
 Technology peripherals
AI
A long article of 10,000 words, popular science on facial recognition algorithms and systems
Technology peripherals
AI
A long article of 10,000 words, popular science on facial recognition algorithms and systems
A long article of 10,000 words, popular science on facial recognition algorithms and systems


The goal of face recognition
To summarize two points, first, if you recognize the same person, you will know that you are who you are no matter how your status changes. Second, distinguish different people. Maybe the two people look very similar, or both of them wear makeup, but no matter how the status changes, facial recognition can know that these are two different people.
Face recognition itself is a type of biometric technology, mainly providing a means of identity authentication. In terms of accuracy, face recognition is not the highest. Face recognition is affected by many other conditions, such as lighting. The advantage of face recognition is that it generally does not require much cooperation from the user. Nowadays, surveillance cameras in various places, including computer cameras, mobile phone video input devices, and photographic equipment have become very popular. This kind of visible light equipment can Can do face recognition. Therefore, when facial recognition is introduced, the new investment may be very small, which is its advantage.
Face recognition process
The core process of face recognition. The so-called core process means that no matter what kind of face recognition system, this process is basically there. First, face detection, second step, face alignment, and third step, feature extraction. These are the three steps that must be done for every photo. When comparing, compare the extracted features. , and then determine whether the two faces belong to the same person.
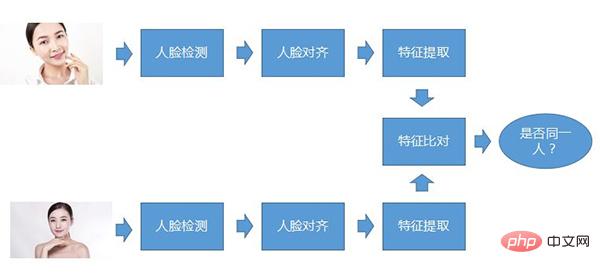
Face detection
Face detection is to determine whether there is a face in a large scene, and to find the position of the face and cut it out . It is a type of object detection technology and is the basis of the entire face perception task. The basic method of face detection is to slide the window on the image pyramid, use a classifier to select candidate windows, and use a regression model to correct the position.
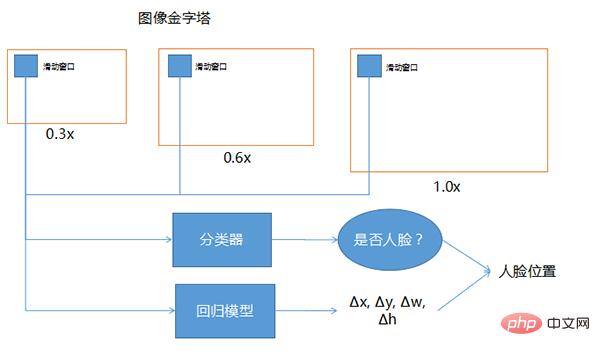
The three windows drawn above, one is 0.3 times, 0.6 times, and 1.0 times. This technology can be used when the position of the face is uncertain and the size cannot be recognized, so that this The graph itself becomes different sizes, while the sliding window is the same size. The size of the image input to the deep network is generally fixed, so the sliding window in front is basically fixed. In order to allow the fixed sliding window to cover different ranges, the size of the entire image is scaled to different proportions. The 0.3, 0.6, and 1.0 shown here are just examples. There can be many other different multiples in actual use.
The classifier refers to looking at each position of the sliding window to determine whether it is a face, because the position where the sliding window slides may not include the entire face, or it may be larger than the entire face. . In order to find more accurate faces, putting the sliding window into the regression model can help correct the accuracy of face detection.
The input is a sliding window. If there is a face in it during output, which direction should be corrected and how much it needs to be corrected, so Δx, Δy, Δw, Δh are its coordinates and its width and height. Approximately how much correction. After having the amount of correction and using the classifier to determine that it is a window of a human face, by combining these two together, a more accurate position of the human face can be obtained.
The above is the process of face detection, and it can also be applied to other object detection
Evaluation indicators of face detection
No matter what kind of model, it is based on speed and accuracy
1. Speed
(1) Speed is the detection speed under the specified resolution
The resolution is specified because the sliding window slides every time A classification and regression judgment must be made to reach each position, so when the image is larger, the number of windows that need to be made for detection and judgment may be more, and the entire face detection will take longer.
