

Guest | Huang Bin
Compilation | Tu Chengye
Recently, at the AISummit Global Artificial Intelligence Technology Conference hosted by 51CTO, Huang Bin, an expert in R&D of NetEase Cloud Music Algorithm Platform, gave a keynote speech "Practice and Thoughts on NetEase Cloud Music Online Prediction System" shares relevant practices and thoughts on how to build a high-performance, easy-to-use, and feature-rich prediction system from the perspective of technology research and development.
The content of the speech is now organized as follows, hoping to inspire you.
First, let’s take a look at the architecture of the entire estimation system, as shown in the figure below:
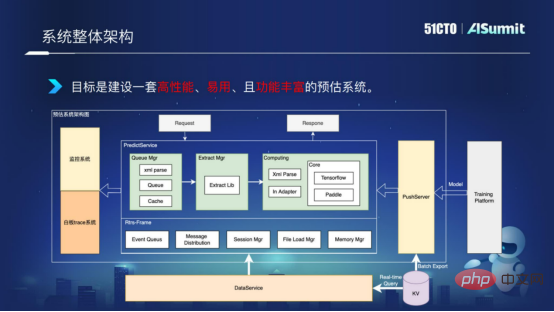
System The Predict Server in the middle of the overall architecture
is the core component of the prediction system, including query components, feature processing components, and model calculation components. The monitoring system on the left is used to monitor line network services to ensure the smooth flow of the system network. The PushServer on the right is used for model push, pushing the latest model into the online prediction system for prediction.
The goal is to build a high-performance, easy-to-use, and feature-rich forecasting system.
How to improve computing performance? What are our common computing performance problems? I will elaborate on them from three aspects.
In the general solution, our feature calculation and model calculation are deployed in separate processes, which will result in a large number of features existing across services and Cross-language transfer will bring multiple encoding, decoding and memory copies, resulting in relatively large performance overhead.
We know that when the model is updated, there will be large block types of applications and releases. However, in some general solutions, it does not come with a model preheating solution, which will lead to a relatively high time-consuming jitter in the model update process and cannot support real-time update of the model.
General frameworks use a synchronization mechanism, which has insufficient concurrency and low CPU utilization, and cannot meet high concurrency computing needs.
So, how do we solve these performance bottlenecks in the prediction system?
Why should we do such a thing? Because in traditional solutions, we all know that feature processing and model calculation are deployed in separate processes, which will result in more specific cross-network transmissions, serialization, deserialization, and frequent memory applications and releases. Especially when the feature amount of the recommended scene is particularly large, this will bring significant performance overhead. In the figure below, the flow chart at the top shows the specific situation in the general solution.
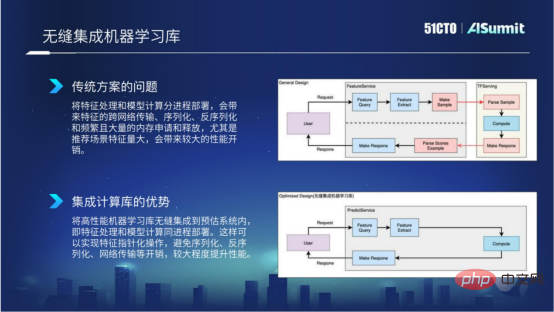
Seamless integration of computer learning library
In order to solve the above problems, we integrate the high-performance computing learning framework into the prediction system Within the system, the advantage of this is that we can ensure that feature processing and model calculation can be deployed in the same process, and can implement feature operations in the form of pointers, avoiding the overhead of serialization, deserialization and network transmission, thereby improving feature calculation and Feature processing brings better computing performance improvement, which is the benefit of seamless integration of machine learning.
First of all, the entire system adopts a fully asynchronous architecture design. The benefit of the asynchronous architecture is that external calls are non-blocking and waiting, so the asynchronous mechanism can ensure that the time-consuming stability of the network service is still maintained under high CPU load, such as 60% to 70%.
Secondly, memory access optimization. Memory access optimization is mainly based on the NUMA architecture of the server, and we adopt a core-bound operation method. In this way, we can solve the problem of remote memory access that existed in the previous NUMA architecture, thus improving the computing performance of our service.
Third, parallel computing. We process computing tasks in slices and use multi-thread concurrency to perform calculations, which can greatly reduce service time consumption and improve resource utilization.
