
 Technology peripherals
AI
Fall detection, based on skeletal point human action recognition, part of the code is completed with Chatgpt
Technology peripherals
AI
Fall detection, based on skeletal point human action recognition, part of the code is completed with Chatgpt
Fall detection, based on skeletal point human action recognition, part of the code is completed with Chatgpt

Hello, everyone.
Today I would like to share with you a fall detection project, to be precise, it is human movement recognition based on skeletal points.


It is roughly divided into three steps
- Recognize the human body
- Recognize the human skeleton Click
- Action Category
The project source code has been packaged, see the end of the article for how to obtain it.
0. chatgpt
First, we need to obtain the monitored video stream. This code is relatively fixed, we can directly let chatgpt complete

This code written by chatgpt has no problem and can be used directly.
But when it comes to business tasks, such as using mediapipe to identify human skeleton points, the code given by chatgpt is incorrect.
I think chatgpt can be used as a toolbox, which can be independent of business logic. You can try to leave it to chatgpt to complete.
So, I think the requirements for programmers in the future will pay more attention to the ability of business abstraction. Without further ado, let’s get back to the topic.
1. Human body recognition
Human body recognition can use target detection models, such as: YOLOv5. We have also shared many articles on training YOLOv5 models before.
But here I did not use YOLOv5, but mediapipe. Because mediapipe runs faster and runs smoothly on the CPU.
2. Skeleton point recognition
There are many models for recognizing skeleton points, such as alphapose and openpose. The number and position of skeleton points recognized by each model are different. For example, the following two types:

mediapipe 32 bone points

coco 17 bone points
I still use mediapipe for the recognition of bone points. In addition to its fast speed, another advantage is that mediapipe recognizes many bone points, 32 of them, which can meet our needs. Because the classification of human body movements to be used below relies heavily on skeletal points.
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) results = pose.process(image) if not results.pose_landmarks: continue # 识别人体骨骼点 image.flags.writeable = True image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) mp_drawing.draw_landmarks( image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS, landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style() )
3. Action recognition
Action recognition uses a spatio-temporal graph convolutional network based on skeleton action recognition. The open source solution is STGCN (Skeleton-Based Graph Convolutional Networks )
https://github.com/yysijie/st-gcn

A set of actions, such as falling, consists of N frames, each One frame can construct a space graph composed of skeletal point coordinates. The skeletal points are connected between frames to form a time graph. The connection of the skeletal points and the connection of time frames can construct a space-time graph.

Space-time graph
Perform multi-layer graph convolution operations on the space-time graph to generate higher-level feature maps. Then it is input to the SoftMax classifier for action classification (Action Classification).

Graph Convolution
Originally I planned to train the STGCN model, but there were too many pitfalls, so I ended up training it directly with someone else. model.
Pit 1. STGCN supports skeleton points recognized by OpenPose, and there is a dataset Kinetics-skeleton that can be used directly. The pitfall is that the installation of OpenPose is too cumbersome and requires a lot of steps. After struggling, you give up.
Pit 2. STGCN also supports the NTU RGB D data set, which has 60 action categories, such as: standing up, walking, falling, etc. The human body in this data set contains 25 skeletal points, only coordinate data, and the original video is basically unavailable, so there is no way to know which positions these 25 skeletal points correspond to, and what model can be used to identify these 25 skeletal points. Struggle Then give up.
The above two big pitfalls made it impossible to directly train the STGCN model. I found an open source solution, which used alphapose to identify 14 bone points, and modified the STGCN source code to support custom bone points.
https://github.com/GajuuzZ/Human-Falling-Detect-Tracks
我看了下mediapipe包含了这 14 个骨骼点,所以可以用mediapipe识别的骨骼点输入他的模型,实现动作分类。

mediapipe 32个骨骼点

选出14个关键骨骼点
14个骨骼点提取代码:
KEY_JOINTS = [ mp_pose.PoseLandmark.NOSE, mp_pose.PoseLandmark.LEFT_SHOULDER, mp_pose.PoseLandmark.RIGHT_SHOULDER, mp_pose.PoseLandmark.LEFT_ELBOW, mp_pose.PoseLandmark.RIGHT_ELBOW, mp_pose.PoseLandmark.LEFT_WRIST, mp_pose.PoseLandmark.RIGHT_WRIST, mp_pose.PoseLandmark.LEFT_HIP, mp_pose.PoseLandmark.RIGHT_HIP, mp_pose.PoseLandmark.LEFT_KNEE, mp_pose.PoseLandmark.RIGHT_KNEE, mp_pose.PoseLandmark.LEFT_ANKLE, mp_pose.PoseLandmark.RIGHT_ANKLE ] landmarks = results.pose_landmarks.landmark joints = np.array([[landmarks[joint].x * image_w, landmarks[joint].y * image_h, landmarks[joint].visibility] for joint in KEY_JOINTS])
STGCN原始方案构造的空间图只支持openpose18个骨骼点和NTU RGB+D数据集25个骨骼点