Therefore, to evaluate the quality of an algorithm or model, you have to look at its detection speed at a fixed resolution. Generally speaking, what the detection speed will be? It may be the time it takes to detect the face of a picture, such as 100 milliseconds, 200 milliseconds, 50 milliseconds, 30 milliseconds, etc.
Another way to express speed is fps. Nowadays, general web cameras are often 25fps or 30fps, which means how many pictures can be processed per second. The benefit of fps can be used to judge whether face detection is possible. To achieve real-time detection, as long as the fps number of face detection is greater than the fps number of the camera, real-time detection can be achieved, otherwise it will not be possible.
(2) Whether the speed is affected by the number of faces in the same picture
From our actual operation, most of them are not affected, because it is mainly affected by sliding The number of windows affects the number of hits. The number of hits is not particularly heavy, but it has a slight impact.
2. Precision
Precision is basically determined by recall rate, false detection rate, and ROC curve. The recall rate refers to the proportion of the photo that is a human face, and the real model determines that it is a human face. The false detection rate and the negative sample error rate refer to the proportion of the photo that is not a human face, but is misjudged to be a human face.
ACC accuracy
The ACC calculation method is to divide the correct number of samples by the total number of samples. For example, if you take 10,000 photos for face detection, these 10,000 Some of the photos have faces, and some have no faces. Then determine what the correct ratio is.
But there is a problem with this accuracy. If you use it to judge, it has nothing to do with the ratio of positive and negative samples. That is, it does not care about the correct rate in positive samples and the correct rate in negative samples. What it is, I only care about the total. When the accuracy of this model is 90%, others do not know the difference between positive and negative samples. Including classification, including regression, generally speaking, the classification model will first use a regression to obtain a so-called confidence level. When the confidence level is greater than a certain value, it is considered to be it, and then when the confidence level is less than the same value, it is considered to be not.
The ACC statistical model is adjustable, that is, adjusting the confidence level will change the accuracy.
So the ACC value itself is greatly affected by the proportion of the sample, so it is a bit problematic to use it to characterize the quality of a model. When the test indicator says it has reached 99.9%, just look at this value, it is easier to be deceived or this statistic is biased. In order to solve this problem, a curve called ROC is generally used to characterize the accuracy of this model
ROC Receiver Operating Characteristic Curve
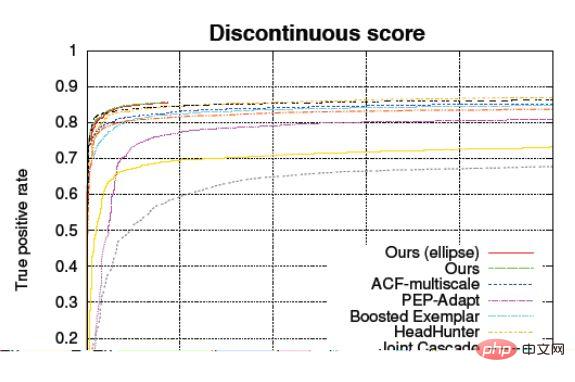
The abscissa: FPR (False Positive Rate), which is the error rate of negative samples
The ordinate: TPR (True Positive Rate), which is the correct rate of positive samples
can distinguish the algorithm in positive samples and performance on negative samples, and the shape of the curve has nothing to do with the ratio of positive and negative samples.
ROC (Receiver Operating Characteristic) curve is to mark the abscissa and ordinate with the negative sample error rate and the positive sample correct rate. In this case, the same model will not be seen as a point on this graph. , or rather than a single data, but a line. This line is the confidence threshold. The higher you adjust it, the more stringent it is, and the lower it is, the less stringent it is. Above this, it can reflect the impact of changes in the confidence threshold.
In the future, it is best not to ask directly what your accuracy is, but to look at the ROC curve, which makes it easier to judge the capabilities of the model.
