
 Technology peripherals
AI
Can BERT also be used on CNN? ByteDance's research results selected for ICLR 2023 Spotlight
Technology peripherals
AI
Can BERT also be used on CNN? ByteDance's research results selected for ICLR 2023 Spotlight
Can BERT also be used on CNN? ByteDance's research results selected for ICLR 2023 Spotlight

How to run BERT on a convolutional neural network?
You can directly use SparK - Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling proposed by the ByteDance technical team. Recently, it has been included as a Spotlight focus paper by the top artificial intelligence conference :

##Paper link:
https://www.php.cn/link/e38e37a99f7de1f45d169efcdb288dd1
Open source code: ##
https://www.php.cn/link/9dfcf16f0adbc5e2a55ef02db36bac7f
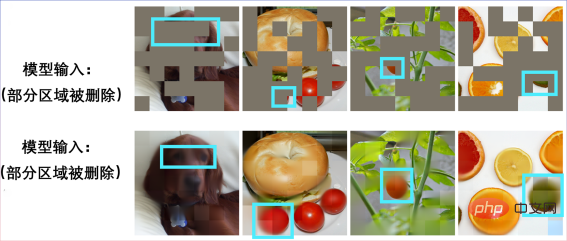
This is also BERT’s first success in convolutional neural networks (CNN)##. Let’s first feel the performance of SparK in pre-training. Enter an incomplete picture:
Restore a puppy: 
Another A mutilated picture: 
It turns out to be a bagel sandwich: 
Other scenes can also achieve picture restoration: 
 The perfect match between BERT and Transformer
The perfect match between BERT and Transformer
“
Any great actions and thoughts, They all have a humble beginning.”Behind the BERT pre-training algorithm is a simple and profound design . BERT uses "cloze": randomly delete several words in a sentence and let the model learn to recover.
BERT relies heavily on the
core model in the NLP field - Transformer. Transformer is naturally suitable for processing variable-length sequence data (such as an English sentence), so it can easily cope with BERT's "random deletion" of cloze ".
CNN in the visual field also wants to enjoy BERT: What are the two challenges?
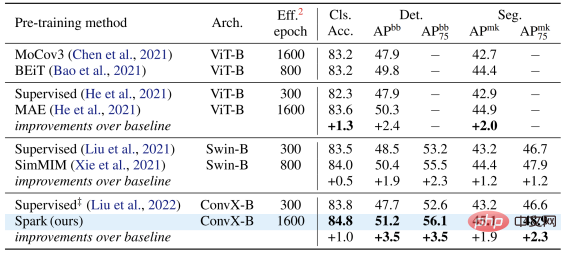
Looking back at the development history of computer vision, Convolutional neural network model condenses the essence of many classic models such as translational equivariance, multi-scale structure, etc. , can be described as the mainstay of the CV world. But what is very different from Transformer is that CNN is inherently unable to adapt to data that is "hollowed out" by cloze and full of "random holes", so it cannot enjoy the dividends of BERT pre-training at first glance. The picture on the right b. shows a rough way to fuse the BERT and CNN models - that is, "blacken" all the empty areas, and When this "black mosaic" image is input into CNN, the result can be imagined, which will cause serious pixel intensity distribution shift problem and lead to poor performance (verified later). This is the challenge that hinders the successful application of BERT on CNN. #In addition, the author team also pointed out that the BERT algorithm originating from the field of NLP naturally does not have the characteristics of "multi-scale", and the multi-scale pyramid structure It can be called the "gold standard" in the long history of computer vision. The conflict between single-scale BERT and natural multi-scale CNN is Challenge 2. Solution SparK: Sparse and Hierarchical Mask Modeling First, inspired by three-dimensional point cloud data processing, the author team proposed to treat the fragmented images after masking operation (hollowing operation) as Sparse point clouds are encoded using Submanifold Sparse Convolution. This allows the convolutional network to handle randomly deleted images easily. Secondly, inspired by the elegant design of UNet, the author team naturally designed an encoder-decoder model with horizontal connections, allowing Multi-scale features flow between multiple levels of the model, allowing BERT to fully embrace the multi-scale gold standard of computer vision. At this point, SparK, a sparse, multi-scale mask modeling algorithm tailored for convolutional networks (CNN), was born. SparK is It can Can be directly used on any convolutional network without any modification to their structure or the introduction of any additional components - whether it is the familiar classic ResNet or the recent advanced model ConvNeXt, you can directly benefit from SparK . From ResNet to ConvNeXt: Performance improvements in three major visual tasks The author team selected two representative convolution model families, ResNet and ConvNeXt, and conducted performance tests on image classification, target detection, and instance segmentation tasks. On the classic ResNet-50 model, SparK serves as the only generative pre-training,
