
 Technology peripherals
AI
Regression meta-learning, few-sample target detection based on variational feature aggregation to achieve new SOTA
Technology peripherals
AI
Regression meta-learning, few-sample target detection based on variational feature aggregation to achieve new SOTA
Regression meta-learning, few-sample target detection based on variational feature aggregation to achieve new SOTA

Different from traditional object detection problems, few-shot object detection (FSOD) assumes that we have many basic class samples, but only a small number of novel class samples. The goal is to study how to transfer knowledge from basic classes to novel classes, thereby improving the detector's ability to recognize novel classes.
FSOD usually follows a two-stage training paradigm. In the first stage, the detector is trained using rich base class samples to learn the common representations required for object detection tasks, such as object localization and classification. In the second stage, the detector is fine-tuned using only a small number (e.g. 1, 2, 3...) of novel class samples. However, due to the imbalance in the number of basic class and novel class samples, the learned model is usually biased towards the basic class, which leads to the confusion of novel class targets with similar basic classes. Furthermore, since there are only a few samples for each novel class, the model is sensitive to the variance of the novel classes. For example, if you randomly sample novel class samples for multiple trainings, the results will be quite different each time. Therefore, it is very necessary to improve the robustness of the model under small samples.
Recently, Tencent Youtu Lab and Wuhan University proposed a few-sample target detection model VFA based on variational feature aggregation. The overall structure of VFA is based on an improved version of the meta-learning target detection framework Meta R-CNN, and two feature aggregation methods are proposed: Category-independent feature aggregation CAA (Class-Agnostic Aggregation)AndVariational Feature Aggregation VFA (Variational Feature Aggregation).
Feature aggregation is a key design in FSOD, which defines the interaction between Query and Support samples. Previous methods such as Meta R-CNN usually use class-specific aggregation (CSA), that is, features of similar Query and Support samples for feature aggregation. In contrast, the CAA proposed in this paper allows feature aggregation between samples of different classes. Since CAA encourages the model to learn class-independent representations, it reduces the model's bias toward base classes. In addition, interactions between different classes can better model the relationships between classes, thereby reducing class confusion.
Based on CAA, this article proposes VFA, which uses variational encoders (VAEs) to encode Support samples into class distributions and samples new Support from the learned distribution. Features are used for feature fusion. Related work [1] states that intra-class variance (e.g., variation in appearance) is similar across classes and can be modeled by common distributions. Therefore, we can use the distribution of base classes to estimate the distribution of novel classes, thereby improving the robustness of feature aggregation in the case of few samples.
VFA outperforms the best current models on multiple FSOD data sets, Relevant research has Accepted as Oral by AAAI 2023.

## Paper address: https://arxiv.org/abs/2301.13411
VFA model detailsStronger baseline method: Meta R-CNN
Current FSOD work It can be mainly divided into two categories: methods based on meta learning and methods based on fine-tuning. Some early works demonstrated that meta-learning is effective for FSOD, but fine-tuning based methods have received increasing attention recently. This article first establishes a baseline method Meta R-CNN based on meta-learning, which narrows the gap between the two methods and even exceeds the method based on fine-tuning in some indicators .
We first analyzed some gaps in implementation between the two methods, taking the meta-learning method Meta R-CNN [2] and the fine-tuning-based method TFA [3] as examples. Although Both methods follow a two-stage training paradigm, with TFA optimizing the model using additional techniques during the fine-tuning stage:
- TFA freezes most of the network parameters and only trains the final classification and regression layers so that the model does not overfit the few-shot categories.
- Instead of randomly initializing the classification layer, TFA copies the pre-trained weights of the base classes and only initializes the weights of the novel classes.
- TFA uses a cosine classifier instead of a linear classifier.
Considering the success of TFA, we built Meta R-CNN. As shown in Table 1 below, meta-learning methods can also achieve good results as long as we handle the fine-tuning stage carefully. Therefore, this paper chooses Meta R-CNN as the baseline method.

##Table 1: Comparison and analysis of Meta R-CNN and TFA
Category-independent feature aggregation CAA

##Figure 1: Schematic diagram of category-independent feature aggregation CAA
This article proposes a simple and effective The category-independent feature aggregation method CAA. As shown in Figure 1 above, CAA allows feature aggregation between different classes, thereby encouraging the model to learn class-independent representations, thereby reducing inter-class bias and confusion between classes. Specifically, for each RoI feature of the category  and a set of Support features
and a set of Support features 
 , we randomly select a class The
, we randomly select a class The  of the Support feature
of the Support feature  is aggregated with the Query feature:
is aggregated with the Query feature:

 to the detection sub-network
to the detection sub-network
 To output the classification score
To output the classification score
.