Face Alignment
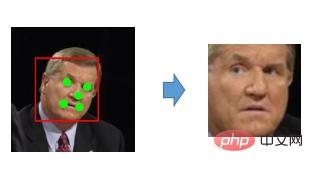
The purpose of face alignment is to adjust the face texture to the standard position as much as possible and reduce the difficulty of the face recognizer.
In order to artificially reduce its difficulty, you can first align it, that is, let the detected eyes, nose, and mouth of the person all fall into the same position. In this way, the model will be compared When you search, you only need to look for objects near the same location. Whether they are the same or similar to each other is still very different. So we are able to do this step of alignment. For this step, the common method we use now is the two-dimensional method, which is to find the key feature points in this picture. Generally, they are five points, nineteen points, and more than sixty points. There are all kinds of spots, including more than 80 spots. But for face recognition, five is basically enough.
The image of other points other than these five points can be considered as performing an operation similar to interpolation, and then pasting it to that position. After it is completed, it can be sent to the later The face recognition is done in the face recognition machine. This is a general approach, but there are also more cutting-edge approaches. Some research institutions are using the so-called 3D face alignment, which means I tell you what a frontal face looks like, such as what it looks like when rotated 45 degrees. Then after training him with this kind of picture, he will know that when I see a picture rotated 45 degrees to the left and right, there is a high probability of what it will look like when it is turned right, and this model can guess it.
Facial Feature Extraction Algorithm
The previous traditional methods were the so-called local texture model, global texture model, shape regression model and the like. What is more popular now is the use of deep convolutional neural networks or recurrent neural networks, or convolutional neural networks with 3DMM parameters. The so-called 3DMM parameters have three-dimensional information in them, and then there are cascaded deep neural networks.
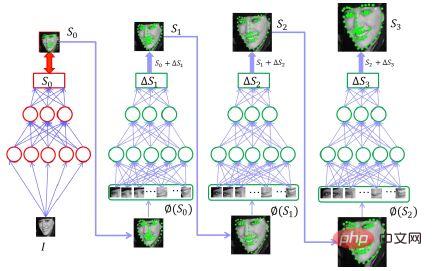
Cascaded deep neural network, that is, to get the face, you must first guess the positions of five points. If you use a single model, you must do this at once If so, the model would need to be very complex.
But how can we reduce the complexity of this model?
That is, multiple inputs are made. After the first input into this network, a guess is made. This guess is an acceptable and less accurate guess. It roughly knows where the five points of the face are. Then put these five points and the original image into the second network to get the approximate correction amount. After you have a basic five points and then find the correction amount, it will be better than finding the accurate five points directly from the original image. This point is slightly easier. Therefore, using this method of gradual refinement and cascading multiple networks together can achieve a better balance between speed and accuracy. In fact, when we do it now, we basically use two layers and it is about the same.
Evaluation index for facial feature point extraction
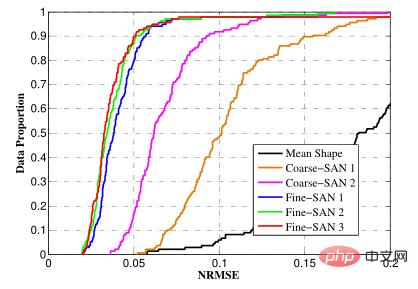
NRMSE (Normalized Root Mean Square Error) is the normalized root mean square error
Used to measure the difference between the coordinates of each feature point and the labeled coordinates.
Accuracy
In order to allow faces of different sizes to be put together and compared with each other, what is statistically called the normalized root mean square error is used. For example: we draw five points on paper, and then let the machine tell the distance between these five points. The closer the value given is to the real distance, the more accurate the prediction is. Generally speaking, the predicted value will have some deviation, so how to express this accuracy value? We usually express it by the average or root mean square value of distance. However, the problem arises. When the same machine predicts images of different sizes, the accuracy values will appear different, because the larger the image, the higher the absolute value of the error will be. The same principle applies to faces of different sizes. Therefore, our solution is to take into account the original size of the human face. Generally, the denominator is the distance between the human eyes or the diagonal distance of the human face, and then divide the distance difference by the distance between the eyes, or divide by The diagonal of the face, in this case, you can get a value that basically does not change with the size of the face, and use it for evaluation.