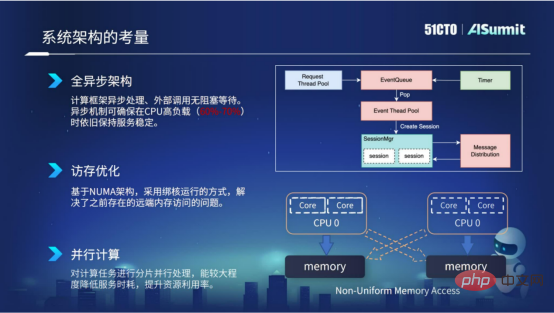
Architectural design considerations
The above is our practice in estimating the system architecture considerations of the system.
Multi-level cache is mainly used in the feature query stage and primary stage. The caching mechanism we encapsulate can, on the one hand, reduce external calls to queries, and on the other hand, reduce repeated invalid calculations caused by feature extraction.
Through caching, the efficiency of query and extraction can be greatly improved. Especially in the query stage, we encapsulate a variety of components based on the importance of the features and the magnitude of the features, such as synchronous query, asynchronous query, and batch import of features.
The first is synchronous query, which is mainly suitable for some more important features. Of course, the performance of synchronous query is not that efficient.
The second type is asynchronous query, which mainly targets some "Aite dimension" features. These features may not be so important, so you can use this asynchronous query method.
The third type is feature batch import, which is mainly suitable for feature data whose feature size is not particularly large. By importing these features into the process in batches, we can implement localized query of features, and the performance is very efficient.
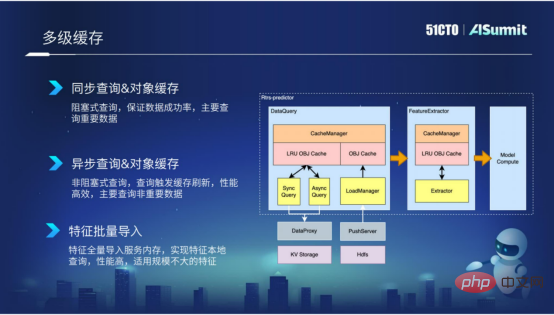
Multi-level cache
After introducing the caching mechanism, let’s take a look at the behavior optimization of model calculation . For model calculation, we mainly optimize from three aspects: model input optimization, model loading optimization and kernel optimization.
In the model input area, everyone knows that TF Servering uses the input of Example. The Example input will include the construction of Example, the serialization and deserialization of Example, and the call to Parse Example inside the model, which will be relatively time-consuming.
In the figure below, we look at the screenshot of [Before Optimization] to show the data statistics before model calculation and optimization. We can see that there is a relatively long Parse Example that takes a long time to parse, and before the Parse Example is parsed, other ops cannot perform parallel scheduling. In order to solve the performance problem of model trees, we have encapsulated a high-performance model input solution in the prediction system. Through the new solution, we can achieve zero copy of feature input, thereby reducing the time-consuming construction and parsing of this Example.
In the picture below, we look at the screenshot of [After Optimization] to show the data statistics after model calculation and optimization. We can see that there is no longer Parse Example parsing time, only the parsing of Example is left. time consuming.

Model calculation optimization
After introducing the model input optimization, let’s take a look at the model Loading optimization. Tensorflow's model loading is a lazy loading mode. After the model is loaded internally, it will not preheat the model. Instead, it will not preheat the model until a formal request from the network comes. This will cause the model to be loaded after There will be serious time-consuming jitter.
In order to solve this problem, we have implemented an automatic model preheating function within the prediction system, hot switching between the old and new models, and asynchronous unloading and memory release of the old model. In this way, through some optimization methods for loading these models, the minute-level update capability of the model is achieved.
Next, let’s take a look at the optimization of the model kernel. At present, we are mainly doing some kernel synchronization optimization on the Tensorflow kernel, and we will adjust some thread pools between ops and within ops according to the model, etc.
The above are some of our attempts to optimize performance in model calculations.
After introducing the above performance optimization solution, let’s take a look at the final performance optimization results.
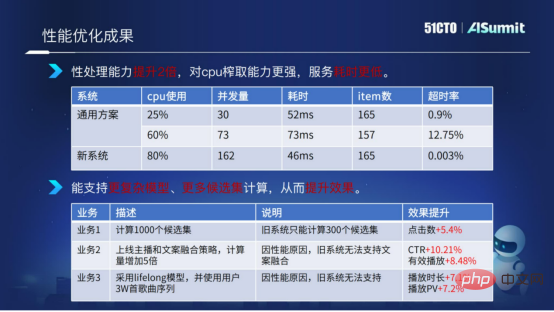
Performance optimization results
Here we make a comparison between the estimation system and the general solution system. We can see that when the CPU usage of the estimated system reaches 80%, the calculation time and timeout rate of the entire service are very stable and very low. Through comparison, we can conclude that the new solution (prediction system) has twice the performance in terms of calculation and processing, has stronger CPU extraction capabilities, and lower service time.
