

Scaling spherical deep learning to high-resolution input data

Translator | Zhu Xianzhong
Reviewer | Sun Shujuan
Traditional spherical CNN cannot be extended to high-resolution classification Task. In this paper, we introduce spherical scattering layers, a new type of spherical layer that can reduce the dimensionality of input data while retaining relevant information, and also has rotational equivariance properties.
Scattering networks work by using predefined convolution filters from wavelet analysis, rather than learning convolution filters from scratch. Since the scattering layer's weights are specifically designed rather than learned, the scattering layer can be used as a one-time preprocessing step, thereby reducing the resolution of the input data. Our previous experience shows that spherical CNNs equipped with an initial scattering layer can scale to resolutions of tens of millions of pixels, a feat that was previously unachievable with traditional spherical CNN layers.
Traditional spherical deep learning methods require calculation
Spherical CNN (document 1, 2, 3) is very useful for solving many different types of problems in machine learning , because many of these problems have data sources that cannot be naturally represented on a plane (for an introductory introduction to this, see our previous article at : https://towardsdatascience.com/geometric- deep-learning-for-spherical-data-55612742d05f).
A key feature of spherical CNNs is that they are equivariant to the rotation of spherical data (in this article, we focus on rotation equivariant methods). In practice, this means that spherical CNNs have impressive generalization properties, allowing them to do things like classify meshes of 3D objects regardless of how they are rotated (and whether they see the mesh during training different rotations).
We described## in recent published articles #KagenovaTeamA series of developments developed to improve the computational efficiency of spherical CNNAchievements(Reference address : https://towardsdatascience.com/efficient-generalized-spherical-cnns-1493426362ca). The method we adopted - efficient generalized spherical CNN - both retains the traditionThe equal variance characteristics of spherical CNN also make the calculation efficiency higher (Document 1). However, despite these advances in computational efficiency, spherical CNNs are still limited to relatively low-resolution data. This means that , Spherical CNNis currently not able to be applied to agitation that typically involves higher resolution data # in the application scenarios , such as cosmological data analysis and 360-degree computer vision of virtual reality and other fields. In a recently published article, we introduced the spherical scattering layer network to flexibly adjust the efficient general spherical CNN 来Improve the resolution (document 4), in this article we will review the content. Hybrid approach to support high-resolution input data
While developing an efficient universal spherical CNN (Reference 1), we discovered a very effective way to construct a sphere A hybrid approach to CNN architecture. Hybrid Spherical CNN can use different styles of spherical CNN layers in the same network, allowing developers to get the benefits of different types of layers at different stages of processing.
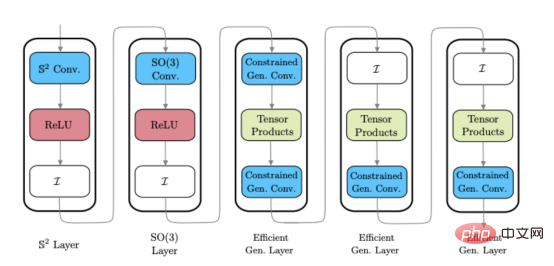 The above picture shows an example of a hybrid spherical CNN architecture (please note: these layers are not a single one, but some different styles of spherical CNN layers ).
The above picture shows an example of a hybrid spherical CNN architecture (please note: these layers are not a single one, but some different styles of spherical CNN layers ).
Scattering Networks on Spheres continues this hybrid approach and introduces a new spherical CNN layer that can be plugged into existing spherical architectures. In order to extend the efficient general spherical CNN to higher dimensions, this new layer needs to have the following characteristics:
- Scalability with computational support
- Blending information to low frequencies to allow subsequent layers to run at lower resolutions
- Rotation Equivariance
- Provides stability and locally invariant representation (i.e., providing an efficient representation space)
# We determined that the scattering network layer has the potential to satisfy all of these characteristics enumerated above.
