

Guest | Wang Qiangqiang
Compilation | Liu Yuyao
In the previous AISummit global artificial intelligence technology conference hosted by 51CTO, Mr. Wang Qiangqiang, the head of the voice team of Zuoyebang, led the audience Here comes the keynote speech "Zuoyebang Speech Technology Practice", which interprets Zuoyebang's speech technology practice from three aspects: speech synthesis, speech evaluation, and speech recognition. The content covers end-to-end implementation in speech recognition, efficient data utilization, and high Correcting speech pronunciation errors in concurrent scenarios, as well as improving the model's factor differentiation and anti-interference capabilities.
In order to allow more students who are interested in voice technology to understand the current development trend and cutting-edge technology practices of voice technology, the content of Teacher Wang Qiangqiang’s speech is now organized as follows, hoping to bring it to you. Some inspiration.
For traditional speech synthesis technology, it takes ten hours or more to completely synthesize a person's voice. Long recording sessions. This is a big challenge for recorders, and few people can maintain good pronunciation for such a long time. Through small data volume speech synthesis technology, we only need to use dozens of sentences and a few minutes of speech spoken by the recorder to achieve a complete speech synthesis effect.
Small data volume speech synthesis technology is roughly divided into two categories. One is for situations where annotation and speech do not match. There are two main processing methods: one is self-supervised learning, which uses self-supervised algorithm learning to obtain the correspondence between the modeling unit and the audio, and then uses the annotation of a specific person to The corpus is Finetune to achieve a better synthesis effect; the second is to identify unlabeled corpus through ASR, and use TTS to synthesize dual functions and dual learning methods to gradually improve the synthesis effect of TTS.
For text and audio matching, the main processing methods are divided into two types: one is to build a multilingual pre-training model with annotated corpus. The other is based on this solution. Multiple speakers in the same language are pre-trained with annotated data, and Finetune is performed using the data of the target speaker to achieve the desired effect.
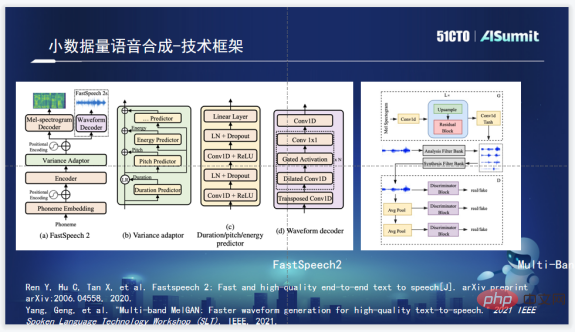
Zuoyebang’s speech synthesis technology framework uses FastSpeech2 in the phoneme part. FastSpeech2 has the main advantage of fast synthesis speed. At the same time, FastSpeech2 also integrates Duration, Pitch, and Energy Predictor, which can provide us with a larger operability space; as for the choice of vocoder, the homework help the voice team choose Multi-Band MelGAN is used because Multi-Band MelGAN has good synthesis effects and is very fast.
After determining the basic framework, the next thing to do is multi-speaker speech synthesis. A common idea for multi-speaker speech synthesis is to add Speaker Embedding information to the Encoder, learn the information of a specific speaker, and then use the model to train a multi-speaker speech synthesis model. Finally, use specific speakers to perform some simple Finetune. This solution can compress ten hours of recording needs to about one hour, but in practice, it is still difficult to collect one-hour recordings that can meet the model training standards. The goal of small-data speech synthesis is essentially to use fewer sounds to synthesize a relatively good sound.
Therefore, the Zuoyebang voice team learned from the winning solution of the M2VOC competition, and finally chose the combination of D-Vector and ECAPA-based Speaker Embedding, and carried out triple upgrades, including the upgrade of Speaker Embedding; using FastSpeech2 Transformer is upgraded to Conformer; and Speaker information is added to LayerNorm.

Zuoyebang’s basic technology framework for voice assessment essentially uses GOP scoring Determine how well the user pronounces words or sentences. But in terms of models, it has been upgraded to Conformer and CGC attention-based, a complete end-to-end model training process. GOP is very dependent on sounds and phonemes, that is, the degree of alignment of the modeling units, so when training the model, we added the alignment information of the corpus obtained through the GMM model. Through a fully certified model and aligned corresponding information, a very effective model can be trained. Combining the strengths of both ensures that the score of the GOP is relatively accurate.
The evaluation scenario is naturally sensitive to delay, so delay and network are the two major issues in the implementation of the GOP evaluation system. If the latency is high and the real-time performance is poor, the overall user experience will be greatly affected. In addition, if there is a problem with the network and the user's network environment fluctuates, coupled with the network delay, it is easy for the user's perceived coloring time to exceed one second, which will cause a very obvious feeling of stagnation, seriously affecting the entire course effect. Influence.
