

Self-service machine learning based on smart databases


Translator|Zhang Yi
Revised|Liang Ce Sun Shujuan
1. How to become an IDO?
IDO(insight -driven organization) refers to an insight-driven (information-oriented) organization. To become an IDO, you first need data and the tools to operate and analyze the data; secondly, a data analyst or data scientist with appropriate experience; and finally, you need to find a technology or method to implement insight-driven decision-making processes throughout the company. .
Machine learning is a technology that can maximize the advantages of data. The ML process first uses data to train a prediction model, and then solves data-related problems after the training is successful. Among them, artificial neural networks are the most effective technology, and their design is derived from our current understanding of how the human brain works. Given the vast computing resources people currently have at their disposal, it can produce incredible models trained on massive amounts of data.
Businesses can use a variety of self-service software and scripts to complete different tasks to avoid human error. Likewise, you can make decisions based on data to avoid human error.
2. Why are companies slow to adopt artificial intelligence?
Only a minority of companies use artificial intelligence or machine learning to process data. The US Census Bureau said that as of 2020, less than 10% of US businesses had adopted machine learning (mostly large companies).
Barriers to ML adoption include:
- There is still a lot of work to be done before artificial intelligence can replace humans. The first is that many companies lack and cannot afford professionals. Data scientists are highly regarded in this field, but they are also the most expensive to hire.
- Lack of available data, data security, and time-consuming ML algorithm implementation.
- It is difficult for companies to create an environment where data and its advantages can be realized. This environment requires relevant tools, processes and strategies.
3. Only automatic ML (AutoML) tools are not enough for the promotion of machine learning
Although the automatic ML platform has a bright future, its coverage is currently quite limited. There is also debate over whether automated ML will soon replace data scientists.
If you want to successfully deploy self-service machine learning in your company, AutoML tools are indeed crucial, but processes, methods, and strategies must also be paid attention to. AutoML platforms are just tools, and most ML experts believe this is not enough.
4. Break down the machine learning process