Scattering network on the sphere
The scattering network first proposed by Mallat (Reference 5) in the Euclidean environment can be regarded as having fixed convolution filtering For CNNs, these filters are derived from wavelet analysis. Scattering networks have proven to be very useful for traditional (Euclidean) computer vision, especially when data is limited - where learning convolutional filters is difficult. Next, we briefly discuss the inner workings of scattering network layers, how they meet the requirements defined in the previous section, and how they can be developed for spherical data analysis.
Data processing within the scattering layer is performed by three basic operations. The first building block is the fixed wavelet convolution, which is similar to the normal learning convolution used in Euclidean CNN. After wavelet convolution, the scattering network applies a modular nonlinear approach to the resulting representation. Finally, scattering utilizes a scaling function that performs a local averaging algorithm with some similarities to the pooling layers in ordinary CNNs. Repeated application of these three building blocks scatters the input data into a computational tree and extracts the resulting representation (similar to a CNN channel) from the tree at different stages of processing. A simplified schematic of these operations is shown below.
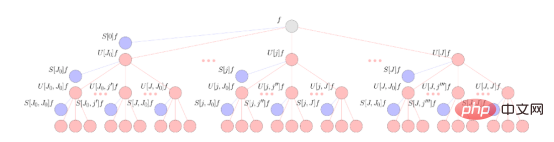
This figure illustrates the spherical scattering network of the spherical signal f. The signal is propagated via a cascaded spherical wavelet transform combined with an absolute value activation function represented by red nodes. The output of the scattering network is obtained by projecting these signals onto a spherical wavelet scaling function, resulting in the scattering coefficients represented by blue nodes.
From a traditional deep learning perspective, the operation of decentralized networks can seem a bit obscure. However, each computational operation described has a specific purpose - aiming to exploit the reliable theoretical results of wavelet analysis.
Wavelet convolutions in scattering networks are carefully derived to extract relevant information from the input data. For example, for natural images, wavelets are defined to specifically extract information related to edges at high frequencies and general shapes of objects at low frequencies. Therefore, in a planar setting, scatter network filters may have some similarities with traditional CNN filters. The same applies to the spherical setting, where we use scale-discretised wavelets (see Ref. 4 for details).
Since the wavelet filter is fixed, the initial scattering layer only needs to be applied once and does not need to be applied repeatedly throughout the training process (such as the initial layer in traditional CNN). This makes the scattering network computationally scalable, meeting the requirements of Feature 1 above. Furthermore, the scattering layer reduces the dimensionality of its input data, which means that only limited storage space needs to be used to cache the scattering representation when training downstream CNN layers.
Wavelet convolution is followed by a modular nonlinear method. First, this injects non-linear characteristics into the neural network layers. Secondly, the modulus operation mixes the high-frequency information in the input signal into the low-frequency data to meet the above requirement 2. The figure below shows the frequency distribution of the wavelet representation of the data before and after the modulus nonlinear calculation.
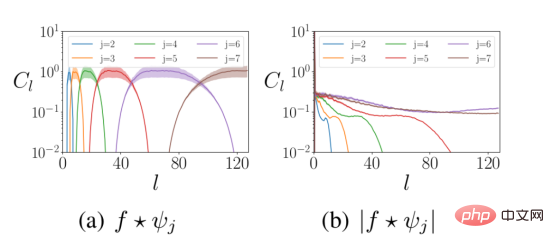
The above figure shows the distribution of wavelet coefficients at different spherical frequencies l before and after modular operation. Energy in the input signal moves from high frequencies (left panel) to low frequencies (right panel). where f is the input signal and Ψ represents the wavelet of scaling j.
After applying the modulus calculation, project the resulting signal onto the scaling function. The scaling function extracts low-frequency information from the representation results, similar to the pooling function operation in traditional CNN.
We empirically tested the theoretical equal variance properties of spherical scattering networks. The test is performed by rotating the signal and feeding it through the scattering network, and then comparing the resulting representation to the resulting representation of the input data after passing through the scattering network and then performing the rotation calculation. It can be demonstrated from the data in the table below that the equal variance error for a given depth is low, thus meeting the above requirement 3 (usually in practice, one path depth will not exceed the depth of two paths, because most of the signal energy has already been captured) .
