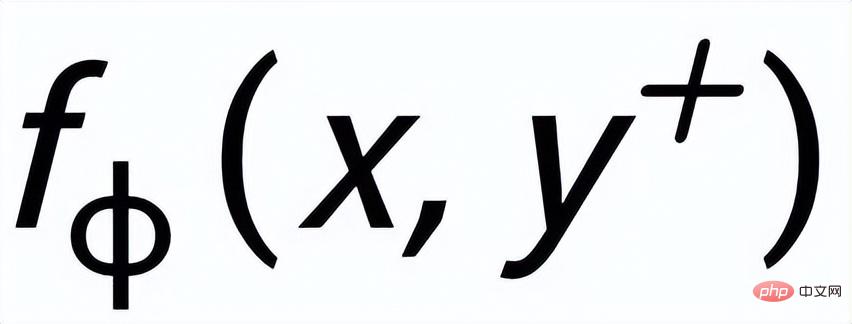
and
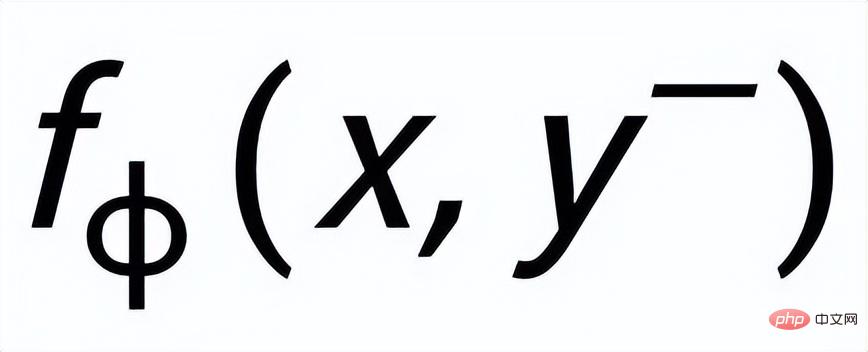
. The goal of sentence granular comparative learning is to reduce the distance between the prior distribution and the positive posterior distribution as much as possible, and at the same time, maximize the distance between the prior distribution and the negative posterior distribution. The corresponding loss function is as follows:
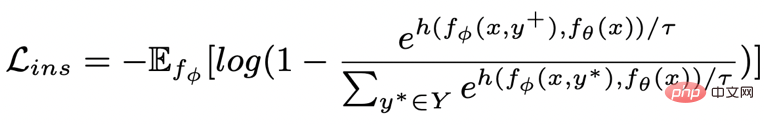
where is a positive sample or a negative sample and is the temperature coefficient, which is used to represent the distance metric. Here we use KL divergence (Kullback–Leibler divergence )[5] to measure the direct distance between two distributions.
Contrastive learning of keyword granularity is used to make the model pay more attention to the key information in the sentence. We use the input The positive and negative relationships corresponding to the output text are constructed to build a keyword graph to achieve this goal. Specifically, according to a given sentence pair

, we can respectively determine a keyword ## from it

#and

(I use the classic TextRank algorithm [6] for keyword extraction); for a sentence


