

Translator | Zhu Xianzhong
Reviewer | Sun Shujuan

Red Vineyard (Author: Vincent van Gogh)
According to the New York Times, 90% of energy in data centers is wasted because most of the data collected by companies is never analyzed or used in any form. More specifically, this is called "Dark Data."
"Dark data" refers to data obtained through various computer network operations but not used in any way to derive insights or make decisions. An organization's ability to collect data may exceed its throughput of analyzing it. In some cases, organizations may not even know that data is being collected. IBM estimates that approximately 90% of data generated by sensors and analog-to-digital conversion is never used. — Wikipedia definition of “dark data” One of the key reasons why this data is not useful for drawing any insights from a machine learning perspective is the lack of labels. This makes unsupervised learning algorithms very attractive for mining the potential of this data.
Generative Adversarial Network
This paper sets a very important milestone in the field of modern machine learning and opens up a new way for unsupervised learning. In 2015, the deep convolutional GAN paper released by Radford et al. successfully generated 2D images by applying the principles of convolutional networks, thus continuing to build on this idea in the paper.
Through this article, I try to explain the key components discussed in the above paper and implement them using the PyTorch framework. What are the compelling aspects of GAN?
In order to understand the importance of GANs or DCGANs (Deep Convolutional Generative Adversarial Networks), let’s first understand what makes them so popular.
2. Generators and discriminators act as very good feature extractors for use cases with limited labeled data, or generate additional data to improve quadratic model training, as they can generate fake samples instead Use augmentation techniques.
3. GANs provide an alternative to maximum likelihood techniques. Their adversarial learning process and non-heuristic cost function make them very attractive for reinforcement learning.
4. The research on GAN is very attractive, and its results have caused widespread debate about the impact of ML/DL. For example, Deepfake is an application of GAN that overlays a person's face on a target person, which is very controversial in nature because it has the potential to be used for nefarious purposes.
5. Last but not least, working with this kind of network is cool and all the new research in this area is fascinating.
Overall Architecture
Architecture of Deep Convolutional GAN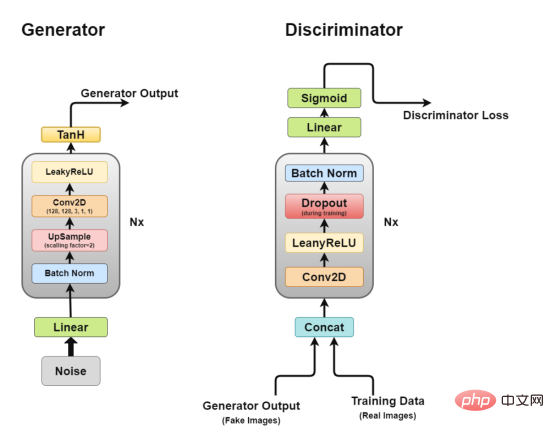 As we discussed earlier, we will work through DCGAN, DCGAN Trying to implement the core idea of GAN, a convolutional network for generating realistic images.
As we discussed earlier, we will work through DCGAN, DCGAN Trying to implement the core idea of GAN, a convolutional network for generating realistic images.
DCGAN consists of two independent models: a generator (G) that tries to model random noise vectors as input and tries to learn the data distribution to generate fake samples, and a discriminator (D) that gets the training data (real samples) and generated data (fake samples) and try to classify them. The struggle between these two models is what we call an adversarial training process, where one party's loss is the other's gain.
Generator
Generator architecture diagram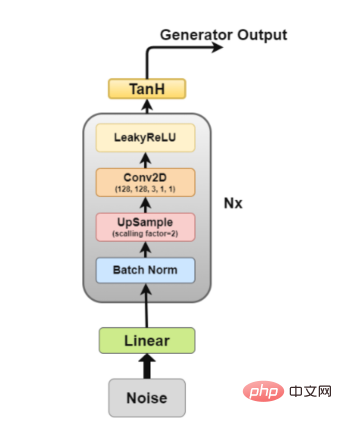 The generator is the part we are most interested in because it is a generator that generates fake images to try to fool the discriminator.
The generator is the part we are most interested in because it is a generator that generates fake images to try to fool the discriminator.
Now, let’s look at the generator architecture in more detail.
Among them, layer 2 to layer 5 constitute the core generator block, which can be repeated N times to obtain the desired output image shape.
The following is the key code of how we implement it in PyTorch (for the complete source code, see the address https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
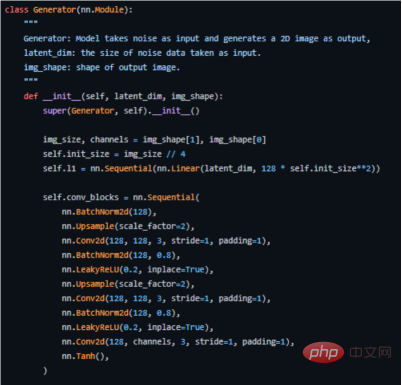
Use the generator of the PyTorch framework to implement the key code
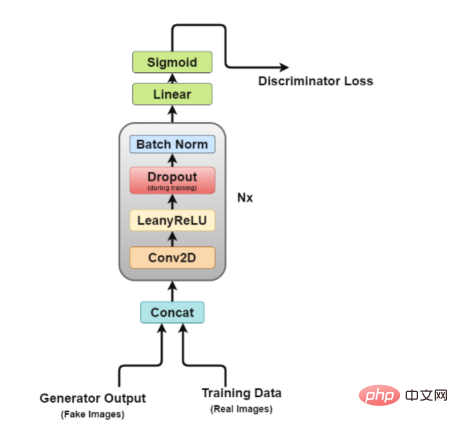
Discriminator architecture Figure
It is easy to see from the figure that the discriminator is more like an image classification network, but with some minor adjustments. For example, instead of using any pooling layers for downsampling, it uses a special convolutional layer called a stride convolutional layer, which allows it to learn its own downsampling.