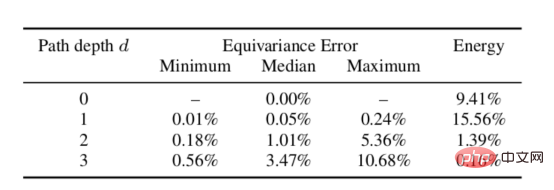
Rotation equal variance error of spherical scattering network with different depths
Finally, it is theoretically proved Euclidean scattering networks are stable to small differentials or distortions(Documentation5). Currently, this result has been extended to the scattering network on the compact Riemannian manifold (document 6), especially the spherical surface Environment (Documentation4). In practice, stability to disparity morphology means that the representation computed by the scattering network will not differ significantly if the input is slightly changed (for a discussion of the role of stability in geometric deep learning, see our previous Post , address is https://towardsdatascience.com/a-brief-introduction-to-geometric-deep-learning-dae114923ddb). Thus, scattering networks provide a well-performing representation space on which subsequent learning can be efficiently performed, satisfying requirement 4 above.
Scalable and rotationally equivariant spherical CNN
Considering that the introduced scattering layer satisfies all our desired properties, next we are ready to integrate them into our of hybrid spherical CNN. As mentioned before, the scattering layer can be fixed onto the existing architecture as an initial pre-processing step to reduce the size of the representation for subsequent spherical layer processing.
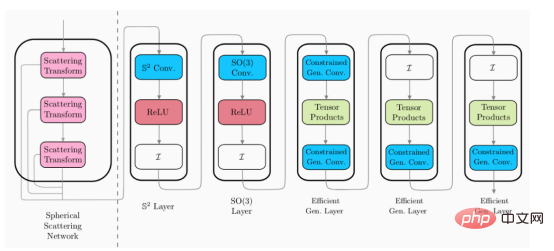
In the image above, the scattering layer module (left of the dotted line) is a design layer. This means, it does not require training, while the remaining layers (right of the dotted line) are trainable. Therefore, this means that the scattering layer can be applied as a one-time preprocessing step to reduce the dimensionality of the input data.
Since scatter networks have a fixed representation of a given input, scatter network layers can be applied once to the entire dataset at the beginning of training and the resulting low-dimensional representation is cached to train subsequent layers . Fortunately, scatter representations have reduced dimensionality, which means that the disk space required to store them is relatively low. Due to the existence of this new spherical scattering layer, the efficient generalized spherical CNN can be extended to the domain of high-resolution classification problems.
Classification of cosmic microwave background anisotropy
How is matter distributed throughout the universe? This is a fundamental research question for cosmologists and has significant implications for theoretical models of the origin and evolution of our universe. The cosmic microwave background (CMB) - remnant energy from the Big Bang - maps the distribution of matter in the universe. Cosmologists observe the CMB on the celestial sphere, which requires computational methods that enable cosmological analysis within the celestial sphere.
Cosmologists are very interested in methods to analyze the cosmic microwave background because these methods can detect non-Gaussian properties in the distribution of the cosmic microwave background throughout space, which has important implications for theories of the early universe. of great significance. This analysis method also needs to be able to scale to astronomical resolution. We demonstrate that our scattering network meets these requirements by classifying CMB simulations as Gaussian or non-Gaussian with a resolution of L = 1024. The scattering network successfully classified these simulations with 95.3% accuracy, which is much better than the 53.1% achieved by the low-resolution traditional spherical CNN.