Previous work usually encodes Support samples into a single feature vector to represent the center of the category. However, when the samples are small and the variance is large, it is difficult for us to make accurate estimates of the class center. In this paper, we first convert the Support features into distributions over classes. Since the estimated class distribution is not biased towards specific samples, features sampled from the distribution are relatively robust to the variance of the samples. The framework of VFA is shown in Figure 2 above. a) Variational feature learning. VFA employs variational autoencoders VAEs [4] to learn the distribution of categories. As shown in Figure 2, for a Support feature S, we first use the encoder 
 to estimate the distribution parameters
to estimate the distribution parameters  and
and  , then sample
, then sample  from the distribution
from the distribution  through variational inference, and finally obtain the reconstructed value through the decoder
through variational inference, and finally obtain the reconstructed value through the decoder  Support Features
Support Features . When optimizing VAE, in addition to the common KL Loss
. When optimizing VAE, in addition to the common KL Loss and reconstruction Loss
and reconstruction Loss , this article also uses consistency Loss to make the learned distribution retain category information:
, this article also uses consistency Loss to make the learned distribution retain category information:

b) Variational feature fusion. Since the Support feature is converted into a distribution of categories, we can sample features from the distribution and aggregate them with the Query feature. Specifically, VFA also uses category-independent aggregation CAA, but aggregates Query features  and variational features
and variational features  . Given the Query feature
. Given the Query feature  of class
of class  and the Support feature
and the Support feature  of class
of class 
, we first estimate its distribution  , and sample variational features
, and sample variational features  ; and then fuse them together by the following formula:
; and then fuse them together by the following formula:

Where  represents channel multiplication, and sig is the abbreviation of sigmoid operation. In the training phase, we randomly select a Support feature
represents channel multiplication, and sig is the abbreviation of sigmoid operation. In the training phase, we randomly select a Support feature  for aggregation; in the testing phase, we average the
for aggregation; in the testing phase, we average the 
Support features of the  class Value
class Value  , and estimate the distribution
, and estimate the distribution  , where
, where  .
.
Classification - Regression task decoupling
Typically, the detection subnetwork  contains a shared feature extractor
contains a shared feature extractor  and two independent networks: the classification subnetwork
and two independent networks: the classification subnetwork  and regression sub-network
and regression sub-network  . In previous work, the aggregated features were input into the detection sub-network for object classification and bounding box regression. But classification tasks require translation-invariant features, while regression requires translation-covariant features. Since the Support feature represents the center of the category and is translation invariant, the aggregated features will harm the regression task.
. In previous work, the aggregated features were input into the detection sub-network for object classification and bounding box regression. But classification tasks require translation-invariant features, while regression requires translation-covariant features. Since the Support feature represents the center of the category and is translation invariant, the aggregated features will harm the regression task.
This article proposes a simple classification-regression task decoupling. Let  and
and  represent the original and aggregated Query features. The previous method uses
represent the original and aggregated Query features. The previous method uses  for both tasks, where The classification score
for both tasks, where The classification score  and the predicted bounding box
and the predicted bounding box  are defined as:
are defined as:

##To decouple these tasks, we adopt a separate feature extractor and use the original Support features  for bounding box regression:
for bounding box regression:

Experimental evaluation
The data sets we used: PASCAL VOC, MS COCO. Evaluation indicators: Novel class average precision nAP, basic class average precision bAP.
Main results
VFA achieved good results on both datasets. For example, on the PASCAL VOC data set (Table 2 below), VFA is significantly higher than previous methods; the 1-shot results of VFA are even higher than the 10-shot results of some methods.

Ablation experiment
a) The role of different modules . As shown in Table 3 below, different modules of VFA can work together to improve the performance of the model.

b) Visual analysis of different feature aggregation methods. As shown in Figure 3 below, CAA can reduce confusion between basic classes and novel classes; VFA further enhances the distinction between classes based on CAA.

c) More accurate category center point estimation. As shown in Figure 4 below, VFA can more accurately estimate the center of the category. And as the number of samples decreases, the accuracy of estimation gradually becomes higher than the baseline method. This also explains why our method performs better when there are few samples (K=1).

d) Result visualization.

The above is the detailed content of Regression meta-learning, few-sample target detection based on variational feature aggregation to achieve new SOTA. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