Any ML process starts with data. It is generally accepted that data preparation is the most important aspect of the ML process, and the modeling part is only one part of the overall data pipeline, while being simplified through AutoML tools. The complete workflow still requires a lot of work to transform the data and feed it to the model. Data preparation and data transformation can be some of the most time-consuming and unpleasant parts of the job.
In addition, the business data used to train ML models will also be updated regularly. Therefore, it requires enterprises to build complex ETL pipelines that can master complex tools and processes, so ensuring the continuity and real-time nature of the ML process is also a challenging task.
5. Integrate ML with Applications
Assume now that we have built the ML model and then need to deploy it. The classic deployment approach treats it as an application layer component, as shown below:
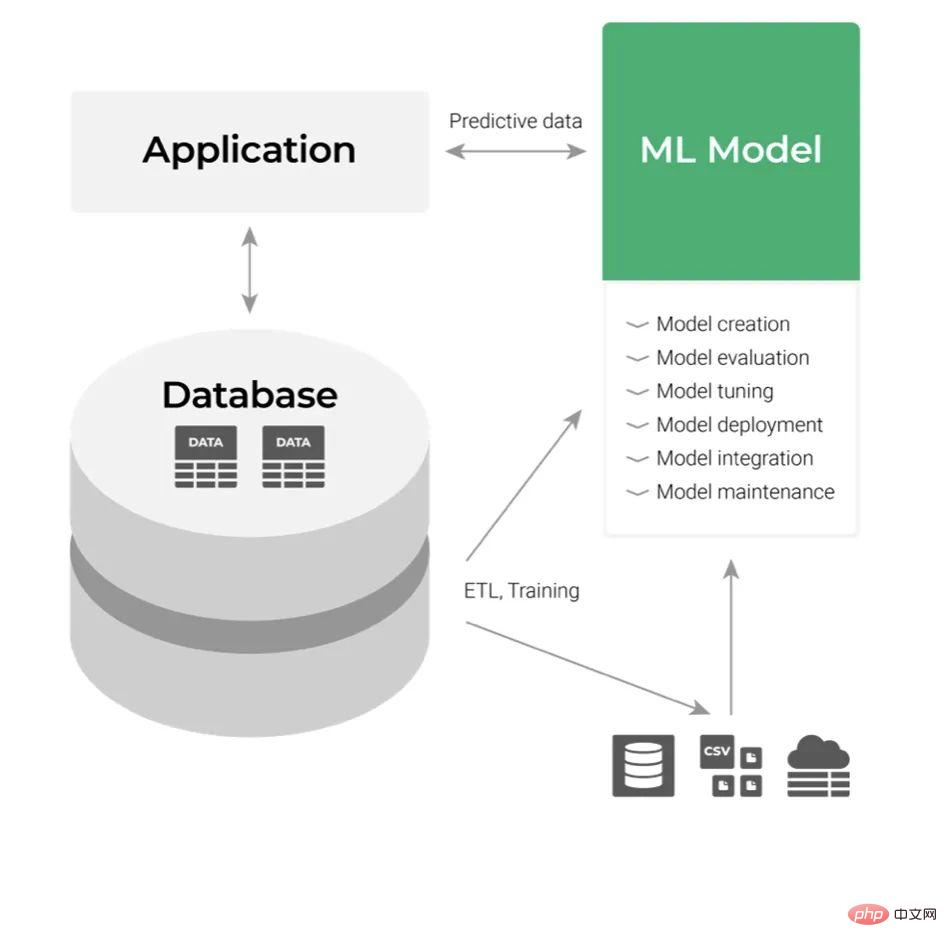
Its input is the data and its output is the prediction we get. Consume the output of ML models by integrating the APIs of these applications. This all seems easy just from a developer perspective, but not when you think about the process. In a large organization, any integration and maintenance with business applications can be quite cumbersome. Even if the company is tech-savvy, any request for code changes must go through a specific review and testing process across multiple levels of departments. This negatively affects flexibility and increases the complexity of the overall workflow.
If there is enough flexibility in testing various concepts and ideas, ML-based decision-making will be much easier, so people will prefer products with self-service capabilities.
6. Self-service machine learning/intelligent database?
As we saw above, data is the core of the ML process, existing ML tools take the data and return predictions, and these predictions It is also the form of data.
Now comes the question:
- Why do we want to treat ML as a standalone application and implement complex integration between ML models, applications and databases?
- Why not make ML a core feature of the database?
- Why not make ML models available through standard database syntax (such as SQL)?
Let’s Analyze the above problems and their challenges to find ML solutions.
Challenge #1: Complex Data Integration and ETL Pipelines
Maintaining complex data integration and ETL pipelines between ML models and databases is one of the biggest challenges facing ML processes.
SQL is an excellent data manipulation tool, so we can solve this problem by introducing ML models into the data layer. In other words, the ML model will learn in the database and return predictions.
Challenge #2: Integration of ML Models with Applications
Integrating ML models with business applications through APIs is another challenge faced.
Business applications and BI tools are tightly coupled with the database. Therefore, if the AutoML tool becomes part of the database, we can use standard SQL syntax to make predictions. Next, API integration between ML models and business applications is no longer required because the models reside in the database.
Solution: Embed AutoML in the database
Embedding AutoML tools in the database will bring many benefits, such as:
- Anyone who works with data and understands SQL Anyone (data analyst or data scientist) can harness the power of machine learning.
- Software developers can embed ML into business tools and applications more efficiently.
- No complex integration is required between data and models, and between models and business applications.
In this way, the above relatively complex integration diagram changes as follows:
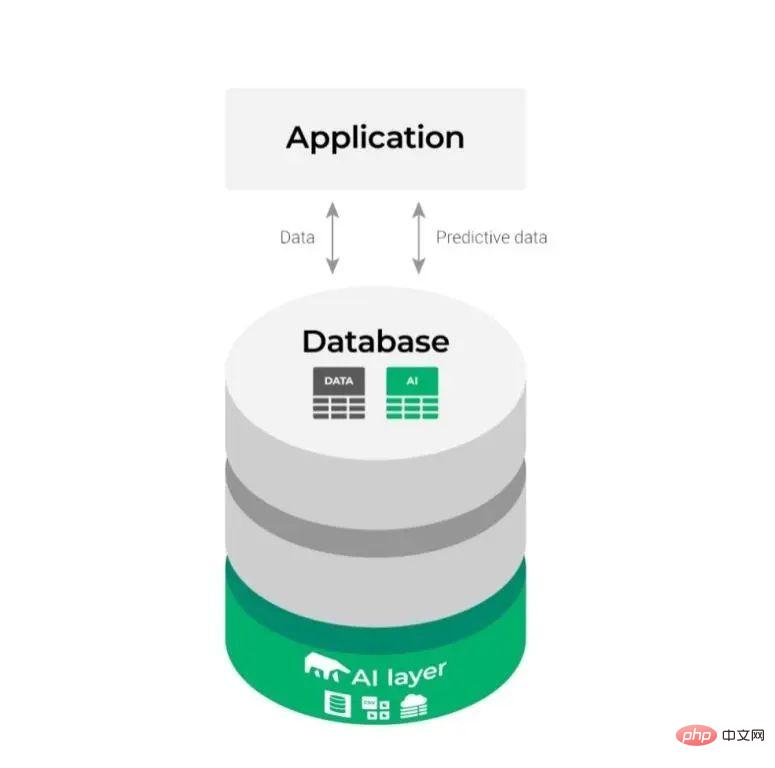
It looks simpler and makes the ML process smoother and more efficient. .
7. How to implement self-service ML using models as virtual database tables
The next step in finding the solution is to implement it.
To do this, we use a structure called AI Tables. It brings machine learning to the data platform in the form of virtual tables. It can be created like any other database table and then exposed to applications, BI tools and DB clients. We make predictions by simply querying the data.
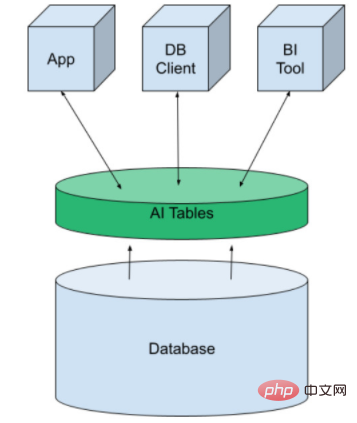
AI Tables was originally developed by MindsDB and is available as an open source or managed cloud service. They integrate traditional SQL and NoSQL databases such as Kafka and Redis.
8. Using AI Tables
The concept of AI Tables enables us to perform the ML process in the database so that all steps of the ML process (i.e. data preparation, model training and prediction) can be database.
- Training AI Tables
First, users must create an AI Table according to their own needs, which is similar to a machine learning model and includes columns from the source table, etc. features; and then complete the remaining modeling tasks by itself through the AutoML engine. Examples will be given later.
- Make predictions
Once the AI Table is created, it is ready for use without any further deployment. To make predictions, just run a standard SQL query on the AI Table.
You can make predictions one by one or in batches. AI Tables can handle many complex machine learning tasks, such as multivariate time series, detecting anomalies, etc.
9.AI Tables Working Example
For retailers, ensuring that products are in stock at the right time is a complex task. When demand increases, supply increases. Based on this data and machine learning, we can predict how much stock a given product should have on a given day, resulting in more revenue for retailers.
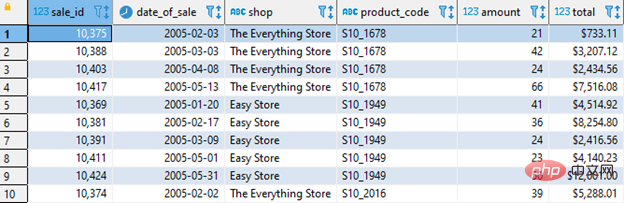
First you need to track the following information and create an AI Table:
- Product sold date (date_of_sale)
- Product sold store (shop)
- Specific products sold (product_code)
- Quantity of products sold (amount)
As shown below:
(1) Training AI Tables
To create and train AI Tables, you must first allow MindsDB to access the data. For detailed instructions, please refer to the MindsDB documentation.
AI Tables are like ML models and require historical data to train them.
The following uses a simple SQL command to train an AITable:

Let us analyze this query:
- Use MindsDB CREATE PREDICTOR statement in .
- Define the source database based on historical data.
- Train the AI Table based on the historical data table (historical_table), and the selected columns (column_1 and column_2) are features used for prediction.
- AutoML automatically completes the remaining modeling tasks.
- MindsDB will identify the data type of each column, normalize and encode it, and build and train the ML model.
At the same time, you can see the overall accuracy and confidence of each prediction and estimate which columns (features) are more important to the result.
In databases, we often need to process tasks involving multivariate time series data with high cardinality. Using traditional methods, considerable effort is required to create such ML models. We need to group the data and sort it based on a given time, date or timestamp data field.
For example, we predict the number of hammers sold in a hardware store. Well, the data is grouped by store and product, and predictions are made for each different store and product combination. This brings us to the problem of creating a time series model for each group.
This sounds like a huge project, but MindsDB provides a method to create a single ML model using the GROUP BY statement to train multivariate time series data at once. Let’s see how it’s done using just one SQL command:

The stock_forecaster predictor is created to predict how many items a particular store will sell in the future. The data is sorted by sales date and grouped by store. So we can predict the sales amount for each store.
(2) Batch prediction
By using the following query to connect the sales data table with the predictor, the JOIN operation adds the predicted quantity to the record, so we can get many at once Recorded batch predictions.

