

Key technologies for digital human modeling and animation

Introduction: This article will introduce related research work on key technologies of digital human modeling and animation from a graphical perspective, such as face modeling and hair editing. , virtual clothing, etc., mainly including the following parts:
- Face portrait editing and clothing design.
- #Dataset and baseline method for eyelash cutout.
- # Real-time animation of loose clothes based on deep learning.
1. Face portrait editing and costume design
1. Fat and thin adjustment of digital face video portrait
Published an oral report paper on fat and thin adjustment of video portraits at ACM Multimedia2021. It mainly adjusts the fat and thin faces of people in videos so that it is not visually obvious. The natural effect of trimming.

2. Double chin removal

Double Chin Removal is a paper published in Siggraph 2021. Removing a double chin is difficult in face editing because it involves both texture and geometry. If shown, the first row is the original image, and the double chin can be gradually disappeared by adjusting the parameters (second row).
3. Removing hair from portraits

Removing hair from portraits is Remove the hair of the person in the given photo. You can edit hair, such as changing a set of hair for a character. If you keep the original hair, it will interfere with the synthesis result. In the three-dimensional reconstruction of digital people, if the original hair is retained, it will cause interference to the texture. Our method can obtain 3D reconstruction results without hair texture interference.
4. Virtual clothing

This is a new item in the metaverse Fashion, provide a photo, synthesize virtual clothes onto a person's body, and you can wear new clothes as you like.

In sustainable development, there are a lot of problems in the fashion industry. Virtual clothing offers a great solution.

For example, the left side is real clothes and the right side is virtual clothes. It can be seen that virtual clothes and real clothes are very similar.

The clothing model and animation of the digital human Xi Jiajia in the 2022 Baidu World Conference are provided by us.
2. Dataset and baseline method for eyelash cutout
1. Research background


#The picture above is of the digital person in the movie, and the work of virtual plastic surgery.
#What we want to study is how to construct a high-precision three-dimensional face reconstruction method. One method is to collect user photos and use MVS to reconstruct the three-dimensional model, but this method has poor effect on eyelash processing. Because there is geometric information in the eyelashes, it will cause interference to the reconstruction and make the eye area inaccurate.

2. Related work: High-precision face reconstruction
Related There is a lot of research work, such as facial geometry and hair reconstruction, eyelid and eyeball reconstruction, etc., but there is no feasible method to accurately edit eyelashes.

3. Image cutout algorithm and cutout data set
① Cutout method based on three-part graph
To edit the eyelashes, you can use cutout to cut out the eyelashes. Cutout is actually solving an ill-conditioned equation, as shown in the figure below. This is an example of natural cutout based on a three-part diagram. , can get good results. However, this method has a disadvantage. It requires the input of a three-part graph, and it is very difficult to construct a three-part graph.

② Cutout data set
There has been a lot of work on cutout data sets in recent years. For example, a data set from CVPR2009 is shown below.

③ Blue screen cutout
Blue screen cutout is used a lot in movie special effects , usually using a green screen or blue screen, and then calculating the value of the foreground mask through some triangulation methods.

4. Data set and baseline method used for eyelash cutout
① Introduction to data set baseline method
What we want to solve is the cutout of eyelashes. The input on the left is a photo containing eyelashes, and the value of the mask is calculated through the matting network EyelashNet.

② Research motivation
There is geometric texture in the eyelash area. When the three-dimensional reconstruction is parameterized, It will cause great interference to the result and the effect will be very bad. If it is done by an artist, it will be very time-consuming and labor-intensive. Therefore, a method is needed to automatically pull out the eyelashes.

③Main Challenge
If the eyelashes are removed manually, it is very time-consuming and labor-intensive. Using Gabor filtering method, the effect is still not good. Image matting methods can also be used, but data set construction is very difficult. If you use blue screen cutout, the eyelashes grow on the eyelids, so that the background image such as eyelids and eyelids cannot be separated and replaced. In addition, people will blink, making it difficult to keep still when collecting eyelashes. Then you want to collect multiple strictly aligned And it is very difficult to apply eyelashes of different colors.