修改这部分源码,以支持自定义的14个骨骼点

模型直接使用Human-Falling-Detect-Tracks项目已经训练好的,实际运行发现识别效果很差,因为没有看到模型训练过程,不确定问题出在哪。
有能力的朋友可以自己训练模型试试,另外,百度的Paddle也基于STGCN开发了一个跌倒检测模型,只支持摔倒这一种行为的识别。
当然大家也可以试试Transformer的方式,不需要提取骨骼点特征,直接将 N 帧Fall detection, based on skeletal point human action recognition, part of the code is completed with Chatgpt送入模型分类。
关于STGCN的原理,大家可以参考文章:https://www.jianshu.com/p/be85114006e3 总结的非常好。
需要源码的朋友留言区回复即可。
如果大家觉得本文对你有用就点个 在看 鼓励一下吧,后续我会持续分享优秀的 Python+AI 项目。
The above is the detailed content of Fall detection, based on skeletal point human action recognition, part of the code is completed with Chatgpt. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
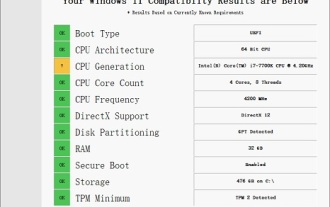 Solution to i7-7700 unable to upgrade to Windows 11
Dec 26, 2023 pm 06:52 PM
Solution to i7-7700 unable to upgrade to Windows 11
Dec 26, 2023 pm 06:52 PM
The performance of i77700 is completely sufficient to run win11, but users find that their i77700 cannot be upgraded to win11. This is mainly due to restrictions imposed by Microsoft, so they can install it as long as they skip this restriction. i77700 cannot be upgraded to win11: 1. Because Microsoft limits the CPU version. 2. Only the eighth generation and above versions of Intel can directly upgrade to win11. 3. As the 7th generation, i77700 cannot meet the upgrade needs of win11. 4. However, i77700 is completely capable of using win11 smoothly in terms of performance. 5. So you can use the win11 direct installation system of this site. 6. After the download is complete, right-click the file and "load" it. 7. Double-click to run the "One-click
 The perfect combination of ChatGPT and Python: creating an intelligent customer service chatbot
Oct 27, 2023 pm 06:00 PM
The perfect combination of ChatGPT and Python: creating an intelligent customer service chatbot
Oct 27, 2023 pm 06:00 PM
The perfect combination of ChatGPT and Python: Creating an Intelligent Customer Service Chatbot Introduction: In today’s information age, intelligent customer service systems have become an important communication tool between enterprises and customers. In order to provide a better customer service experience, many companies have begun to turn to chatbots to complete tasks such as customer consultation and question answering. In this article, we will introduce how to use OpenAI’s powerful model ChatGPT and Python language to create an intelligent customer service chatbot to improve
 How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
Installation steps: 1. Download the ChatGTP software from the ChatGTP official website or mobile store; 2. After opening it, in the settings interface, select the language as Chinese; 3. In the game interface, select human-machine game and set the Chinese spectrum; 4 . After starting, enter commands in the chat window to interact with the software.
 MIT's latest masterpiece: using GPT-3.5 to solve the problem of time series anomaly detection
Jun 08, 2024 pm 06:09 PM
MIT's latest masterpiece: using GPT-3.5 to solve the problem of time series anomaly detection
Jun 08, 2024 pm 06:09 PM
Today I would like to introduce to you an article published by MIT last week, using GPT-3.5-turbo to solve the problem of time series anomaly detection, and initially verifying the effectiveness of LLM in time series anomaly detection. There is no finetune in the whole process, and GPT-3.5-turbo is used directly for anomaly detection. The core of this article is how to convert time series into input that can be recognized by GPT-3.5-turbo, and how to design prompts or pipelines to let LLM solve the anomaly detection task. Let me introduce this work to you in detail. Image paper title: Largelanguagemodelscanbezero-shotanomalydete
 How to develop an intelligent chatbot using ChatGPT and Java
Oct 28, 2023 am 08:54 AM
How to develop an intelligent chatbot using ChatGPT and Java
Oct 28, 2023 am 08:54 AM
In this article, we will introduce how to develop intelligent chatbots using ChatGPT and Java, and provide some specific code examples. ChatGPT is the latest version of the Generative Pre-training Transformer developed by OpenAI, a neural network-based artificial intelligence technology that can understand natural language and generate human-like text. Using ChatGPT we can easily create adaptive chats
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
chatgpt can be used in China, but cannot be registered, nor in Hong Kong and Macao. If users want to register, they can use a foreign mobile phone number to register. Note that during the registration process, the network environment must be switched to a foreign IP.