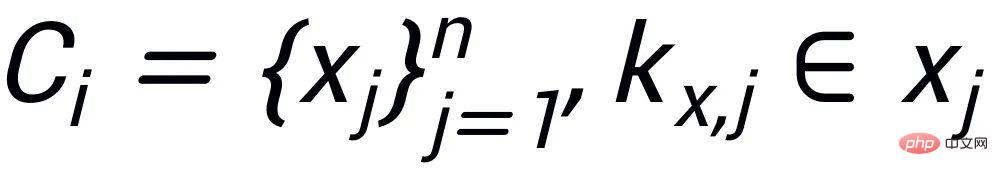
 ##There is a pair of positive and negative example output sentences
##There is a pair of positive and negative example output sentences
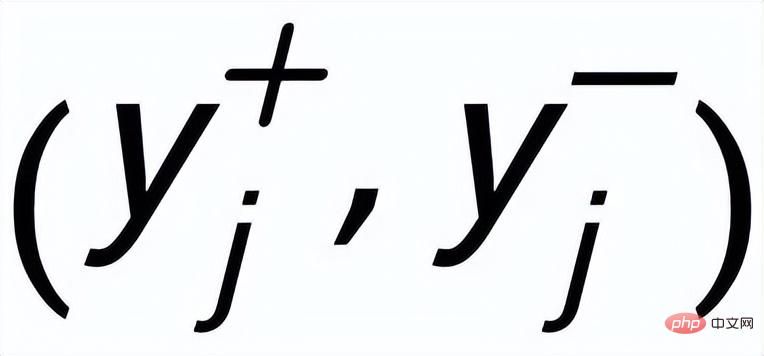 , and they each have a positive example keyword
, and they each have a positive example keyword
and negative example keywords
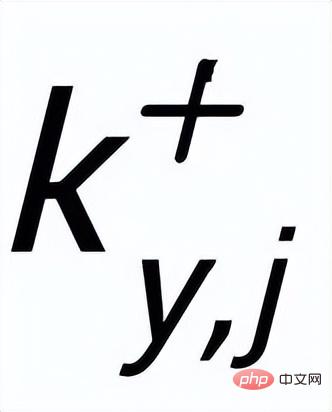
##. In this way, in the entire collection, for any output sentence

, it can be considered as the corresponding keyword

and every surrounding
 ## There is a positive edge between
## There is a positive edge between
# (associated through positive and negative relationships between sentences)
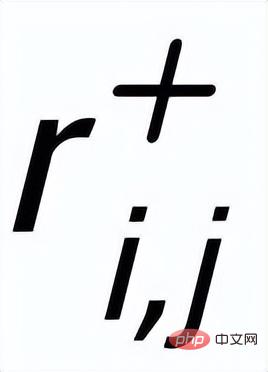
, there is a negative edge ## between each surrounding