Face comparison
(1) Purpose: To determine whether two aligned faces belong to the same person
(2) Difficulty: The same person The face will appear in different states under different conditions, such as being particularly affected by light, smoke, makeup, etc. The second one is caused by different parameters mapped to two-dimensional photos. The so-called mapping to two-dimensional parameters means that the original face looks like this. When the shooting equipment takes the picture, the angle it presents to him, the distance from him, and the focus Whether it is accurate, the shooting angle, and the light accumulation all have an impact, which will cause the same face to appear in different states. The third is the influence of age and plastic surgery.
Facial comparison method
(1) Traditional method
1. Manually extract some features such as HOG, SIFT, wavelet transform, etc. Generally speaking, the extracted features may require fixed parameters, that is, no training or learning is required. A set of fixed algorithms is used to compare the features.
(2) Depth method
The mainstream method is the depth method, that is, the deep convolutional neural network. This network generally uses DCNN to replace the previous one. Those feature extraction methods are to extract some different features on a picture or a face. There are many parameters in DCNN. These parameters are learned, not told by people. If they are learned, it is equivalent to being able to It will be better than what people have summarized.
Then the obtained set of features may generally have 128 dimensions, 256 dimensions, or 512 dimensions or 1024 dimensions, and then compare them. To judge the distance between feature vectors, Euclidean distance or cosine similarity is generally used Spend.
The evaluation indicators of face comparison are also divided into speed and accuracy. Speed includes the calculation time of a single face feature vector and the comparison speed. Accuracy includes ACC and ROC. Since it has been introduced before, here we focus on the comparison speed.
Ordinary comparison is a simple operation, which is to calculate the distance between two points. You may only need to do an inner product once, which is the inner product of two vectors, but when face recognition encounters 1:N When comparing, when the N database is very large, when you get a photo and search it in the N database, the number of searches will be very large. For example, if the N database is one million, you may need to search it one million times. One million times is equivalent to one million comparisons. At this time, there are still requirements for the total time, so there will be various technologies to accelerate this comparison.
Other algorithms related to face recognition
Mainly include face tracking, quality assessment, and living body recognition.
● Face Tracking
In surveillance and other video face recognition scenarios, if the entire face recognition process is executed for every frame of the same person walking by, it will not only waste computing resources , and it is possible that some low-quality frames may cause misrecognition, so it is necessary to determine which faces belong to the same person. And select appropriate photos for recognition, which greatly improves the overall performance of the model.
Nowadays, not only face tracking, but also various object tracking or vehicle tracking, etc., will use tracking algorithms. Such algorithms do not rely on or will not always rely on detection. For example, after detecting an object at the beginning, it will not detect it at all and only use the tracking algorithm to do it. At the same time, in order to achieve very high accuracy and avoid loss, each tracking takes a lot of time.
In order to prevent the tracked face from not matching the range of the face recognizer, generally speaking, a face detector will be used for a detection. This detection method relies on face detection and is relatively light. Quantitative tracking can achieve a balance between speed and quality in certain scenarios.
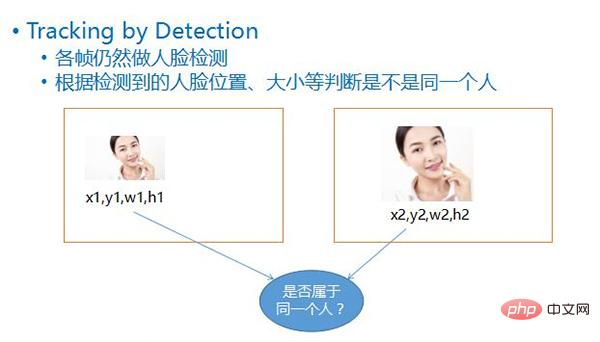
This detection method is called Tracking by Detection, that is, face detection is still performed in each frame. After the face is detected, based on the four values of each face, That is, its coordinate position, its width and height, and by comparing the position and size of the face in the two frames before and after, it can be roughly inferred whether the two faces belong to the same moving object.