For the above problems, the problem of delay and excessive memory can be solved algorithmically through Chunk Mask. Chunk looks up to two frames forward and up to five frames backward, and the delay problem is solved.
When the real algorithm is tested in practice, its hard delay is only about 50 milliseconds, which means that the word will be activated in basically 50 milliseconds. 50 milliseconds is very fast in human perception. So at least at the algorithm level, the problem of hard delay is solved. This is the first level of work we do.
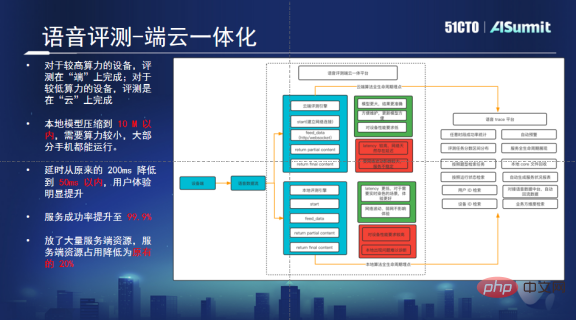
A device-cloud integrated platform can solve problems caused by high concurrency and network transmission. This platform can automatically determine whether the user’s mobile phone has sufficient computing power. If there are enough, local reviews will be prioritized. If the computing power is not enough, the request will be sent to the cloud, and the cloud will perform the evaluation. If there is any problem locally, its life cycle is also controlled.
Through this solution, we have solved the problems caused by instantaneous high concurrency. Since part of the computing power is transferred to the end, the cloud only needs to retain 20% of the original machines to achieve normal operations. This Greatly save resources. In addition, after localizing the algorithm, the delay problem has also been solved, which can provide good support for large-scale evaluation tasks and bring users a better audio-visual experience.
The background of the demand for pronunciation error correction is contextual issues and the scarcity of educational resources. Similarly, this pain point can be solved using assessment technology. By optimizing the assessment technology, we can determine whether the pronunciation is correct and identify where there are problems with pronunciation.
In terms of technology selection, although the evaluation system is a stable evaluation scheme based on the GOP, the GOP scheme relies heavily on the alignment of the audio and modeling units. If the starting time is inaccurate, the deviation will be relatively large. Discrimination will become worse. Therefore, the original plan is not suitable for this kind of sound correction scenario. Moreover, the idea of GOP is to use some expert knowledge to correct and guide pronunciation. Missing and adding pronunciation in correcting pronunciation will be very painful for GOP to deal with and require too much manual support. This requires a more flexible solution, so we finally chose the ASR solution for pronunciation error correction.
The great advantage of the ASR scheme is that the training process is simple and does not require too much alignment information. Even if the pronunciation is wrong, it will not have much impact on the discrimination of contextual phonemes. ASR handles additional reading and missed reading, and has natural theoretical and technical advantages. So we finally chose a pure end-to-end ASR model as the technical base for our pronunciation error correction.
At the same time, Zuoyebang has also done some optimization and innovation work on this basis. First, a priori text information is added to model training through the Attention module; second, errors are simulated through random replacement to train the model so that it has error correction capabilities; third, because the model is not sufficiently differentiated, we Errors are layered, and some minor errors will not be judged wrong. Through the above solution, the false alarm rate was finally reduced significantly, while ensuring that the loss of recall rate was not particularly large, and the accuracy of diagnosis was also improved.
The speech recognition technology framework of Zuoyebang is an end-to-end speech recognition framework, compared with the original HMM-GMM/DNN The solution has very obvious advantages: first, it avoids many complex clustering operations and alignment operations; second, the training process is slightly simpler; third, the end-to-end framework does not require manual generation of pronunciation dictionaries; fourth, it can learn at the same time To phoneme information and sequence information, it is equivalent to learning acoustic models and language models together.
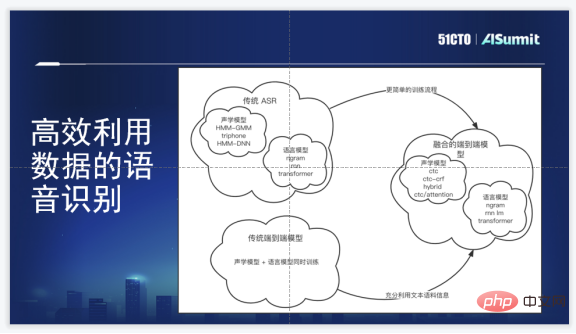
Of course, its disadvantages are also obvious. It is difficult for the end-to-end model to utilize more speech or text data at the beginning, and the cost of labeling corpus is very high. Our requirement is that the internal selection must achieve the goal of having an end-to-end generation model, keeping up with the latest algorithms, and being able to fuse corpus model information.