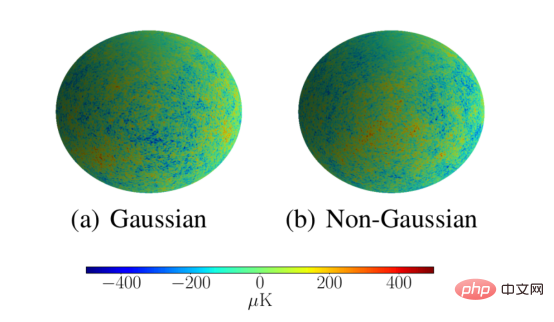
The above figure gives high-resolution simulation examples of Gaussian and non-Gaussian-like CMBs, which are used to evaluate the expansion of the spherical scattering network to high resolution. ability.
Summary
In this paper, we explored the ability of spherical scattering layers to compress the dimensionality of their input representations while still retaining important information for downstream tasks. We have shown that this makes scattering layers very useful for high-resolution sphere classification tasks. This opens the door to previously intractable potential applications such as cosmological data analysis and high-resolution 360 image/video classification. However, many computer vision problems such as segmentation or depth estimation that require dense predictions require both high-dimensional output and high-dimensional input. Finally, how to develop controllable spherical CNN layers that can increase the dimensionality of the output representation while maintaining equal variance is a current topic of research by Kagenova developers. These will be covered in the next article.
References
[1]Cobb, Wallis, Mavor-Parker, Marignier, Price, d'Avezac, McEwen, Efficient Generalized Spherical CNNs, ICLR (2021) , arXiv:2010.11661
[2] Cohen, Geiger, Koehler, Welling, Spherical CNNs, ICLR (2018), arXiv:1801.10130
[3] Esteves, Allen-Blanchette, Makadia, Daniilidis, Learning SO(3) Equivariant Representations with Spherical CNNs, ECCV (2018), arXiv:1711.06721
[4] McEwen, Jason , Wallis, Christopher and Mavor-Parker, Augustine N., Scattering Networks on the Sphere for Scalable and Rotationally Equivariant Spherical CNNs, ICLR (2022), arXiv:2102.02828
[5] Bruna , Joan, and Stéphane Mallat, Invariant scattering convolution networks, IEEE Transaction on Pattern Analysis and Machine Intelligence (2013)
[6] Perlmutter, Michael, et al., Geometric wavelet scattering networks on compact Riemannian manifolds, Mathematical and Scientific Machine Learning. PMLR (2020), arXiv:1905.10448
Translator introduction
Zhu Xianzhong, 51CTO community editor, 51CTO expert blog, Lecturer, computer teacher at a university in Weifang, and a veteran in the freelance programming industry.
Original title: Scaling Spherical Deep Learning to High-Resolution Input Data, Author: Jason McEwen, Augustine Mavor-Parker
The above is the detailed content of Scaling spherical deep learning to high-resolution input data. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
In today's wave of rapid technological changes, Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL) are like bright stars, leading the new wave of information technology. These three words frequently appear in various cutting-edge discussions and practical applications, but for many explorers who are new to this field, their specific meanings and their internal connections may still be shrouded in mystery. So let's take a look at this picture first. It can be seen that there is a close correlation and progressive relationship between deep learning, machine learning and artificial intelligence. Deep learning is a specific field of machine learning, and machine learning
 Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Almost 20 years have passed since the concept of deep learning was proposed in 2006. Deep learning, as a revolution in the field of artificial intelligence, has spawned many influential algorithms. So, what do you think are the top 10 algorithms for deep learning? The following are the top algorithms for deep learning in my opinion. They all occupy an important position in terms of innovation, application value and influence. 1. Deep neural network (DNN) background: Deep neural network (DNN), also called multi-layer perceptron, is the most common deep learning algorithm. When it was first invented, it was questioned due to the computing power bottleneck. Until recent years, computing power, The breakthrough came with the explosion of data. DNN is a neural network model that contains multiple hidden layers. In this model, each layer passes input to the next layer and
 AlphaFold 3 is launched, comprehensively predicting the interactions and structures of proteins and all living molecules, with far greater accuracy than ever before
Jul 16, 2024 am 12:08 AM
AlphaFold 3 is launched, comprehensively predicting the interactions and structures of proteins and all living molecules, with far greater accuracy than ever before
Jul 16, 2024 am 12:08 AM