④ Eyelash data collection
We paint the eyelashes Apply fluorescent agent and turn on the UVA flash, you can see the fluorescent effect, and then get the segmentation results of eyelashes. But this is not enough and further processing is needed.

⑤ Eyelash mask calculation
We use the data set obtained in the previous step as input, using The matting network is used to predict the real matting results. But if we only use the original data set, the effect is not very good, and we do not have ground truth. We designed the virtual synthesis method Render EyelashNet to preheat, and then used the experimental results to predict an estimated result. Combined with manual work, we filtered out those bad results and finally obtained a data set with an initial mask. Then you can use this data set to train and get a refined result. The refined result is put into the data set and then trained. After iteration, a better data set is finally obtained.

5. Eyelash data collection system
① Collection equipment
We built a collection system, including 16 cameras, 365 nm UV flash, fill light system, etc. Please see the screenshots for specific parameters.


We invited many students from Zhejiang University to paint the eyelashes with fluorescent agent. The person had to remain still, and then used a laser to position the eyes.

Comparison of the results of turning on and off the UV flash:

Ideally, there is no offset between the two input comparison images, but human eyelids can easily move and there will be deviations. , we use FlowNet2 to obtain an optical flow field, use the optical flow field results to offset the fluorescent eyelashes, and then obtain a strictly aligned picture, thus obtaining the segmentation result.

6. Inference stage
① GCA network
The publication we mainly use in the inference stage GCA Network at AAAI 2020.

The input of the GCA network is an RGB image and a three-point image, and the output is an eyelash mask. Our previous segmentation The result can be used as the initial three-part diagram result, thereby solving the problem of difficulty in manually constructing the three-part diagram of eyelashes.

② Mask inference network

Here are three The image is divided into the eyelash mask image and the original RGB image as input. Through progressive training, combined with RenderEyelashNet, the preheating network is trained to obtain a mask result. This result is then added to the input as a training set and manually filtered. Obtain a visually correct eyelash cutout dataset, so that there is both virtual and real data. Use this data set for training and inference, and finally get the predicted version of the eyelash mask. Then put it into the training set and iterate again, usually you can achieve the desired result in two times.

③ Manual selection
Even the most advanced hardware and software equipment cannot guarantee the accuracy of eyelash collection To ensure the accuracy of the training data, we remove some bad results through manual selection.

④ Baseline network

After training the baseline network , input a picture for testing, and get better results. For an unknown image, we don't know what its three-dimensional image is. If we directly input a grayscale image, we can still get good eyelash prediction results.

##7. Data set
①Training data setWe capture eyelash data for 12 eye expressions and 15 views.


In order to verify our Method, during testing, we used not only the data we collected ourselves, but also some image data on the Internet.
After two progressive iterations, the results we obtained are already very good and close to the true value.

③ Comparison of methods
We compared with the best methods at present, regardless of Both visually and quantitatively, our method is significantly better than previous methods.


④ Ablation experiment
We also did ablation Experiments to validate various parts of our approach are indispensable.

⑤ Result display
We used some photos on the Internet for verification. These photos are There is no Ground Truth. But for these photos, our method can still calculate better eyelash cutout results.

⑥ Application
We cooperate with Tencent NEXT Studio to use this method for high precision Three-dimensional face reconstruction, the eyelash area has been highly realistic.

Another application is the beautification editing of eyelashes. Once you have eyelashes, you can change their color or make them longer. However, if this method is used in places where people wear glasses and the light intensity is obvious, the results will be biased.

8. Summary
We proposed EyelashNet, which is the first A high-quality eyelash cutout data set, including 5400 high-quality captured eyelash cutout data and 5272 virtual eyelash cutout data.
# We propose a specially designed fluorescent labeling system to capture high-quality eyelash images and masks.
# Our method achieves state-of-the-art performance on eyelash cutouts.
3. Real-time animation of loose clothes based on deep learning
This work is to simulate loose clothes. We cooperated with the University of Maryland and Tencent NEXT Studio, and related papers were published on Siggraph2022. This work proposes a real-time prediction method for loose clothing based on deep learning, which can handle large-scale movements well and supports variable simulation parameters.