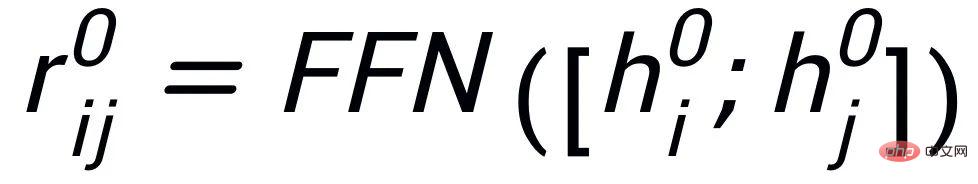
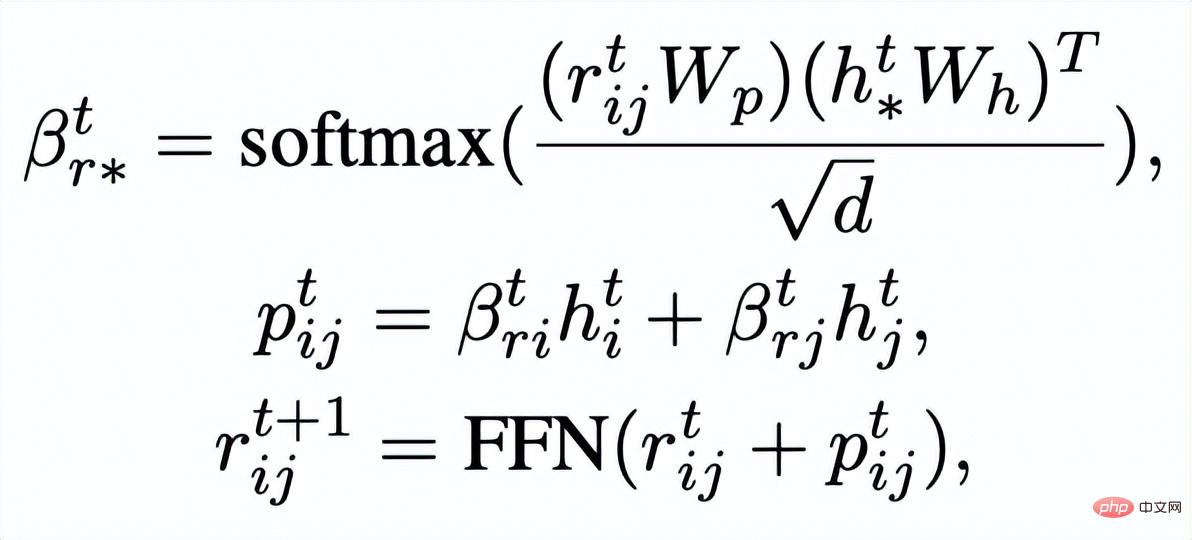
 ## can be
## can be
 or
or
 .
.
Then based on the updated edge
, we update the representation of each node through a graph attention layer: Here ## are all learnable parameters, is the attention weight. In order to prevent the gradient disappearance problem, we added a residual connection to to get the express . We use the node representation of the last iteration as the representation of the keyword, denoted as u. The comparison of keyword granularity comes from the keywords of the input sentence and an impostor node . We record the keywords extracted from the output positive samples of the input sentences as , which is in the above keyword network The negative neighbor node is recorded as , then , the comparative learning loss of keyword granularity is calculated as follows: ## Here is used to refer to or , h(·) is used to represent the distance measure. In the comparative learning of keyword granularity, we choose cosine similarity to calculate the distance between two points. ## It can be noted that the contrast learning of the above sentence granularity and keyword granularity is implemented on distribution and point respectively, so that the independent comparison of the two granularities may weaken the enhancement effect due to the small difference. In this regard, we construct comparative associations between different granularities based on the Mahalanobis distance [8] between points and distributions, so that the distance between the target output keyword and the sentence distribution is as small as possible, so that the distance between the imposter and the distribution is as small as possible. It makes up for the defect that the contrast may disappear due to the independent comparison of each particle size. Specifically, cross-granularity Mahalanobis distance contrastive learning hopes to narrow the posterior semantic distribution of sentences as much as possible and while increasing the distance between it and ## as much as possible The distance between #, the loss function is as follows: Here is also used to refer to or Experiment & Analysis
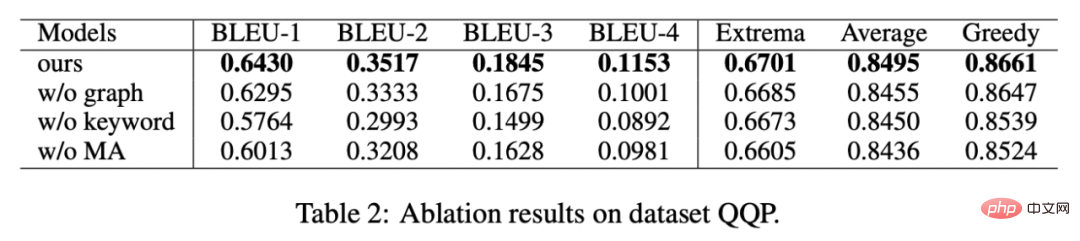
We conducted analysis on whether to use keywords, whether to use keyword network, and whether to use Mahalanobis distance comparison distribution. The ablation analysis experiment was conducted, and the results showed that these three designs did play an important role in the final result. The experimental results are shown in the figure below. In order to study different Regarding the role of hierarchical contrastive learning, we visualized the randomly sampled cases and obtained the following figure after dimensionality reduction through t-sne [22]. It can be seen from the figure that the representation of the input sentence is close to the extracted keyword representation, which shows that keywords, as the most important information in the sentence, usually determine the position of the semantic distribution. Moreover, in contrastive learning, we can see that after training, the distribution of input sentences is closer to positive samples and farther away from negative samples, which shows that contrastive learning can help correct the semantic distribution. Finally, we explore the impact of sampling different keywords. As shown in the table below, for an input question, we provide keywords as conditions for controlling semantic distribution through TextRank extraction and random selection methods respectively, and check the quality of the generated text. Keywords are the most important information unit in a sentence. Different keywords will lead to different semantic distributions and produce different tests. The more keywords selected, the more accurate the sentences generated. Meanwhile, the results generated by other models are also shown in the table below. This article In we propose a cross-granularity hierarchical contrastive learning mechanism that outperforms competitive baseline work on multiple text-generated datasets. The query rewriting model based on this work was successfully implemented in the actual business scenario of Alipay search and achieved remarkable results. The services in Alipay's search cover a wide range of areas and have significant domain characteristics. There is a huge literal difference between the user's search query expression and the service expression, which makes it difficult to achieve the desired effect by matching directly based on keywords (for example, the user enters the query "newly launched car query"). ", unable to recall the service "new car launch query"), the goal of query rewriting is to rewrite the query entered by the user into a way that is closer to the service expression while keeping the query intention unchanged, so as to better match the target service. Here are some rewording examples: 
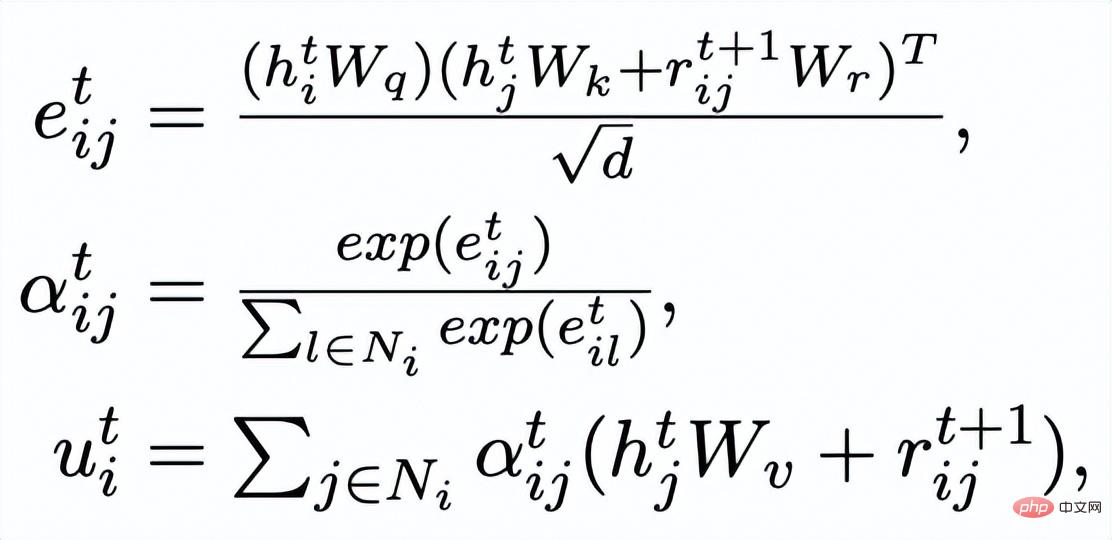
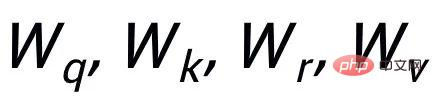