Now, let’s take a closer look at the discriminator architecture.
In this architecture, layer 2 to layer 5 form the core block of the discriminator, and the calculation can be repeated N times to make the model more complex for each training data.
Here's how we implement it in PyTorch (for the complete source code, see the address https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
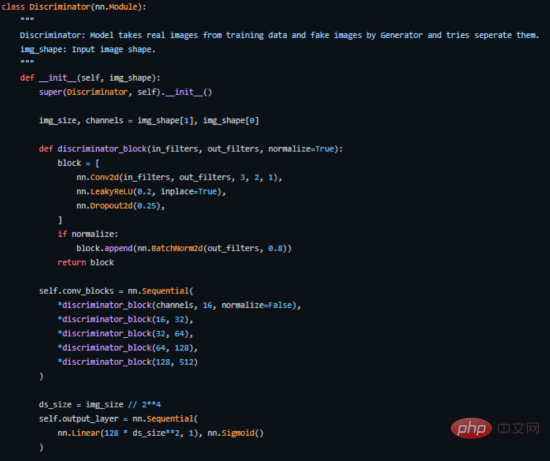
Key code part of the discriminator implemented with PyTorch
We train the discriminator (D) to maximize the correct The probability that a label is assigned to a training sample and a sample from the generator (G), which can be done by minimizing log(D(x)). We simultaneously train G to minimize log(1 − D(G(z))), where z represents the noise vector. In other words, both D and G use the value function V (G, D) to play the following two-player minimax game:
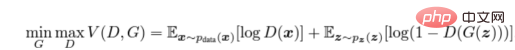
Adversarial cost function calculation formula
In a practical application environment, the above equation may not provide enough gradients for G to learn well. In the early stages of learning, when G is poor, D can reject samples with high confidence because they are significantly different from the training data. In this case, the log(1 − D(G(z))) function reaches saturation. Instead of training G to minimize log(1 − D(G(z))), we train G to maximize logD(G(z)). This objective function generates the same fixed points for dynamic G and D, but provides stronger gradient calculations early in learning. ——arxiv paper
This can be tricky since we are training two models at the same time, and GANs are notoriously difficult to train, which we will discuss later One of the known issues is called mode collapse.
The paper recommends using the Adam optimizer with a learning rate of 0.0002. Such a low learning rate indicates that GANs tend to diverge very quickly. It also uses first- and second-order momentum with values of 0.5 and 0.999 to further speed up training. The model is initialized to a normal weighted distribution with a mean of zero and a standard deviation of 0.02.
The following shows how we implement a training loop for this (see https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py for the complete source code).
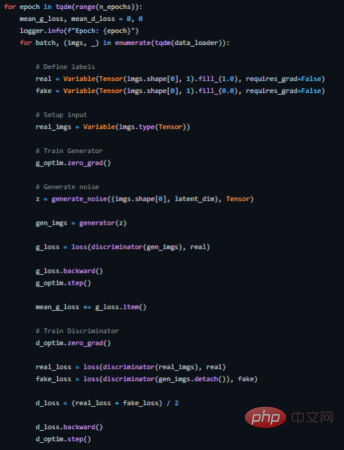
DCGAN’s training loop
Ideally, we want the generator to produce a variety of outputs. For example, if it generates faces, it should generate a new face for every random input. However, if the generator produces sufficiently good enough plausible output to fool the discriminator, it may produce the same output over and over again.
Eventually, the generator will over-optimize a single discriminator and rotate between a small set of outputs, a situation called "mode collapse".
The following methods can be used to correct the situation.
In short, the paper on GAN and DCGAN mentioned above is simply a landmark paper, because it opened up a new chapter in unsupervised learning. A new way. The adversarial training method proposed in it provides a new method for training models that closely simulate the real-world learning process. So it will be very interesting to see how this field develops.
Finally, you can find the complete implementation source code of the sample project in this article on my GitHub source code repository. Translator Introduction
Implementing Deep Convolutional GAN, author: Akash Agnihotri
The above is the detailed content of Deep convolutional generative adversarial network in practice. For more information, please follow other related articles on the PHP Chinese website!
 How to bind data in dropdownlist
How to bind data in dropdownlist
 How to trade VV coins
How to trade VV coins
 What are the levels of mobile user star ratings?
What are the levels of mobile user star ratings?
 Solution to failedtofetch error
Solution to failedtofetch error
 Why is there no signal on the monitor after turning on the computer?
Why is there no signal on the monitor after turning on the computer?
 What are the differences between cellpadding and cellspacing?
What are the differences between cellpadding and cellspacing?
 python configure environment variables
python configure environment variables
 Commonly used search tools
Commonly used search tools








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