1. Virtual Skeleton
One of the core technologies of this work is virtual skeleton, which is a set of controls using rigid transformation and linear hybrid simulation methods. Simulated skeleton for clothing deformation. Using virtual bones, we can efficiently simulate the complex deformations of loose clothing, and these bones can be used as input to guide the generation of clothing details.

2. Work background
There are generally two ways to make clothes move. Class methods, one is a physical method, which is computationally expensive; the other method is data-driven, which learns and drives from real data. This method is relatively fast and has good performance. .

In recent years, there have been more and more methods of machine learning and deep learning, but these methods are either predictive Clothing deformation under static conditions, or predicting dynamic deformation of tight-fitting clothing. But in fact, many clothes such as skirts are loose. Although some methods can predict the deformation of loose clothes, they are not very good at predicting the deformation of large movements. Moreover, none of the current methods support variable parameters.

3. Research contribution
Our research mainly has two points Contribution, the first one is to use deep learning method to predict the complex deformation of loose clothes. We disassemble the clothing deformation into two parts-the low-frequency part and the high-frequency part. Use virtual bones to represent the deformation of the low-frequency part and use it to infer the high-frequency part; the second contribution is to use the body's movements combined with physical simulation parameters as input, and use this method to handle the heterogeneity of the two inputs.

4. Summary description
① Virtual skeleton generation method

First use the simulation method to obtain a ground truth training set, perform Laplacian smoothing processing on these training sets to obtain low-frequency Mesh, and then perform Skin Decomposition processing to obtain Virtual bones and weights.
② Motion network
Get the motion sequence of the virtual skeleton through the body motion sequence, predict low-frequency deformation information through the motion network, and use low-frequency The information predicts high-frequency information, and finally the simulation results are obtained (the rightmost graph).

③ Simulation parameter variables
We want to evaluate different parameter variables, through The RBF network predicts the results of simulation parameters that we have not seen, so that a set of networks can be used to make predictions even if the parameters are different.

5. Method
① Data preparation
First of all, we need to generate ground truth data. We use the Houdini Vellum Solver to simulate approximately 40,000 frames of animation. We did not use the motion capture results of real people, but the video actions from the Internet. This is because we want to simulate large movements, but real people's movements are smaller.

② Skin Decomposition
Low-frequency deformation sequence We use skin decomposition to obtain virtual bones, and we get The result is a linear hybrid skinned model that includes a Rest Pose and skin weights corresponding to each bone. The translation and rotation of the virtual skeleton at each frame are also obtained. Virtual bones have no hierarchical relationship, there is no relationship between parent bones and child bones, and each bone has its own rotation and translation.
#In addition, virtual bones have no real realistic meaning. Virtual bones are obtained for each specific animation. We use Motion Network to process the input of the body. Each network corresponds to different body simulation parameters. The input is only the rotation of the joints and the translation of the character, and the output is the Mesh inference result corresponding to the physical parameters.

③ Action network
The action network infers the low-frequency and high-frequency parts in sequence.
- Low frequency module
The low frequency part uses a recurrent neural network GRU converts input body movements into rotations and translations of virtual bones. The advantage of using a recurrent neural network is that it can obtain information from previous frames, which can better capture dynamic effects. Low-frequency deformations can be obtained using linear hybrid skinning of virtual bones.

- High frequency module
The action network can be used to predict the high-frequency part. One is GRU to obtain high-frequency features, and the other is GNN to obtain low-frequency part features. The two parts of features are passed through MLP to obtain high-frequency information. The high frequency and low frequency results are added together to get the final result.

- ##RBF Neural Network
In order to process the physical simulation parameter input, we trained many Motion Networks with different actions. The output of the same action corresponds to the parameter simulation results. We use the RBF neural network to add these results. The weighting coefficient depends on the simulation parameters and Corresponds to the distance of the simulated parameters of the network, and uses a multi-layer perceptron to project the parameters into a space before calculating the distance.