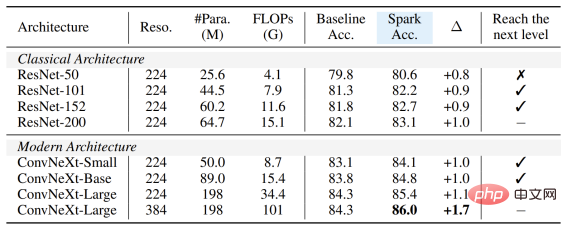
On the ConvNeXt model, SparK still leads . Before pre-training, ConvNeXt and Swin-Transformer were evenly matched; after pre-training, ConvNeXt overwhelmingly surpassed Swin-Transformer in three tasks: When verifying SparK on the complete model family from small to large, you can observe: ##No matter Models big or small, new or old, can all benefit from SparK, and as the model size/training overhead increases, the increase is even higher, reflecting the scaling capability of the SparK algorithm: Sparse MaskandHierarchical Structure Lines 3 and 4 Lines) are very critical designs. Once missing, it will cause serious performance degradation: 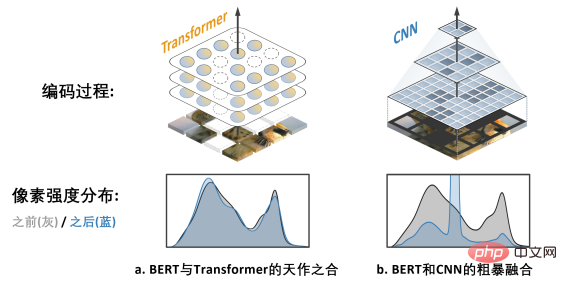
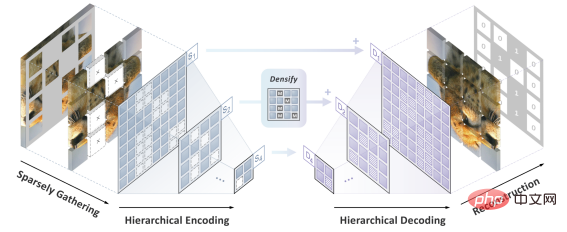 ##The author team proposed SparK (Sparse and hierarchical masKed modeling) to solve the previous two problems a challenge.
##The author team proposed SparK (Sparse and hierarchical masKed modeling) to solve the previous two problems a challenge. 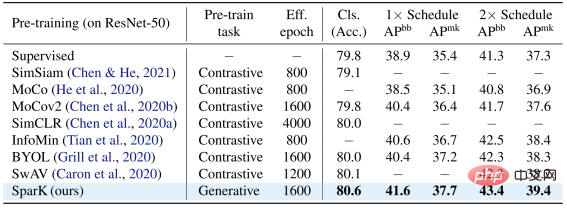
The above is the detailed content of Can BERT also be used on CNN? ByteDance's research results selected for ICLR 2023 Spotlight. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 ByteDance's video editing app CapCut's global user spending exceeds US$100 million
Sep 14, 2023 pm 09:41 PM
ByteDance's video editing app CapCut's global user spending exceeds US$100 million
Sep 14, 2023 pm 09:41 PM
CapCut, a creative video editing tool owned by ByteDance, has a large number of users in China, the United States and Southeast Asia. The tool supports Android, iOS and PC platforms. The latest report from market research agency data.ai pointed out that as of September 11, 2023, CapCut’s total user spending on iOS and Google Play has exceeded US$100 million (notes on this site: currently about 7.28 billion), successfully surpassing Splice (ranked first in the second half of 2022) and becoming the world's most profitable video editing application in the first half of 2023, an increase of 180% compared with the second half of 2022. As of August 2023, 490 million people around the world are using CapCut through iPhone and Android phones. da
 Bytedance model large-scale deployment actual combat
Apr 12, 2023 pm 08:31 PM
Bytedance model large-scale deployment actual combat
Apr 12, 2023 pm 08:31 PM
1. Background introduction In ByteDance, applications based on deep learning are blooming everywhere. Engineers pay attention to model effects but also need to pay attention to the consistency and performance of online services. In the early days, this usually required algorithm experts and engineering experts to work together and work closely together to complete. This mode has relatively high costs such as diff troubleshooting and verification. With the popularity of the PyTorch/TensorFlow framework, deep learning model training and online reasoning have been unified. Developers only need to pay attention to the specific algorithm logic and call the Python API of the framework to complete the training verification process. After that, the model can be easily serialized and exported. , and the reasoning work is completed by a unified high-performance C++ engine. Improved developer experience from training to deployment
 Accelerate diffusion model, generate SOTA-level images in the fastest 1 step, Byte Hyper-SD is open source
Apr 25, 2024 pm 05:25 PM
Accelerate diffusion model, generate SOTA-level images in the fastest 1 step, Byte Hyper-SD is open source
Apr 25, 2024 pm 05:25 PM
Recently, DiffusionModel has made significant progress in the field of image generation, bringing unprecedented development opportunities to image generation and video generation tasks. Despite the impressive results, the multi-step iterative denoising properties inherent in the inference process of diffusion models result in high computational costs. Recently, a series of diffusion model distillation algorithms have emerged to accelerate the inference process of diffusion models. These methods can be roughly divided into two categories: i) trajectory-preserving distillation; ii) trajectory reconstruction distillation. However, these two types of methods are limited by the limited effect ceiling or changes in the output domain. In order to solve these problems, the ByteDance technical team proposed a trajectory segmentation consistent method called Hyper-SD.
 Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
According to news on June 13, according to Byte's "Volcano Engine" public account, Xiaomi's artificial intelligence assistant "Xiao Ai" has reached a cooperation with Volcano Engine. The two parties will achieve a more intelligent AI interactive experience based on the beanbao large model. It is reported that the large-scale beanbao model created by ByteDance can efficiently process up to 120 billion text tokens and generate 30 million pieces of content every day. Xiaomi used the beanbao large model to improve the learning and reasoning capabilities of its own model and create a new "Xiao Ai Classmate", which not only more accurately grasps user needs, but also provides faster response speed and more comprehensive content services. For example, when a user asks about a complex scientific concept, &ldq
 Shenzhen Bytedance Houhai Center has a total construction area of 77,400 square meters and the main structure has been topped out
Jan 24, 2024 pm 05:27 PM
Shenzhen Bytedance Houhai Center has a total construction area of 77,400 square meters and the main structure has been topped out
Jan 24, 2024 pm 05:27 PM
According to the Nanshan District Government’s official WeChat public account “Innovation Nanshan”, the Shenzhen ByteDance Houhai Center project has made important progress recently. According to the China Construction First Engineering Bureau Construction and Development Company, the main structure of the project has been capped three days ahead of schedule. This news means that the core area of Nanshan Houhai will usher in a new landmark building. The Shenzhen ByteDance Houhai Center project is located in the core area of Houhai, Nanshan District. It is the headquarters office building of Toutiao Technology Co., Ltd. in Shenzhen. The total construction area is 77,400 square meters, with a height of about 150 meters and a total of 4 underground floors and 32 above ground floors. It is reported that the Shenzhen ByteDance Houhai Center project will become an innovative super high-rise building integrating office, entertainment, catering and other functions. This project will help Shenzhen promote the integration of the Internet industry
 NUS and Byte collaborated cross-industry to achieve 72 times faster training through model optimization, and won the AAAI2023 Outstanding Paper.
May 06, 2023 pm 10:46 PM
NUS and Byte collaborated cross-industry to achieve 72 times faster training through model optimization, and won the AAAI2023 Outstanding Paper.
May 06, 2023 pm 10:46 PM
Recently, the top international artificial intelligence conference AAAI2023 announced the selection results. The CowClip technical paper collaborated by the National University of Singapore (NUS) and ByteDance Machine Learning Team (AML) was shortlisted for Distinguished Papers (Distinguished Papers). CowClip is a model training optimization strategy that can increase model training speed by 72 times on a single GPU while ensuring model accuracy. The relevant code is now open source. Paper address: https://arxiv.org/abs/2204.06240Open source address: https://github.com/bytedance/LargeBatchCTRAAA
 PICO 4 sales are far below expectations, and news reports that ByteDance will cancel the next-generation VR headset PICO 5
Dec 15, 2023 am 09:34 AM
PICO 4 sales are far below expectations, and news reports that ByteDance will cancel the next-generation VR headset PICO 5
Dec 15, 2023 am 09:34 AM
According to news from this website on December 13, according to The Information, ByteDance is preparing to ax its PICO new generation VR headset PICO5 because the sales of the current PICO4 are far lower than expected. According to an article by EqualOcean in October this year, ByteDance is said to be gradually shutting down PICO and abandoning the Metaverse field. The article pointed out that Bytedance believed that the hardware field in which PICO was located was not its expertise, its performance in the past few years had not met expectations, and it lacked hope for the future. At that time, the relevant person in charge of ByteDance responded to the rumors about "gradually abandoning the PICO business" responded, saying the news was untrue. They stated that PICO's business is still operating normally and that the company will invest in extended reality for the long term.
 Analysis of application cases of Go language in well-known companies such as Huawei and Bytedance
Mar 07, 2024 pm 03:51 PM
Analysis of application cases of Go language in well-known companies such as Huawei and Bytedance
Mar 07, 2024 pm 03:51 PM
As an efficient and concise programming language, Go language has been widely used in many well-known companies in recent years. This article will take Huawei and Bytedance, two well-known companies, as examples to analyze their application cases in the field of Go language and provide specific code examples. Huawei Huawei, as the world's leading provider of information and communication technology solutions, has always been committed to technological innovation and product research and development. In terms of software development, Huawei engineers are also actively trying new technologies, and Go language has become one of their increasingly important choices. 1.Prometh
