
 Technology peripherals
AI
Built from scratch, DeepMind's new paper explains Transformer in detail with pseudocode
Technology peripherals
AI
Built from scratch, DeepMind's new paper explains Transformer in detail with pseudocode
Built from scratch, DeepMind's new paper explains Transformer in detail with pseudocode

Transformer was born in 2017 and was introduced by Google in the paper "Attention is all you need". This paper abandons the CNN and RNN used in previous deep learning tasks. This groundbreaking research overturned the previous idea of equating sequence modeling and RNN, and is now widely used in NLP. The popular GPT, BERT, etc. are all built on Transformer.
Transformer Since its introduction, researchers have proposed many variations. But everyone's descriptions of Transformer seem to introduce the architecture in verbal form, graphical explanations, etc. There is very little information available for pseudocode descriptions of Transformer.
As expressed in the following passage: A very famous researcher in the field of AI once sent a well-known complexity theorist an article that he thought was very well written. Good paper. And the theorist's answer is: I can't find any theorem in the paper, I don't know what the paper is about.
A paper may be detailed enough for a practitioner, but the precision required by a theorist is usually greater. For some reason, the DL community seems reluctant to provide pseudocode for their neural network models.
Currently it appears that the DL community has the following problems:
DL publications lack scientific accuracy and detail. Deep learning has achieved huge success over the past 5 to 10 years, with thousands of papers published every year. Many researchers only informally describe how they modified previous models, with papers of over 100 pages containing only a few lines of informal model descriptions. At best, some high-level diagrams, no pseudocode, no equations, no mention of a precise interpretation of the model. No one even provides pseudocode for the famous Transformer and its encoder/decoder variants.
Source code and pseudo code. Open source source code is very useful, but compared to the thousands of lines of real source code, well-designed pseudocode is usually less than a page and still essentially complete. It seemed like hard work that no one wanted to do.
Explaining the training process is equally important, but sometimes the paper doesn’t even mention what the inputs and outputs of the model are and what the potential side effects are. Experimental sections in papers often do not explain what is fed into the algorithm and how. If the Methods section has some explanations, it is often disconnected from what is described in the Experimental section, probably because different authors wrote different sections.
Some people may ask: Is pseudocode really needed? What is the use of pseudocode?
Researchers from DeepMind believe that providing pseudocode has many uses. Compared with reading an article or scrolling through 1000 lines of actual code, pseudocode condenses all the important content on one page. , making it easier to develop new variants. To this end, they recently published a paper "Formal Algorithms for Transformers", which describes the Transformer architecture in a complete and mathematically accurate way.
Introduction to the paper
This article covers what Transformer is, how Transformer is trained, what Transformer is used for, the key architectural components of Transformer, and a preview of the more famous models.

##Paper address: https://arxiv.org/pdf/2207.09238.pdf
However, to read this article, readers need to be familiar with basic ML terminology and simple neural network architectures (such as MLPs). For readers, after understanding the content in the article, they will have a solid grasp of Transformer, and may use pseudocode to implement their own Transformer variants.
The main part of this paper is Chapter 3-8, which introduces Transformer and its typical tasks, tokenization, Transformer's architectural composition, Transformer training and inference, and practical applications.

The basically complete pseudocode in the paper is about 50 lines long, while the actual real source code is thousands of lines long. The pseudocode describing the algorithm in the paper is suitable for theoretical researchers who need compact, complete and accurate formulas, experimental researchers who implement Transformer from scratch, and is also useful for extending papers or textbooks using the formal Transformer algorithm.

Pseudocode examples in the paper
For those who are familiar with basic ML terminology and simple neural network architecture For beginners (such as MLP), this paper will help you master a solid Transformer foundation and use pseudocode templates to implement your own Transformer model.
Introduction to the author
The first author of this paper is Mary Phuong, a researcher who officially joined DeepMind in March this year. She graduated with a PhD from the Austrian Institute of Science and Technology, mainly engaged in theoretical research on machine learning.

Another author of the paper is Marcus Hutter, a senior researcher at DeepMind and also an Australian Emeritus Professor, Research Institute of Computer Science (RSCS), National University (ANU).

Marcus Hutter has been engaged in research on the mathematical theory of artificial intelligence for many years. This area of research is based on several mathematical and computational science concepts, including reinforcement learning, probability theory, algorithmic information theory, optimization, search, and computational theory. His book, General Artificial Intelligence: Sequential Decision-Making Based on Algorithmic Probability, was published in 2005 and is a very technical and mathematical book.
In 2002, Marcus Hutter, together with Jürgen Schmidhuber and Shane Legg, proposed the mathematical theory of artificial intelligence AIXI based on idealized agents and reward reinforcement learning. In 2009, Marcus Hutter proposed the feature reinforcement learning theory.
The above is the detailed content of Built from scratch, DeepMind's new paper explains Transformer in detail with pseudocode. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