In real-time simulation, without changing the simulation parameters, Loose clothing can be simulated very well.
- Result Performance

##The simulation results on the left are very close to the ground truth, and the right side deals with variable parameters. #Another question is how to select the number of virtual bones. Our experiment found that for the low-frequency part, too small a number has no good effect, and too much does not help much. 80 is a better result. But for the high-frequency part, the more virtual bones the better, so that details can be better expressed. Loose refers to the distance between the clothes and the human body. The red part means farther, and the blue part means tight. section, we can see that our results (far right) are better. This is a comparison chart between low frequency and high frequency cases and the true value. Our method is closer to the ground truth. . Visually different Comparison of methods, although our effect is slightly different from the ground truth, it is relatively better. Regardless of the high frequency or low frequency parts, they are relatively close. We also conducted quantitative analysis, such as RMSE, STED and other indicators, and the results showed that it was significantly better than previous methods, even for tight-fitting clothes and traditional methods. We conducted an ablation experiment through the RBF network to verify our method. In a very big move In some cases, the legs in the simulation results may pass through the clothes. This is because collision avoidance is added through the energy network. Other skinning methods can also be used in the future to obtain better results. #A1: The virtual bones are calculated. Changing a set of clothes requires regenerating new bones, and the number and transformation are also different. It is calculated in real time during inference. #A2: It is still very convenient. People who have never learned it before can learn it quickly after training. Even if you design an outfit from scratch, you may be able to design a very complicated outfit in one or two hours. 








4. Question and Answer Session
#Q1: How to ensure the stability of virtual bones Generalizability?
Q2: Is it easy to make three-dimensional clothing?
The above is the detailed content of Key technologies for digital human modeling and animation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