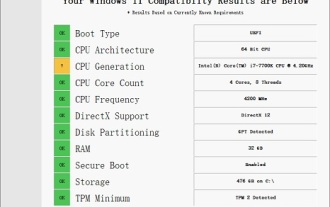 Solution to i7-7700 unable to upgrade to Windows 11
Dec 26, 2023 pm 06:52 PM
Solution to i7-7700 unable to upgrade to Windows 11
Dec 26, 2023 pm 06:52 PM
The performance of i77700 is completely sufficient to run win11, but users find that their i77700 cannot be upgraded to win11. This is mainly due to restrictions imposed by Microsoft, so they can install it as long as they skip this restriction. i77700 cannot be upgraded to win11: 1. Because Microsoft limits the CPU version. 2. Only the eighth generation and above versions of Intel can directly upgrade to win11. 3. As the 7th generation, i77700 cannot meet the upgrade needs of win11. 4. However, i77700 is completely capable of using win11 smoothly in terms of performance. 5. So you can use the win11 direct installation system of this site. 6. After the download is complete, right-click the file and "load" it. 7. Double-click to run the "One-click
 Fall detection, based on skeletal point human action recognition, part of the code is completed with Chatgpt
Apr 12, 2023 am 08:19 AM
Fall detection, based on skeletal point human action recognition, part of the code is completed with Chatgpt
Apr 12, 2023 am 08:19 AM
Hello everyone. Today I would like to share with you a fall detection project, to be precise, it is human movement recognition based on skeletal points. It is roughly divided into three steps: human body recognition, human skeleton point action classification project source code has been packaged, see the end of the article for how to obtain it. 0. chatgpt First, we need to obtain the monitored video stream. This code is relatively fixed. We can directly let chatgpt complete the code written by chatgpt. There is no problem and can be used directly. But when it comes to business tasks later, such as using mediapipe to identify human skeleton points, the code given by chatgpt is incorrect. I think chatgpt can be used as a toolbox that is independent of business logic. You can try to hand it over to c
 MIT's latest masterpiece: using GPT-3.5 to solve the problem of time series anomaly detection
Jun 08, 2024 pm 06:09 PM
MIT's latest masterpiece: using GPT-3.5 to solve the problem of time series anomaly detection
Jun 08, 2024 pm 06:09 PM
Today I would like to introduce to you an article published by MIT last week, using GPT-3.5-turbo to solve the problem of time series anomaly detection, and initially verifying the effectiveness of LLM in time series anomaly detection. There is no finetune in the whole process, and GPT-3.5-turbo is used directly for anomaly detection. The core of this article is how to convert time series into input that can be recognized by GPT-3.5-turbo, and how to design prompts or pipelines to let LLM solve the anomaly detection task. Let me introduce this work to you in detail. Image paper title: Largelanguagemodelscanbezero-shotanomalydete
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Written above & The author’s personal understanding is that in the autonomous driving system, the perception task is a crucial component of the entire autonomous driving system. The main goal of the perception task is to enable autonomous vehicles to understand and perceive surrounding environmental elements, such as vehicles driving on the road, pedestrians on the roadside, obstacles encountered during driving, traffic signs on the road, etc., thereby helping downstream modules Make correct and reasonable decisions and actions. A vehicle with self-driving capabilities is usually equipped with different types of information collection sensors, such as surround-view camera sensors, lidar sensors, millimeter-wave radar sensors, etc., to ensure that the self-driving vehicle can accurately perceive and understand surrounding environment elements. , enabling autonomous vehicles to make correct decisions during autonomous driving. Head
 How to detect and handle null value errors in PHP language development?
Jun 11, 2023 am 10:51 AM
How to detect and handle null value errors in PHP language development?
Jun 11, 2023 am 10:51 AM
With the continuous development of modern web applications, PHP, as one of the most popular programming languages, is widely used in website development. However, during the development process, null value errors are often encountered, and these errors can cause the application to throw exceptions, thus affecting the user experience. Therefore, in the PHP development process, how to detect and deal with null errors is an important skill that programmers need to master. 1. What is a null value error? In the PHP development process, null value errors usually refer to two situations: uninitialized variables and variable variables.
 AAAI2024: Far3D - Innovative idea of directly reaching 150m visual 3D target detection
Dec 15, 2023 pm 01:54 PM
AAAI2024: Far3D - Innovative idea of directly reaching 150m visual 3D target detection
Dec 15, 2023 pm 01:54 PM
Recently, I read a latest research on pure visual surround perception on Arxiv. This research is based on the PETR series of methods and focuses on solving the pure visual perception problem of long-distance target detection, extending the perception range to 150 meters. The methods and results of this paper have great reference value for us, so I tried to interpret it. Original title: Far3D: Expanding the Horizon for Surround-view3DObject Detection Paper link: https://arxiv.org/abs/2308.09616 Author affiliation :Beijing Institute of Technology & Megvii Technology Task Background 3D Object Detection in Understanding Autonomous Driving
 NeRF's breakthrough in BEV generalization performance: the first cross-domain open source code successfully implements Sim2Real
Jan 11, 2024 am 10:24 AM
NeRF's breakthrough in BEV generalization performance: the first cross-domain open source code successfully implements Sim2Real
Jan 11, 2024 am 10:24 AM
Written above & the author's personal summary Birdeye'sview (BEV) detection is a method of detection by fusing multiple surround-view cameras. Most of the current algorithms are trained and evaluated on the same data set, which causes these algorithms to overfit to the unchanged camera internal parameters (camera type) and external parameters (camera placement). This paper proposes a BEV detection framework based on implicit rendering, which can solve the problem of object detection in unknown domains. The framework uses implicit rendering to establish the relationship between the 3D position of the object and the perspective position of a single view, which can be used to correct perspective bias. This method achieves significant performance improvements in domain generalization (DG) and unsupervised domain adaptation (UDA). This method was first tried using only virtual numbers