Thanks to our optimization of the system, we can provide more model complexity calculations and more candidate set calculations for business algorithms.
The above figure gives an example. The candidate set has been expanded from the previous 300 candidate sets to 1,000 candidate sets. At the same time, we have increased the computational complexity of the model and used some more complex features. It has brought about better performance improvement in this business.
The above is an introduction to the performance optimization and performance optimization results of the estimation system.
The system adopts a layered architecture design. We divide the entire estimation system into three layers, including the underlying architecture layer, the intermediate template layer and the upper structure layer.
The underlying architecture layer mainly provides asynchronous mechanism, task queue, concurrent scheduling, network communication, etc.
The middle template layer mainly provides components related to model calculation, including query management, cache management, model loading management and model calculation management.
The upper interface layer mainly provides Highlevel interfaces. Businesses only need to implement this layer interface, which greatly reduces code development.
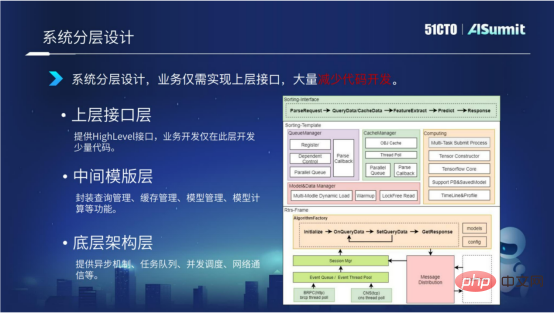
Through the layered architecture design of the system, the code of the bottom and middle layers can be reused between different businesses. Development only needs to focus on the development of a small amount of code on the top layer. . At the same time, we are also thinking further. Is there any way to further reduce the code development of the upper interface layer? Let’s introduce it in detail below.
Through the encapsulation of a general solution formed by feature query and feature analysis based on dynamic pb technology, it is possible to configure table names, query KEY, and cache time only through XML , query dependencies, etc. can realize the entire process of feature query, parsing, and caching.
As shown in the figure below, we can implement a complex query logic with a few lines of configuration. At the same time, query efficiency is improved through query encapsulation.

Feature calculation can be said to be the module with the highest code development complexity in the entire estimation system. So what is a feature? What about calculations?
Feature calculation includes offline process and online process. The offline process is actually offline samples, which are processed to obtain some formats required by the offline training platform, such as the format of TF Recocd. The online process mainly performs some feature calculations on online requests, and obtains some formats required by the online prediction platform through processing. In fact, the calculation logic for feature processing is exactly the same in the offline process and the online process. However, because the computing platforms of the offline process and the online process are different, and the languages used are different, multiple sets of codes need to be developed to implement feature calculation, so there are the following three problems.
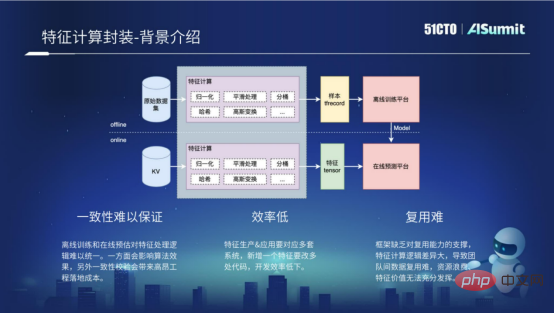
The fundamental reason why consistency is difficult to guarantee is that it is difficult to unify the feature processing logic of offline training and online prediction . On the one hand, it will affect the effect of the algorithm, and on the other hand, it will lead to relatively high one-time verification costs during the development process.
If you want to add a new feature, you need to develop multiple sets of codes involving offline processes and online processes, resulting in very low development efficiency.
It is difficult to reuse. The main reason is that the framework lacks support for reuse capabilities, resulting in the duplication of feature calculations between different businesses. It becomes very difficult to use.
The above are some problems existing in the feature calculation framework.
In order to solve these problems, we will gradually solve them according to the following four points.
First, we propose the concept of operators and abstract feature calculations into operator encapsulation. Secondly, after the operator is encapsulated, we build an operator library, which can provide the ability to reuse operators between businesses. Then, we define the feature calculation description language DSL based on the operators. Through this description language, we can complete the configuration expression of feature calculation. Finally, as mentioned earlier, because there are multiple sets of logic in the online process and the offline process, which will lead to logical inconsistencies, we need to solve the problem of one-time features.
