
 Technology peripherals
AI
ICRA 2022 Outstanding Paper: Converting 2D images of autonomous driving into a bird's-eye view, the model recognition accuracy increases by 15%
Technology peripherals
AI
ICRA 2022 Outstanding Paper: Converting 2D images of autonomous driving into a bird's-eye view, the model recognition accuracy increases by 15%
ICRA 2022 Outstanding Paper: Converting 2D images of autonomous driving into a bird's-eye view, the model recognition accuracy increases by 15%

For many tasks in autonomous driving, it is easier to complete from a top-down, map or bird's eye view (BEV) perspective. Since many autonomous driving topics are restricted to the ground plane, a top view is a more practical low-dimensional representation and is ideal for navigation, capturing relevant obstacles and hazards. For scenarios like autonomous driving, semantically segmented BEV maps must be generated as instantaneous estimates to handle freely moving objects and scenes that are visited only once.
To infer BEV maps from images, one needs to determine the correspondence between image elements and their positions in the environment. Some previous research used dense depth maps and image segmentation maps to guide this conversion process, and other research extended the method of implicitly parsing depth and semantics. Some studies exploit camera geometric priors but do not explicitly learn the interaction between image elements and BEV planes.
In a recent paper, researchers from the University of Surrey introduced an attention mechanism to convert 2D images of autonomous driving into a bird's-eye view, improving the model's recognition accuracy. 15%. This research won the Outstanding Paper Award at the ICRA 2022 conference that concluded not long ago.

##Paper link: https://arxiv.org/pdf/2110.00966.pdf

Different from previous methods, this study treats BEV conversion as an "Image-to-World" conversion problem, whose goal is to learn the alignment between vertical scan lines in the image and polar rays in the BEV. Therefore, this projective geometry is implicit to the network.
In the alignment model, the researchers adopted Transformer, an attention-based sequence prediction structure. Leveraging their attention mechanism, we explicitly model the pairwise interaction between vertical scan lines in an image and their polar BEV projections. Transformers are well suited for image-to-BEV translation problems because they can reason about the interdependencies between objects, depth, and scene lighting to achieve globally consistent representations.
The researchers embed the Transformer-based alignment model into an end-to-end learning formula that takes the monocular image and its intrinsic matrix as input, and then Predict semantic BEV mapping of static and dynamic classes.
This paper builds an architecture that helps predict semantic BEV mapping from monocular images around an alignment model. As shown in Figure 1 below, it contains three main components: a standard CNN backbone to extract spatial features on the image plane; an encoder-decoder Transformer to convert the features on the image plane into BEV; and finally a segmentation network Decode BEV features into semantic maps.
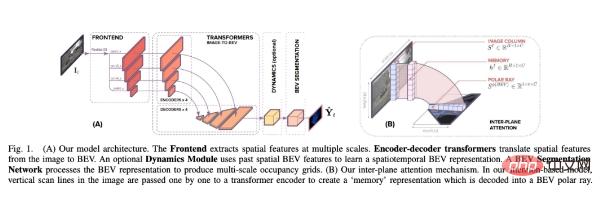

Specifically, the main contributions of this study are:
- (1) Use a set of 1D sequence-sequence conversion to generate a BEV map from an image;
- (2) Construct a subject Limited data efficient Transformer network with spatial awareness;
- #(3) The combination of formula and monotonic attention in the language field shows that for accurate mapping, knowing a What is below the point is more important than knowing what is above it, although using both will result in the best performance;
- (4) shows how axial attention can help by providing temporal awareness to improve performance and present state-of-the-art results on three large-scale datasets.
Experimental results
In the experiment, the researchers made several evaluations: Image to BEV conversion was evaluated as a conversion problem on the nuScenes dataset Its utility; ablating backtracking directions in monotonic attention, assessing the utility of long sequence horizontal context and the impact of polar positional information. Finally, the method is compared with SOTA methods on nuScenes, Argoverse, and Lyft datasets.
Ablation experiment
As shown in the first part of Table 2 below, the researchers compared soft attention (looking both ways), monotonic attention looking back at the bottom of the image (looking down), monotonic attention looking back at the top of the image (looking up). The results show that looking down from a point in the image is better than looking up.
Along local texture clues - This is consistent with the way humans try to determine the distance of objects in urban environments, we will use the object and the ground plane intersection location. The results also show that observation in both directions further improves accuracy, making deep inference more discriminative.

The utility of long sequence horizontal context. The image-to-BEV conversion here is done as a set of 1D sequence-to-sequence conversions, so one question is what happens when the entire image is converted to BEV. Considering the secondary computation time and memory required to generate attention maps, this approach is prohibitively expensive. However, the contextual benefits of using the entire image can be approximated by applying horizontal axial attention on image plane features. With axial attention through the image lines, pixels in vertical scan lines now have long-range horizontal context, and then long-range vertical context is provided by transitioning between 1D sequences as before.
As shown in the middle part of Table 2, merging long sequence horizontal context does not benefit the model, and even has a slight adverse effect. This illustrates two points: first, each transformed ray does not require information about the entire width of the input image, or rather, the long sequence context does not provide any additional information compared to the context already aggregated by the front-end convolution. benefit. This shows that using the entire image to perform the transformation will not improve the model accuracy beyond the baseline constraint formula; in addition, the performance degradation caused by the introduction of horizontal axial attention means the difficulty of using attention to train sequences of image width, as can be seen, It will be more difficult to train using the entire image as the input sequence.
Polar-agnostic vs polar-adaptive Transformers: The last part of Table 2 compares Po-Ag vs. Po -Variations of Ad. A Po-Ag model has no polarization position information, the Po-Ad of the image plane includes polar encodings added to the Transformer encoder, and for the BEV plane, this information is added to the decoder. Adding polar encodings to either plane is more beneficial than adding it to the agnostic model, with the dynamic class adding the most. Adding it to both planes further enforces this, but has the greatest impact on static classes.
Comparison with SOTA methods
The researcher compared the method in this article with some SOTA methods. As shown in Table 1 below, the performance of the spatial model is better than the current compressed SOTA method STA-S, with an average relative improvement of 15%. On the smaller dynamic classes, the improvement is even more significant, with bus, truck, trailer, and obstacle detection accuracy all increasing by a relative 35-45%.

The qualitative results obtained in Figure 2 below also support this conclusion. The model in this article shows greater structural similarity and better shape sense. This difference can be partly attributed to the fully connected layers (FCL) used for compression: when detecting small and distant objects, much of the image is redundant context.

#In addition, pedestrians and other objects are often partially blocked by vehicles. In this case, the fully connected layer will tend to ignore pedestrians and instead maintain the semantics of vehicles. Here, the attention method shows its advantage because each radial depth can be independently noticed in the image - so that deeper depths can make the bodies of pedestrians visible, while previous depths can only notice vehicles.
The results on the Argoverse dataset in Table 3 below show a similar pattern, in which our method improves by 30% compared to PON [8].

As shown in Table 4 below, the performance of this method on nuScenes and Lyft is better than LSS [9] and FIERY [20]. A true comparison is impossible on Lyft because it doesn't have a canonical train/val split, and there's no way to get the split used by LSS.

For more research details, please refer to the original paper.
The above is the detailed content of ICRA 2022 Outstanding Paper: Converting 2D images of autonomous driving into a bird's-eye view, the model recognition accuracy increases by 15%. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