To learn more about analyzing and visualizing predictions in BI tools, check out this article.
(3) Practical Application
The traditional approach treats ML models as independent applications, requiring maintenance of ETL pipelines to the database and API integration to business applications. Although AutoML tools make the modeling part easy and straightforward, the complete ML workflow still requires experienced experts to manage. In fact, the database is already the preferred tool for data preparation, so it makes more sense to introduce ML into the database rather than introducing data into ML. Because AutoML tools reside in the database, the AI Tables construct from MindsDB provides data practitioners with self-service AutoML and streamlines machine learning workflows.
Original link: https://dzone.com/articles/self-service-machine-learning-with-intelligent-dat
Translator’s introduction
Zhang Yi, 51CTO community editor, intermediate engineer. Mainly researches the implementation of artificial intelligence algorithms and scenario applications, has an understanding and mastery of machine learning algorithms and automatic control algorithms, and will continue to pay attention to the development trends of artificial intelligence technology at home and abroad, especially the application of artificial intelligence technology in intelligent connected cars and smart homes. Specific implementation and applications in other fields.

The above is the detailed content of Self-service machine learning based on smart databases. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Translator | Reviewed by Li Rui | Chonglou Artificial intelligence (AI) and machine learning (ML) models are becoming increasingly complex today, and the output produced by these models is a black box – unable to be explained to stakeholders. Explainable AI (XAI) aims to solve this problem by enabling stakeholders to understand how these models work, ensuring they understand how these models actually make decisions, and ensuring transparency in AI systems, Trust and accountability to address this issue. This article explores various explainable artificial intelligence (XAI) techniques to illustrate their underlying principles. Several reasons why explainable AI is crucial Trust and transparency: For AI systems to be widely accepted and trusted, users need to understand how decisions are made
 iOS 18 adds a new 'Recovered' album function to retrieve lost or damaged photos
Jul 18, 2024 am 05:48 AM
iOS 18 adds a new 'Recovered' album function to retrieve lost or damaged photos
Jul 18, 2024 am 05:48 AM
Apple's latest releases of iOS18, iPadOS18 and macOS Sequoia systems have added an important feature to the Photos application, designed to help users easily recover photos and videos lost or damaged due to various reasons. The new feature introduces an album called "Recovered" in the Tools section of the Photos app that will automatically appear when a user has pictures or videos on their device that are not part of their photo library. The emergence of the "Recovered" album provides a solution for photos and videos lost due to database corruption, the camera application not saving to the photo library correctly, or a third-party application managing the photo library. Users only need a few simple steps
 Machine Learning in C++: A Guide to Implementing Common Machine Learning Algorithms in C++
Jun 03, 2024 pm 07:33 PM
Machine Learning in C++: A Guide to Implementing Common Machine Learning Algorithms in C++
Jun 03, 2024 pm 07:33 PM
In C++, the implementation of machine learning algorithms includes: Linear regression: used to predict continuous variables. The steps include loading data, calculating weights and biases, updating parameters and prediction. Logistic regression: used to predict discrete variables. The process is similar to linear regression, but uses the sigmoid function for prediction. Support Vector Machine: A powerful classification and regression algorithm that involves computing support vectors and predicting labels.
 Detailed tutorial on establishing a database connection using MySQLi in PHP
Jun 04, 2024 pm 01:42 PM
Detailed tutorial on establishing a database connection using MySQLi in PHP
Jun 04, 2024 pm 01:42 PM
How to use MySQLi to establish a database connection in PHP: Include MySQLi extension (require_once) Create connection function (functionconnect_to_db) Call connection function ($conn=connect_to_db()) Execute query ($result=$conn->query()) Close connection ( $conn->close())
 How to handle database connection errors in PHP
Jun 05, 2024 pm 02:16 PM
How to handle database connection errors in PHP
Jun 05, 2024 pm 02:16 PM
To handle database connection errors in PHP, you can use the following steps: Use mysqli_connect_errno() to obtain the error code. Use mysqli_connect_error() to get the error message. By capturing and logging these error messages, database connection issues can be easily identified and resolved, ensuring the smooth running of your application.
 Golang Machine Learning Applications: Building Intelligent Algorithms and Data-Driven Solutions
Jun 02, 2024 pm 06:46 PM
Golang Machine Learning Applications: Building Intelligent Algorithms and Data-Driven Solutions
Jun 02, 2024 pm 06:46 PM
Use machine learning in Golang to develop intelligent algorithms and data-driven solutions: Install the Gonum library for machine learning algorithms and utilities. Linear regression using Gonum's LinearRegression model, a supervised learning algorithm. Train the model using training data, which contains input variables and target variables. Predict house prices based on new features, from which the model will extract a linear relationship.