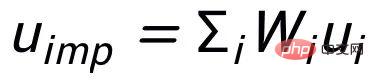
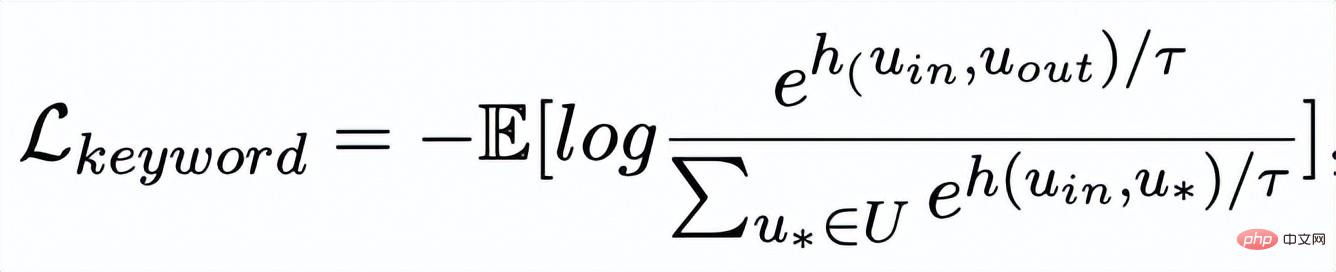