Editor | Radish Skin Since the release of the powerful AlphaFold2 in 2021, scientists have been using protein structure prediction models to map various protein structures within cells, discover drugs, and draw a "cosmic map" of every known protein interaction. . Just now, Google DeepMind released the AlphaFold3 model, which can perform joint structure predictions for complexes including proteins, nucleic acids, small molecules, ions and modified residues. The accuracy of AlphaFold3 has been significantly improved compared to many dedicated tools in the past (protein-ligand interaction, protein-nucleic acid interaction, antibody-antigen prediction). This shows that within a single unified deep learning framework, it is possible to achieve
 How to use CNN and Transformer hybrid models to improve performance
Jan 24, 2024 am 10:33 AM
How to use CNN and Transformer hybrid models to improve performance
Jan 24, 2024 am 10:33 AM
Convolutional Neural Network (CNN) and Transformer are two different deep learning models that have shown excellent performance on different tasks. CNN is mainly used for computer vision tasks such as image classification, target detection and image segmentation. It extracts local features on the image through convolution operations, and performs feature dimensionality reduction and spatial invariance through pooling operations. In contrast, Transformer is mainly used for natural language processing (NLP) tasks such as machine translation, text classification, and speech recognition. It uses a self-attention mechanism to model dependencies in sequences, avoiding the sequential computation in traditional recurrent neural networks. Although these two models are used for different tasks, they have similarities in sequence modeling, so
 TensorFlow deep learning framework model inference pipeline for portrait cutout inference
Mar 26, 2024 pm 01:00 PM
TensorFlow deep learning framework model inference pipeline for portrait cutout inference
Mar 26, 2024 pm 01:00 PM
Overview In order to enable ModelScope users to quickly and conveniently use various models provided by the platform, a set of fully functional Python libraries are provided, which includes the implementation of ModelScope official models, as well as the necessary tools for using these models for inference, finetune and other tasks. Code related to data pre-processing, post-processing, effect evaluation and other functions, while also providing a simple and easy-to-use API and rich usage examples. By calling the library, users can complete tasks such as model reasoning, training, and evaluation by writing just a few lines of code. They can also quickly perform secondary development on this basis to realize their own innovative ideas. The algorithm model currently provided by the library is:
 Explore the algorithms and principles of gesture recognition models (create a simple gesture recognition training model in Python)
Jan 24, 2024 pm 05:51 PM
Explore the algorithms and principles of gesture recognition models (create a simple gesture recognition training model in Python)
Jan 24, 2024 pm 05:51 PM
Gesture recognition is an important research area in the field of computer vision. Its purpose is to determine the meaning of gestures by parsing human hand movements in video streams or image sequences. Gesture recognition has a wide range of applications, such as gesture-controlled smart homes, virtual reality and games, security monitoring and other fields. This article will introduce the algorithms and principles used in gesture recognition models, and use Python to create a simple gesture recognition training model. Algorithms and principles used in gesture recognition models The algorithms and principles used in gesture recognition models are diverse, including models based on deep learning, traditional machine learning models, rule-based methods and traditional image processing methods. The principles and characteristics of these methods will be introduced below. 1. Model deep learning based on deep learning
 Why Transformer replaced CNN in computer vision
Jan 24, 2024 pm 09:24 PM
Why Transformer replaced CNN in computer vision
Jan 24, 2024 pm 09:24 PM
Transformer and CNN are commonly used neural network models in deep learning, and their design ideas and application scenarios are different. Transformer is suitable for sequence data tasks such as natural language processing, while CNN is mainly used for spatial data tasks such as image processing. They have unique advantages in different scenarios and tasks. Transformer is a neural network model for processing sequence data, which was originally proposed to solve machine translation problems. Its core is the self-attention mechanism, which captures long-distance dependencies by calculating the relationship between various positions in the input sequence, thereby better processing sequence data. Transformer model is solved by the encoder