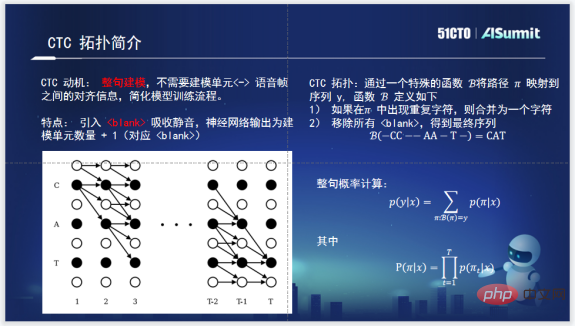
When it comes to CTC-CRF, you need to know CTC first. CTC was born for modeling the entire sentence. After the emergence of CTC, training the acoustic model of the entire sentence no longer requires alignment between phonemes and audio. The topology of CTC, on the one hand, introduces a Blank to absorb silence, which can absorb the silence outside the real effective modeling unit. On the other hand, when it calculates the probability of the entire sentence, it uses a dynamic programming algorithm based on π to keep the path of the entire sentence within a relatively reasonable scale, which can greatly reduce the amount of calculation. This is very groundbreaking work by CTC.

The CTC-CRF speech recognition system used internally by Zuoyebang. Understand the formula and fit the probability of the entire sentence through CRF. The probability of the entire sentence is a sequence whose input is X and the output is π (π is represented by the topology of CTC above), so it is called CTC-CRF.
The most important thing about CRF is the potential function and the entire planning of the potential function. The potential function is the conditional probability that the input is X and the output is πt, plus the probability of a whole sentence. They actually correspond to the nodes and edges in CRF.
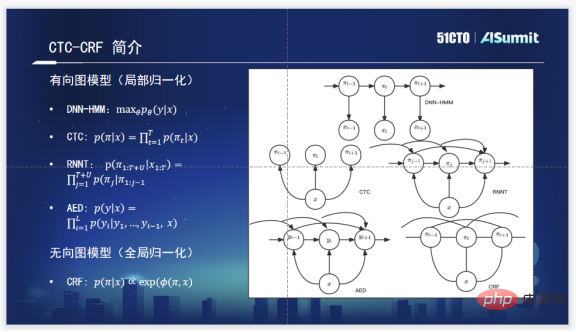
There are certain differences between CTC-CRF and commonly used acoustic model ideas. Commonly used acoustic models include the following four DNN-HMM, CTC, RNNT, and AED.
The basic conditional probability model of RNNT is the probability of input X and output Y. The fitting goal is maxθ and its parameters to maximize this probability.
CTC As shown in the figure, one assumption of CTC is obvious, which is the conditional independence assumption. There is no connection between its states and the conditional probability relationship between them is not considered.
RNNT considers the conditional probabilities of the current state and all historical states, as can be clearly seen in the figure. The same is true for AED, which considers the conditional probability of the current state and the historical state.
But CTC-CRF is not actually a local normalization model based on conditional probability. It is a model of whole sentence normalization and a global normalization model. So we see that it not only depends on history, but also on the future. It can actually consider the probability information of the entire sentence. This is their biggest theoretical difference.
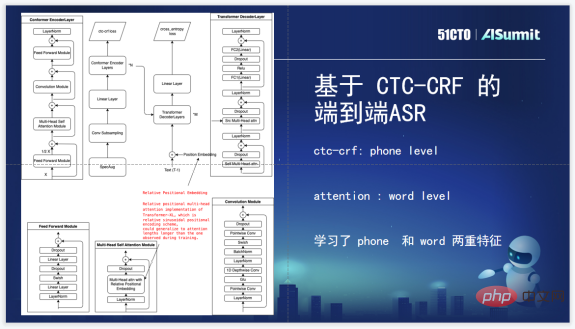
We use CTC-CRF first in the Loss layer, which is a standard Encoder and Decoder currently used, and then add CTC-CRF and Loss to train acoustics Model, end-to-end acoustic model process. The Loss layer uses CTC-CRF Loss instead of the original CTC Loss. CTC-CRF is modeled at the Phone level, but here at Attention, our Attention is made with Word-level modeling in mind. Two features of Phone and Word levels are used to train the model.
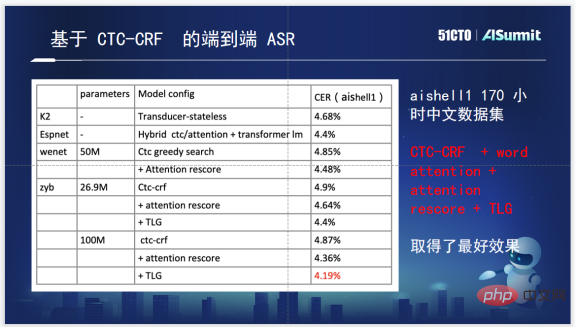
Finally, regarding the specific effects, this is the effect of several open source tools on the Aishell1 test set, and the number of parameters is also marked. It can be seen that the one based on CTC-CRF has relatively advantages.