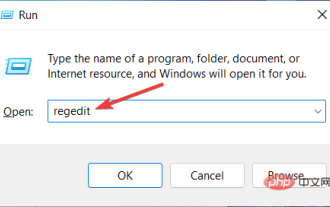 How to speed up animation effects in Windows 11: 2 methods explained
Apr 24, 2023 pm 04:55 PM
How to speed up animation effects in Windows 11: 2 methods explained
Apr 24, 2023 pm 04:55 PM
When Microsoft launched Windows 11, it brought a lot of changes. One of the changes is an increase in the number of user interface animations. Some users want to change the way things appear, and they have to find a way to do it. Having animations makes it feel better and more user-friendly. Animation uses visual effects to make the computer look more attractive and responsive. Some of them include sliding menus after a few seconds or minutes. There are many animations on your computer that can affect PC performance, slow it down, and interfere with your work. In this case you have to turn off animation. This article will introduce several ways that users can improve the speed of their animations on PC. You can apply the changes using Registry Editor or a custom file you run. How to improve animations in Windows 11
 CSS Animation: How to Achieve the Flash Effect of Elements
Nov 21, 2023 am 10:56 AM
CSS Animation: How to Achieve the Flash Effect of Elements
Nov 21, 2023 am 10:56 AM
CSS animation: How to achieve the flash effect of elements, specific code examples are needed. In web design, animation effects can sometimes bring a good user experience to the page. The glitter effect is a common animation effect that can make elements more eye-catching. The following will introduce how to use CSS to achieve the flash effect of elements. 1. Basic implementation of flash First, we need to use the animation property of CSS to achieve the flash effect. The value of the animation attribute needs to specify the animation name, animation execution time, and animation delay time
![Animation not working in PowerPoint [Fixed]](https://img.php.cn/upload/article/000/887/227/170831232982910.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) Animation not working in PowerPoint [Fixed]
Feb 19, 2024 am 11:12 AM
Animation not working in PowerPoint [Fixed]
Feb 19, 2024 am 11:12 AM
Are you trying to create a presentation but can't add animation? If animations are not working in PowerPoint on your Windows PC, then this article will help you. This is a common problem that many people complain about. For example, animations may stop working during presentations in Microsoft Teams or during screen recordings. In this guide, we will explore various troubleshooting techniques to help you fix animations not working in PowerPoint on Windows. Why aren't my PowerPoint animations working? We have noticed that some possible reasons that may cause the animation in PowerPoint not working issue on Windows are as follows: Due to personal
 How to set up ppt animation to enter first and then exit
Mar 20, 2024 am 09:30 AM
How to set up ppt animation to enter first and then exit
Mar 20, 2024 am 09:30 AM
We often use ppt in our daily work, so are you familiar with every operating function in ppt? For example: How to set animation effects in ppt, how to set switching effects, and what is the effect duration of each animation? Can each slide play automatically, enter and then exit the ppt animation, etc. In this issue, I will first share with you the specific steps of entering and then exiting the ppt animation. It is below. Friends, come and take a look. Look! 1. First, we open ppt on the computer, click outside the text box to select the text box (as shown in the red circle in the figure below). 2. Then, click [Animation] in the menu bar and select the [Erase] effect (as shown in the red circle in the figure). 3. Next, click [
 After a two-year delay, the domestic 3D animated film 'Er Lang Shen: The Deep Sea Dragon' is scheduled to be released on July 13
Jan 26, 2024 am 09:42 AM
After a two-year delay, the domestic 3D animated film 'Er Lang Shen: The Deep Sea Dragon' is scheduled to be released on July 13
Jan 26, 2024 am 09:42 AM
This website reported on January 26 that the domestic 3D animated film "Er Lang Shen: The Deep Sea Dragon" released a set of latest stills and officially announced that it will be released on July 13. It is understood that "Er Lang Shen: The Deep Sea Dragon" is produced by Mihuxing (Beijing) Animation Co., Ltd., Horgos Zhonghe Qiancheng Film Co., Ltd., Zhejiang Hengdian Film Co., Ltd., Zhejiang Gongying Film Co., Ltd., Chengdu The animated film produced by Tianhuo Technology Co., Ltd. and Huawen Image (Beijing) Film Co., Ltd. and directed by Wang Jun was originally scheduled to be released in mainland China on July 22, 2022. Synopsis of the plot of this site: After the Battle of the Conferred Gods, Jiang Ziya took the "Conferred Gods List" to divide the gods, and then the Conferred Gods List was sealed by the Heavenly Court under the deep sea of Kyushu Secret Realm. In fact, in addition to conferring divine positions, there are also many powerful evil spirits sealed in the Conferred Gods List.
 How to use Vue to implement typewriter animation effects
Sep 19, 2023 am 09:33 AM
How to use Vue to implement typewriter animation effects
Sep 19, 2023 am 09:33 AM
How to use Vue to implement typewriter animation special effects Typewriter animation is a common and eye-catching special effect that is often used in website titles, slogans and other text displays. In Vue, we can achieve typewriter animation effects by using Vue custom instructions. This article will introduce in detail how to use Vue to achieve this special effect and provide specific code examples. Step 1: Create a Vue project First, we need to create a Vue project. You can use VueCLI to quickly create a new Vue project, or manually
 The final trailer for Netflix's claymation film 'Chicken Run 2” has been announced and will be released on December 15
Nov 20, 2023 pm 01:21 PM
The final trailer for Netflix's claymation film 'Chicken Run 2” has been announced and will be released on December 15
Nov 20, 2023 pm 01:21 PM
The final trailer for Netflix's claymation film "Chicken Run 2" has been released. The film is expected to be released on December 15. This site noticed that the trailer for "Chicken Run 2" shows Chicken Loki and King Kong. Jay launches an operation to find his daughter Molly. Molly is taken away by a truck at FunLand Farm, and Rocky and Ginger risk their lives to retrieve their daughter. The film is directed by Sam Fehr and stars Sandy Way Newton, Zachary Levi, Bella Ramsey, Imelda Staunton and David Bradley. It is understood that "Chicken Run 2" is the sequel to "Chicken Run" after more than 20 years. The first work was released in China on January 2, 2001. It tells the story of a group of chickens who face the fate of being turned into chicken pies in a chicken factory.
 How to disable animations in Windows 11
Apr 16, 2023 pm 11:34 PM
How to disable animations in Windows 11
Apr 16, 2023 pm 11:34 PM
Microsoft Windows 11 includes many new features and functions. The user interface has been updated and the company has also introduced some new effects. By default, animation effects are applied to controls and other objects. Should I disable these animations? Although Windows 11 features visually appealing animations and fade effects, they can cause your computer to feel sluggish to some users as they add a bit of lag to certain tasks. It's easy to turn off animations for a more responsive user experience. After we see what other changes have been made to the operating system, we'll walk you through how to turn animation effects on or off in Windows 11. We also have an article on how to