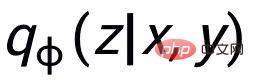


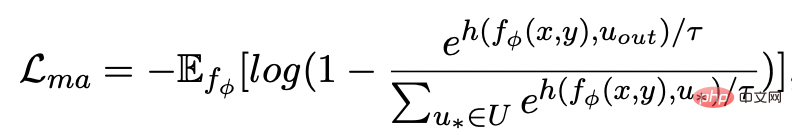



##Experimental Results
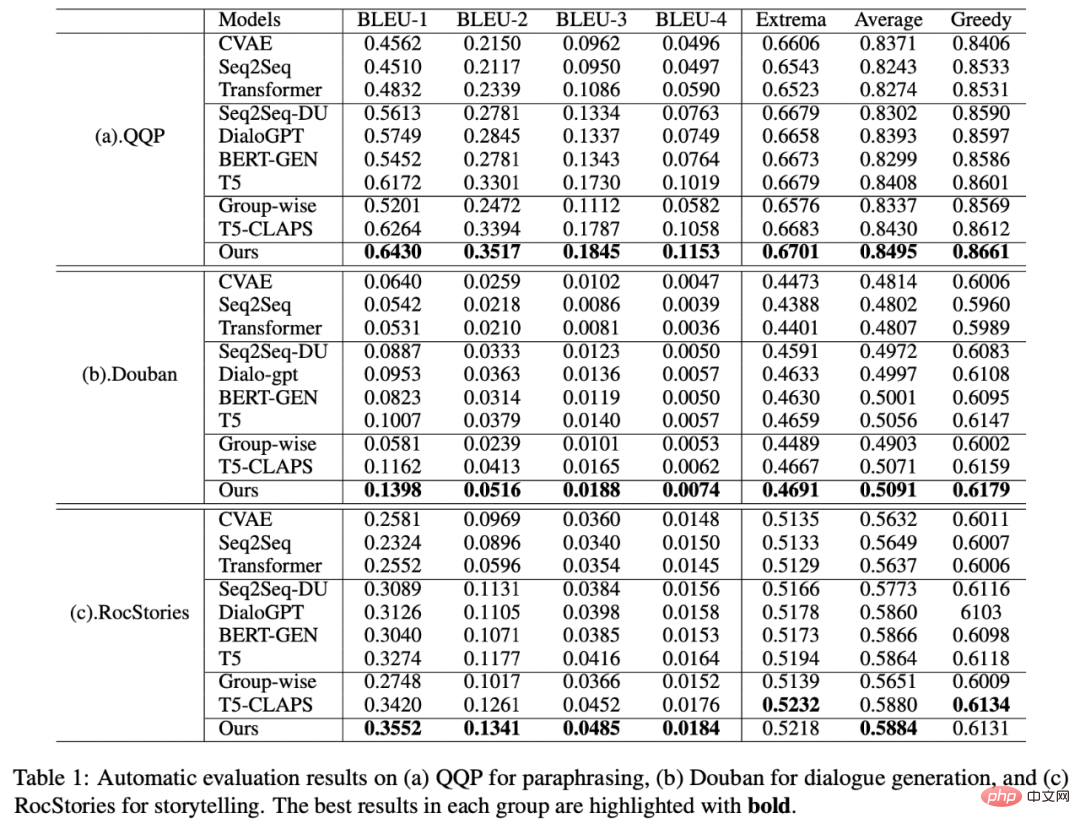
We conducted experiments on three public datasets Douban (Dialogue) [9], QQP (Paraphrasing) [10][11] and RocStories (Storytelling) [12], and all achieved SOTA effect. The baselines we compare include traditional generative models (e.g. CVAE[13], Seq2Seq[14], Transformer[15]), methods based on pre-trained models (e.g. Seq2Seq-DU[16], DialoGPT[17], BERT-GEN [7], T5[18]) and methods based on contrastive learning (e.g. Group-wise[9], T5-CLAPS[19]). We calculate the BLEU score[20] and the BOW embedding distance (extrema/average/greedy)[21] between sentence pairs as automated evaluation indicators. The results are shown in the following figure:
 We also used manual evaluation on the QQP data set. Three annotators produced results for T5-CLAPS, DialoGPT, Seq2Seq-DU and our model respectively. The results are marked, and the results are as shown below:
We also used manual evaluation on the QQP data set. Three annotators produced results for T5-CLAPS, DialoGPT, Seq2Seq-DU and our model respectively. The results are marked, and the results are as shown below: Ablation analysis
Visual analysis
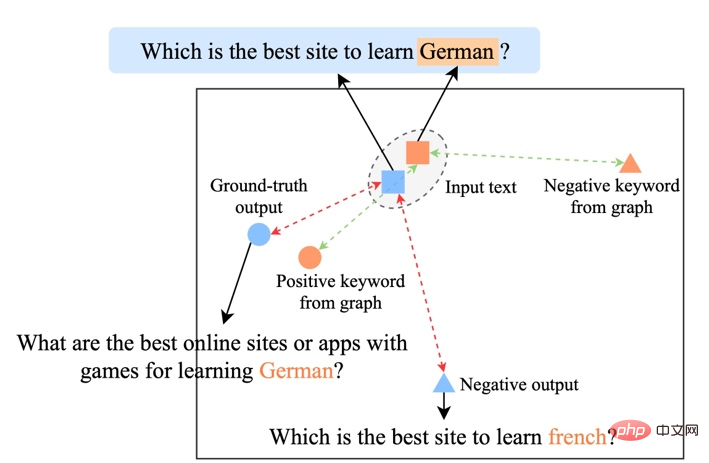
Keyword Importance Analysis