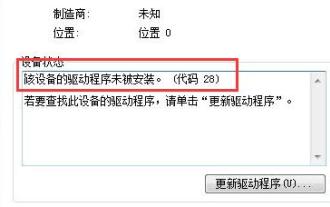 How to solve win7 driver code 28
Dec 30, 2023 pm 11:55 PM
How to solve win7 driver code 28
Dec 30, 2023 pm 11:55 PM
Some users encountered errors when installing the device, prompting error code 28. In fact, this is mainly due to the driver. We only need to solve the problem of win7 driver code 28. Let’s take a look at what should be done. Do it. What to do with win7 driver code 28: First, we need to click on the start menu in the lower left corner of the screen. Then, find and click the "Control Panel" option in the pop-up menu. This option is usually located at or near the bottom of the menu. After clicking, the system will automatically open the control panel interface. In the control panel, we can perform various system settings and management operations. This is the first step in the nostalgia cleaning level, I hope it helps. Then we need to proceed and enter the system and
 What to do if the blue screen code 0x0000001 occurs
Feb 23, 2024 am 08:09 AM
What to do if the blue screen code 0x0000001 occurs
Feb 23, 2024 am 08:09 AM
What to do with blue screen code 0x0000001? The blue screen error is a warning mechanism when there is a problem with the computer system or hardware. Code 0x0000001 usually indicates a hardware or driver failure. When users suddenly encounter a blue screen error while using their computer, they may feel panicked and at a loss. Fortunately, most blue screen errors can be troubleshooted and dealt with with a few simple steps. This article will introduce readers to some methods to solve the blue screen error code 0x0000001. First, when encountering a blue screen error, we can try to restart
 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 Solve the 'error: expected initializer before 'datatype'' problem in C++ code
Aug 25, 2023 pm 01:24 PM
Solve the 'error: expected initializer before 'datatype'' problem in C++ code
Aug 25, 2023 pm 01:24 PM
Solve the "error:expectedinitializerbefore'datatype'" problem in C++ code. In C++ programming, sometimes we encounter some compilation errors when writing code. One of the common errors is "error:expectedinitializerbefore'datatype'". This error usually occurs in a variable declaration or function definition and may cause the program to fail to compile correctly or
 The computer frequently blue screens and the code is different every time
Jan 06, 2024 pm 10:53 PM
The computer frequently blue screens and the code is different every time
Jan 06, 2024 pm 10:53 PM
The win10 system is a very excellent high-intelligence system. Its powerful intelligence can bring the best user experience to users. Under normal circumstances, users’ win10 system computers will not have any problems! However, it is inevitable that various faults will occur in excellent computers. Recently, friends have been reporting that their win10 systems have encountered frequent blue screens! Today, the editor will bring you solutions to different codes that cause frequent blue screens in Windows 10 computers. Let’s take a look. Solutions to frequent computer blue screens with different codes each time: causes of various fault codes and solution suggestions 1. Cause of 0×000000116 fault: It should be that the graphics card driver is incompatible. Solution: It is recommended to replace the original manufacturer's driver. 2,
 Resolve code 0xc000007b error
Feb 18, 2024 pm 07:34 PM
Resolve code 0xc000007b error
Feb 18, 2024 pm 07:34 PM
Termination Code 0xc000007b While using your computer, you sometimes encounter various problems and error codes. Among them, the termination code is the most disturbing, especially the termination code 0xc000007b. This code indicates that an application cannot start properly, causing inconvenience to the user. First, let’s understand the meaning of termination code 0xc000007b. This code is a Windows operating system error code that usually occurs when a 32-bit application tries to run on a 64-bit operating system. It means it should
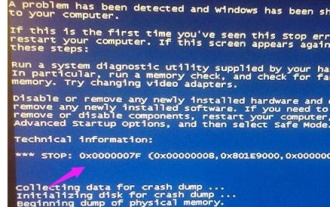 Detailed explanation of the causes and solutions of 0x0000007f blue screen code
Dec 25, 2023 pm 02:19 PM
Detailed explanation of the causes and solutions of 0x0000007f blue screen code
Dec 25, 2023 pm 02:19 PM
Blue screen is a problem we often encounter when using the system. Depending on the error code, there will be many different reasons and solutions. For example, when we encounter the problem of stop: 0x0000007f, it may be a hardware or software error. Let’s follow the editor to find out the solution. 0x000000c5 blue screen code reason: Answer: The memory, CPU, and graphics card are suddenly overclocked, or the software is running incorrectly. Solution 1: 1. Keep pressing F8 to enter when booting, select safe mode, and press Enter to enter. 2. After entering safe mode, press win+r to open the run window, enter cmd, and press Enter. 3. In the command prompt window, enter "chkdsk /f /r", press Enter, and then press the y key. 4.
 GE universal remote codes program on any device
Mar 02, 2024 pm 01:58 PM
GE universal remote codes program on any device
Mar 02, 2024 pm 01:58 PM
If you need to program any device remotely, this article will help you. We will share the top GE universal remote codes for programming any device. What is a GE remote control? GEUniversalRemote is a remote control that can be used to control multiple devices such as smart TVs, LG, Vizio, Sony, Blu-ray, DVD, DVR, Roku, AppleTV, streaming media players and more. GEUniversal remote controls come in various models with different features and functions. GEUniversalRemote can control up to four devices. Top Universal Remote Codes to Program on Any Device GE remotes come with a set of codes that allow them to work with different devices. you may
