
 Backend Development
Python Tutorial
Python programming: Detailed explanation of the key points of using named tuples
Backend Development
Python Tutorial
Python programming: Detailed explanation of the key points of using named tuples
Python programming: Detailed explanation of the key points of using named tuples

Preface
This article continues to introduce the Python collection module. This time it mainly introduces the named tuples in it, that is, the use of namedtuple. Without further ado, let’s get started - remember to like, follow and retweet~ ^_^
Creating named tuples
The named tuple class namedTuples in the Python collection is the tuple. Each position gives meaning and enhances the readability and descriptiveness of the code. They can be used anywhere regular tuples are used, and add the ability to access fields by name rather than positional index. It comes from the Python built-in module collections. The general syntax used is:
import collections XxNamedTuple = collections.namedtuple(typename, field_names):
If the import method is different, such as: import collections as cAlias, from collections import namedtuple, from collections import namedtuple as NamedTuple, etc., in this way, the named tuple subclass we create The form can correspond to:
XxNamedTuple = cAlias.namedtuple(……) XxNamedTuple = namedtuple(……) XxNamedTuple = NamedTuple(……)
Among them:
Parameter typename: Specify a string class name for the returned new tuple subclass XxNamedTuple. New subclass for creating tuple-like objects with related fields that can be accessed through property lookup, positional indexing, and iteration. Instances of the subclass also have a useful docstring (equivalent to a help document, with typename and field_names) and a useful __repr__() method that lists the tuple contents in the name=value format.
Parameter field_names: is usually a sequence of strings, such as ['x', 'y']. Optionally, field_names can be a string containing corresponding field names separated by spaces and/or commas, such as ' x y ' or ' x, y '.
Any valid Python identifier can be used as a named field name, but it cannot start with an underscore (_). Valid identifiers include letters, numbers, and underscores, but do not start with numbers or underscores, and keywords such as class, return, global, pass, or raise cannot be used.
To understand how NamedTuple works, let's assume that we have an Employee object that has id, name, and age properties. Please see the code sample list:

The output of running the program is similar to the following:
Employee(, name='Solo Cui ', age='18') 按索引方式访问Employee的名子为 : Solo Cui Employee(, name='Annie Kent', age='26') 按键(字段名)访问Employee的名子为 : Annie Kent
In addition, several other parameters in the function that creates the named tuple are used Few, here is just a brief introduction:
Parameter rename: If rename is true, invalid field names will be automatically replaced with positional names. For example, ['abc', 'def', 'ghi', 'abc'] is converted to ['abc', '_1', 'ghi', '_3'], eliminating the keyword def and duplicate field names abc.
Parameter defaults: It can be None or an iterable object of default value. Since a field with a default value must appear after any field without a default value, the default value is applied to the rightmost parameter, sequentially to the left. For example, if the field name is ['x', 'y', 'z'] and the default value is (1,2), then x will be a required parameter, y will default to 1, and z will default to 2.
Parameter module: If module is defined, the __module__ attribute of the named tuple is set to this value.
Named tuple instances do not use a separate dictionary for each instance, so they are lightweight and do not require more memory than regular tuples.
Named tuple specific methods
In addition to the methods inherited from tuples, named tuples support three additional methods and two properties. To prevent conflicts with field names, method and property names begin with an underscore. They are introduced as follows:
1) _make(iterable):
class method to generate new instances from existing sequences or iterable objects. The code example is as follows:

The output result is similar to the following:
Employee(, name='Batman', age='28')
2) _asdict ():
Return A new dictionary that maps field names to corresponding values. The sample code is as follows:

The output result is similar to the following:
{'id': '333', 'name': 'Batman', 'age': '28'}
3)_replace (**kwargs):
Return a new instance of the named tuple, replacing the specified fields with new values. The code example is as follows:

The output result is as follows:
Employee(, name='Batman', age='34')
4) _fields:
takes string elements List field names in groups. Used for introspection and creating new named tuple types from existing named tuples. The sample code is as follows:

#The output result is:
('id', 'name', 'age')我们可以使用_fields属性从现有的命名元组中创建新的命名元组。示例如下:
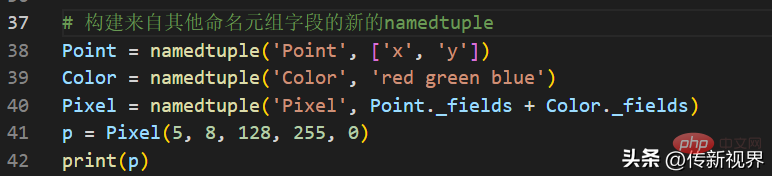
输出结果类似如下:
Pixel(x=5, y=8, red=128, green=255, blue=0)
结果的实体性赋值
这里所说的实体,类似Java中的数据实体对象——只有简单的属性字段。而命名元组在为csv或sqlite3模块操作而返回的元组结果分配给对应字段名而装配成简单实体时特别有用,自动进行字段的对应赋值。比如在当前Python程序位置有个employees.csv,其包含内容如下:
张三,26,工程师,开发部,中级 李四,32,项目经理,项目部,高级
通过示例,我们来完成Employee实体的命名元组的自动装配,代码示例如下:
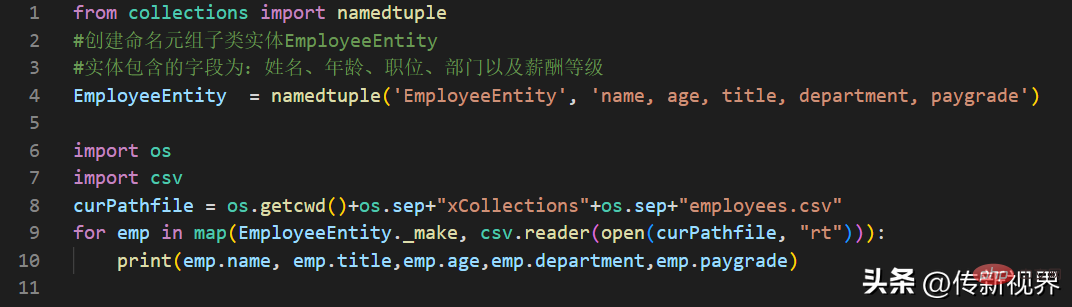
输出结果类似如下:
张三 工程师 26 开发部 中级 李四 项目经理 32 项目部 高级
再简单地来个数据库操作和装配实体的示例,代码清单如下:
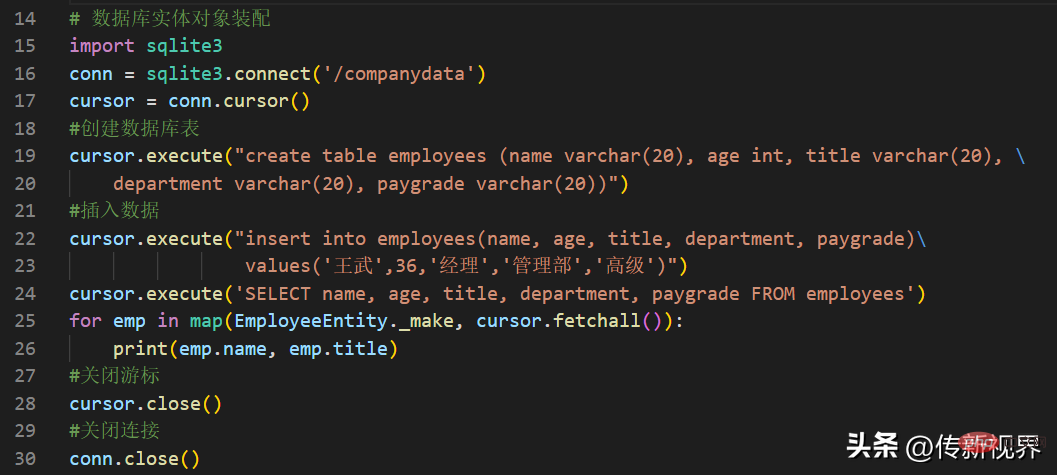
我这里只是简单的创建了数据库并创建表,然后插入一条数据,再查询并完成命名元组的实体化装配和结果输出。
运行输出结果如下:
王武 经理
本文小结
本文主要介绍了Python自带集合模块中的命名元组(namedtuple)的使用,即可以当做一般的元组使用,由可基于字段名的方式访问元组值,并介绍了命名元组内部扩展的几个方法和和属性的应用示例。最后还介绍了基于命名元组的实体化封装应用。基于代码示例进行介绍,这样便于你动手实践,以便更好地掌握和理解。
The above is the detailed content of Python programming: Detailed explanation of the key points of using named tuples. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Is the conversion speed fast when converting XML to PDF on mobile phone?
Apr 02, 2025 pm 10:09 PM
Is the conversion speed fast when converting XML to PDF on mobile phone?
Apr 02, 2025 pm 10:09 PM
The speed of mobile XML to PDF depends on the following factors: the complexity of XML structure. Mobile hardware configuration conversion method (library, algorithm) code quality optimization methods (select efficient libraries, optimize algorithms, cache data, and utilize multi-threading). Overall, there is no absolute answer and it needs to be optimized according to the specific situation.
 How to convert XML files to PDF on your phone?
Apr 02, 2025 pm 10:12 PM
How to convert XML files to PDF on your phone?
Apr 02, 2025 pm 10:12 PM
It is impossible to complete XML to PDF conversion directly on your phone with a single application. It is necessary to use cloud services, which can be achieved through two steps: 1. Convert XML to PDF in the cloud, 2. Access or download the converted PDF file on the mobile phone.
 What is the function of C language sum?
Apr 03, 2025 pm 02:21 PM
What is the function of C language sum?
Apr 03, 2025 pm 02:21 PM
There is no built-in sum function in C language, so it needs to be written by yourself. Sum can be achieved by traversing the array and accumulating elements: Loop version: Sum is calculated using for loop and array length. Pointer version: Use pointers to point to array elements, and efficient summing is achieved through self-increment pointers. Dynamically allocate array version: Dynamically allocate arrays and manage memory yourself, ensuring that allocated memory is freed to prevent memory leaks.
 Is there any mobile app that can convert XML into PDF?
Apr 02, 2025 pm 08:54 PM
Is there any mobile app that can convert XML into PDF?