The above four points are our ideas on how to encapsulate the feature calculation framework.

In order to realize operator abstraction, the unification of data protocols must first be achieved. We use dynamic pb technology to process any feature according to unified data based on the original data information of the feature. This provides a data basis for our operator encapsulation. Next, we sample and encapsulate the feature processing process, abstract the feature calculation process into parsing, calculation, assembly, and exception handling, and unify the calculation process API to achieve operator abstraction.
After we have the abstraction of operators, we can build an operator library. The operator library is divided into platform general operator library and business-customized operator library. The platform's general operator library is mainly used to achieve company-level reuse. The business custom operator library is mainly aimed at some custom scenarios and characteristics of the business to achieve reuse within the group. Through the encapsulation of operators and the construction of operator libraries, we realize the reuse of feature calculations in multiple scenarios and improve development efficiency.
The configured expression of feature calculation refers to the configured language that defines the feature calculation expression called DSL. Through configuration language, we can realize multi-level nested expression of operators, four arithmetic operations and so on. The first screenshot below shows the specific syntax of the configured language.

#What benefits can we bring through the configuration language of feature calculation?
First, we can complete the entire feature calculation through configuration, thereby improving development efficiency.
Second, we can achieve hot updates of feature calculations by publishing configured expressions of feature calculations.
Third, training and prediction use the same feature calculation configuration to achieve online and offline consistency.
This is the benefit brought by feature calculation expression.
As mentioned earlier, feature calculation is divided into offline process and online process. Due to the multi-platform reasons of offline and online, the logical calculation is inconsistent. In order to solve this problem, we implemented the cross-platform running capability of the feature computing framework in the feature computing framework. The core logic is developed in C, and the C interface and Java interface are exposed to the outside world. During the packaging and construction process, C's so library and jar package can be implemented with one click, thereby ensuring that feature calculations can run on the C platform for online calculations and the offline Spark platform or Flink platform, and expressed with feature calculations to ensure feature calculations Achieve consistency of online and offline logic.
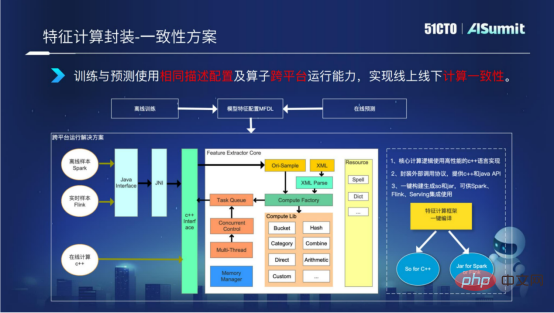
The above describes the specific situation of feature calculation. Let's take a look at some of the results that feature computing has achieved so far.
We have now accumulated operators from 120 companies. Through the DSL language of feature calculation, configuration can be realized and the entire feature calculation can be completed. Through the cross-platform operation capabilities we provide, the problem of online and offline logic inconsistency is solved.
The screenshot in the figure below shows that with a small amount of configuration, the entire feature calculation process can be realized, which greatly improves the development efficiency of feature calculation.

The above introduces our exploration of improving development efficiency. In general, we can improve the reuse of code through the hierarchical design of the system, and achieve a configurable development process by encapsulating queries, extractions, and model calculations.
Model calculation also adopts the form of encapsulation. Through the form of configuration expression, the loading of the model, the input structure of the model, the calculation of the model, etc. are realized. Using a few lines of configuration, the expression process of the entire model calculation is realized.

Let’s take a look at the real-time implementation case of the model.
Why should we do such a model real-time project?
The main reason is that the traditional recommendation system is a system that updates user recommendation results on a daily basis. Its real-time performance is very poor and cannot meet such scenarios with high real-time requirements, such as our live broadcast scene, or Other scenarios with higher real-time requirements.
Another reason is that the traditional sample production method has the problem of feature crossing. What is feature crossing? The following figure shows the fundamental reason for feature crossing. In the process of sample splicing, we use the model estimated structure at "T-1" time and splice it with the features at "T" time. In this way The problem of feature crossing will arise. Feature crossing will greatly affect the effect of line network recommendation. In order to solve the real-time problem and the problem of sample crossing, we implemented such a model real-time solution in the prediction system.