With the algorithm, the theoretical effect is also very good. Looking at the business side, the business side is still different, but all business sides have a common appeal, which is to achieve optimal efficiency. In order to solve this problem, there is a hot word solution. The hot word solution can perfectly solve this problem and quickly identify the words that the business side wants to identify.
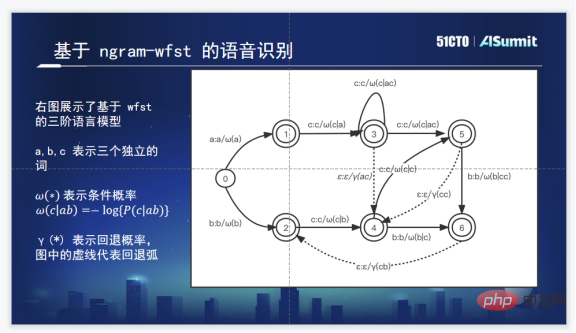
#A common hot word solution is to add the expanded directed graph of hot words to TLG. The above picture is the WFST decoding diagram of a common three-level Ngram. The solid line represents the conditional probability and the dotted line is the backoff probability.
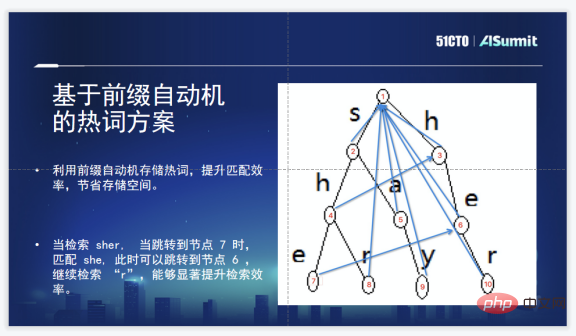
Zhuoyebang’s solution is a hot word solution based on prefix automata. This is because the scale of hot words is so large that it will create an efficiency bottleneck. It is very suitable to use prefix automata to solve the problem of matching multi-pattern strings, especially for a string that hits, covers, or covers a hot word in the hot word list. A sequence such as sher covers two hot words, she and her. In this prefix automaton scheme, after retrieving she, you can jump directly to her, and you can quickly find multiple hot words contained in the string. word. The conclusion is that this solution is fast enough and can save some storage space.

There are also some problems when this solution is actually used. Building a prefix tree still requires traversing the entire prefix tree, which is relatively expensive. Because hot words need to be added in real time, they can be added at any time and take effect at any time. In order to solve this problem, we finally made one or two trees, one is an ordinary prefix tree, and the other is a prefix automaton. That is, user hot words are added to the ordinary prefix tree. The ordinary prefix tree will take effect immediately, which is equivalent to being online at any time. , hot words can be activated. After exceeding a threshold, the prefix automaton will be automatically constructed, thus basically meeting the demands of a group of users.
The above is mainly through three directions, one to two points in each direction. This technical decryption method sorts out the implementation of Zuoyebang’s voice technology and the implementation process during the implementation. The problems encountered, and how to finally output a solution that can relatively meet the needs of the business side.
But in addition to these three points, the voice group has also accumulated a lot of atomic abilities of voice. The evaluation level is very detailed, and even increased reading, missing reading, continuous reading, voiced, accent, rising and falling tones are all done. The recognition also adds Chinese and English mixed recognition, voiceprint, noise reduction, and age discrimination.
With these atomic capabilities, the algorithm level will be more comfortable in supporting and serving the business side.
Wang Qiangqiang, head of the speech technology team of Zuoyebang. Before joining Zuoyebang, he worked in the Speech Processing and Machine Intelligence Laboratory of the Department of Electronic Engineering at Tsinghua University, where he was responsible for implementing speech recognition algorithms and building industrial-grade solutions. Joined Zuoyebang in 2018 and is responsible for the research and implementation of speech-related algorithms. He has led the implementation of speech recognition, evaluation, synthesis and other algorithms in Zuoyebang, providing the company with a complete set of voice technology solutions.
The above is the detailed content of Zuoyebang voice technology practice. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 What currency is STAKE?
What currency is STAKE?
 serverguide installation tutorial
serverguide installation tutorial
 What does write refer to in python?
What does write refer to in python?
 Oracle view table operation history
Oracle view table operation history
 The running environment of java program
The running environment of java program
 Interview assessment tools
Interview assessment tools
 How to solve the problem that win11 antivirus software cannot be opened
How to solve the problem that win11 antivirus software cannot be opened








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