Apr 02, 2025 pm 08:54 PM
An application that converts XML directly to PDF cannot be found because they are two fundamentally different formats. XML is used to store data, while PDF is used to display documents. To complete the transformation, you can use programming languages and libraries such as Python and ReportLab to parse XML data and generate PDF documents.
 How to convert xml into pictures
Apr 03, 2025 am 07:39 AM
How to convert xml into pictures
Apr 03, 2025 am 07:39 AM
XML can be converted to images by using an XSLT converter or image library. XSLT Converter: Use an XSLT processor and stylesheet to convert XML to images. Image Library: Use libraries such as PIL or ImageMagick to create images from XML data, such as drawing shapes and text.
 How to control the size of XML converted to images?
Apr 02, 2025 pm 07:24 PM
How to control the size of XML converted to images?
Apr 02, 2025 pm 07:24 PM
To generate images through XML, you need to use graph libraries (such as Pillow and JFreeChart) as bridges to generate images based on metadata (size, color) in XML. The key to controlling the size of the image is to adjust the values of the <width> and <height> tags in XML. However, in practical applications, the complexity of XML structure, the fineness of graph drawing, the speed of image generation and memory consumption, and the selection of image formats all have an impact on the generated image size. Therefore, it is necessary to have a deep understanding of XML structure, proficient in the graphics library, and consider factors such as optimization algorithms and image format selection.
 Recommended XML formatting tool
Apr 02, 2025 pm 09:03 PM
Recommended XML formatting tool
Apr 02, 2025 pm 09:03 PM
XML formatting tools can type code according to rules to improve readability and understanding. When selecting a tool, pay attention to customization capabilities, handling of special circumstances, performance and ease of use. Commonly used tool types include online tools, IDE plug-ins, and command-line tools.
 Is there a mobile app that can convert XML into PDF?
Apr 02, 2025 pm 09:45 PM
Is there a mobile app that can convert XML into PDF?
Apr 02, 2025 pm 09:45 PM
There is no APP that can convert all XML files into PDFs because the XML structure is flexible and diverse. The core of XML to PDF is to convert the data structure into a page layout, which requires parsing XML and generating PDF. Common methods include parsing XML using Python libraries such as ElementTree and generating PDFs using ReportLab library. For complex XML, it may be necessary to use XSLT transformation structures. When optimizing performance, consider using multithreaded or multiprocesses and select the appropriate library.