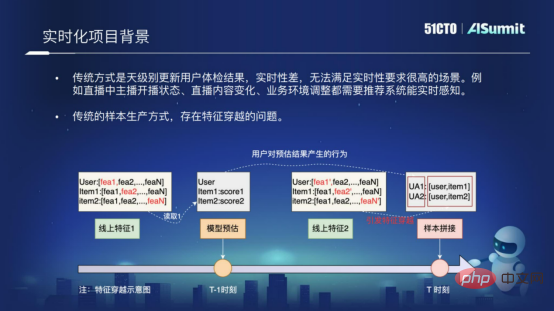
The model real-time solution is elaborated from three dimensions.
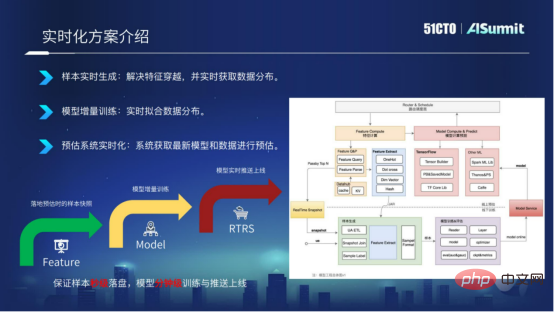
Samples are generated in real time. Based on the online prediction system, we implement the features of the prediction system to Kafka in real time and associate them in the form of RACE ID. This way we can ensure that samples are placed on the disk within seconds and can solve the problem of feature crossing.
Model incremental training. After the samples are placed on the disk in seconds, we can modify the training module to implement incremental training of the model, and achieve minute-level updates of the model.
The prediction system is real-time. After exporting the model at the minute level, we push the latest model to the online prediction system through the model push service Push Server, which enables the on-site prediction system to use the latest model for prediction.
Generally speaking, the real-time model solution is to achieve sample placement in seconds, minute-level training and minute-level online updates of the model.
Our current model real-time solution has been implemented in multiple scenarios. Through the real-time model solution, the business results have been improved significantly.
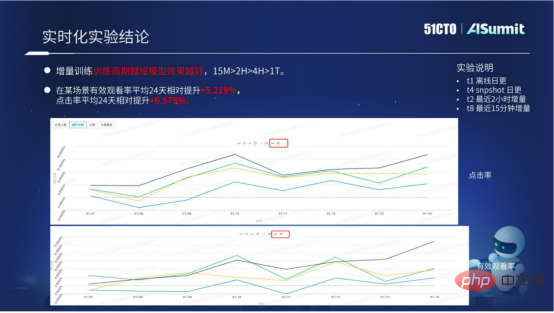
The above figure mainly shows the specific experimental data of the model real-time solution. We can see incremental training, the shorter the training period, the better. Through specific data, we can know that the effect of a cycle of 15 minutes is far greater than that of 2 hours, 10 hours, or one day. The current model real-time solution already has a standardized access process, which can bring better results to the business in batches.
The above introduces the exploration and attempts in three aspects: how the prediction system improves computing performance, how to improve development efficiency, and how to improve project algorithms through engineering means.
The platform value of the entire estimation system, or the platform purpose of the entire estimation system, can be summarized in three words, namely "fast, good and economical".
"Quick" refers to the application construction introduced earlier. We hope that through continuous application construction, business iteration can be more efficient.
"Good" means that we hope that through engineering means, such as the real-time model solution and the online and offline logical consistency solution through feature calculation, we can bring better results to the business.
"Save" means using the higher performance of the estimated system, which can save more computing resources and save computing costs.
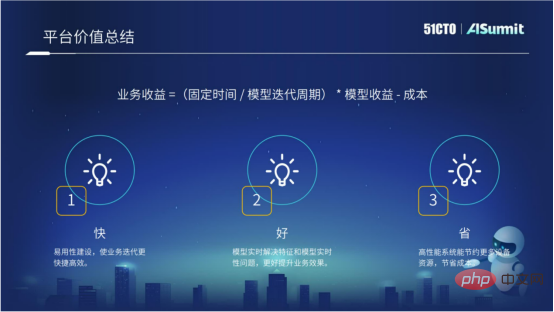
In the future, we will continue to work towards these three goals.
The above is my introduction to the cloud music prediction system. My sharing ends here, thank you all!
The above is the detailed content of Huang Bin, an expert in R&D of NetEase Cloud Music Algorithm Platform: Practice and Thoughts on NetEase Cloud Music Online Prediction System. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 How to optimize a single page
How to optimize a single page
 cad2012 serial number and key collection
cad2012 serial number and key collection
 What should I do if the print spooler cannot be started?
What should I do if the print spooler cannot be started?
 How to configure Tomcat environment variables
How to configure Tomcat environment variables
 Photo display time
Photo display time
 What does terminal equipment mean?
What does terminal equipment mean?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