##Business Application
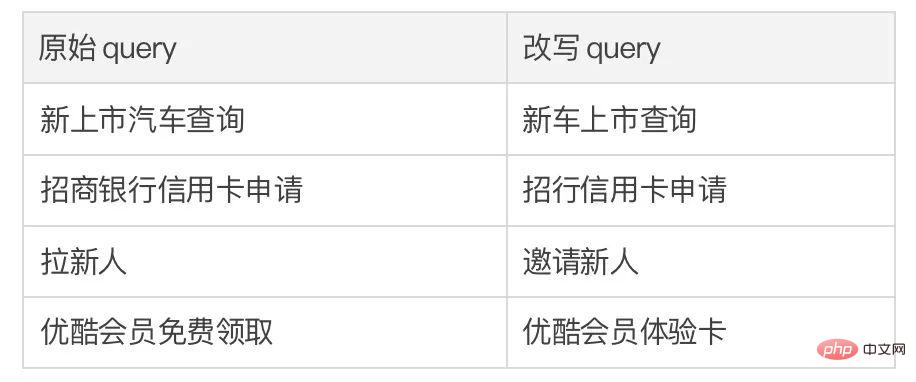 #
#
The above is the detailed content of To improve Alipay search experience, Ant and Peking University use hierarchical comparative learning text generation framework. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