● Optional interval full-screen detection
refers to when doing Tracking by Detection, one way is to do full-screen detection on the two frames before and after, the so-called full-screen detection That is to scan the entire screen, but this method is very time-consuming, so another method is sometimes used, which is to scan the entire screen every few frames. Generally, the next frame is predicted, and the position will not change too much. As long as the previous frame is If the position of the frame is slightly expanded up, down, left, and right, and detected again, there is often a high probability that it can be detected, and most frames can be skipped.
Why do we have to do a full-screen detection every few frames?
is to prevent new objects from coming in. If you only search based on the position of the previous object, there may be new objects that are not detected when they come in. To prevent this situation, you can wait five frames. , do another full-screen detection after ten frames.
● Face quality assessment
Due to the limitations of face recognizer training data, etc., it is impossible to perform well on faces in all states. The quality assessment will judge the detected person. According to the degree of agreement between the characteristics of the face and the recognizer, only the faces with a high degree of agreement are selected and sent for recognition to improve the overall performance of the system.
Face quality evaluation includes the following 4 elements
① The size of the face. If a face that is too small is selected for recognition, the recognition effect will be greatly reduced.
② Face posture refers to the rotation angle in three axes. Generally speaking, it is related to the data used for recognizer training. If most faces with small postures are used during training, it is best not to choose faces with large deflections when actually doing recognition, otherwise it will not be applicable.
③ Degree of blur, this factor is very important. If the photo has lost information, there will be problems in recognition.
④ Occlusion, if the eyes, nose, etc. are covered, the features of this area cannot be obtained, or the obtained ones are wrong. They are features of an occluder, which will have an impact on subsequent recognition. . If it can be determined that it is occluded, then discard it, or do some special processing, such as not putting it into the recognition model.
● Living body recognition
This is a problem that all face recognition systems will encounter. If only faces are recognized, photos can also be fooled. In order to prevent the system from being attacked, some judgments will be made to determine whether this is a real face or a fake face.
Basically, there are currently three methods:
① Traditional dynamic recognition. Many banks’ cash withdrawal machines require the user to do some cooperation, such as asking the user to blink, turn their head, etc. This is used to determine whether the user has made the same coordination by blinking and turning his head. Therefore, there is a problem with dynamic recognition, that is, it requires a lot of cooperation from the user, so the user experience will be a bit bad.
② Static recognition means not judging based on actions, but just judging whether it is a real face or a fake face based on the photo itself. It is based on the commonly used attack methods, which are relatively convenient. For example, take a mobile phone or a display screen and use the screen to attack.
The luminous ability of this kind of screen is different from the luminous ability of human faces under actual lighting conditions. For example, a monitor with 16 million luminous colors cannot achieve the luminous ability of visible light, that is, all of them are continuous. All bands can be emitted. Therefore, when shooting this kind of screen, compared with the primary imaging in the real natural environment, the human eye can also see that there will be some changes and some unnaturalness. After putting this unnaturalness into a model for training, you can still judge whether it is a real face based on this subtle difference.
③ Stereo recognition, if you use two cameras or a camera with depth information, you can know the distance of each captured point from the camera, which is equivalent to 3D imaging of people, using one screen When I go to shoot, the screen must be a flat surface, and I realize that it is a flat surface, and the flat surface is definitely not a real person. This is to use a three-dimensional recognition method to exclude flat faces.
System composition of face recognition
First make a classification. From the perspective of comparison, there are 1:1 recognition system and 1:N recognition system; from the perspective of comparison objects, there are photos comparison system and video comparison system; according to the deployment form, there are private deployment, cloud deployment or mobile device deployment.
Photo 1:1 recognition system
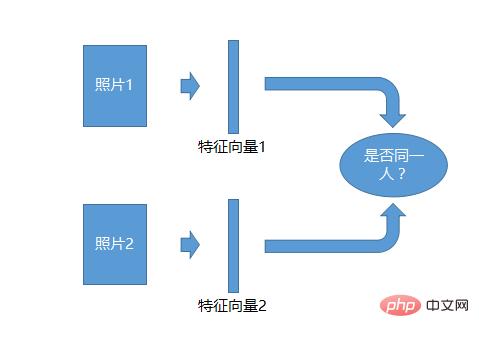
The 1:1 recognition system is the simplest. Take two photos and generate a feature for each photo. Vector, and then compare the two feature vectors to see if they are the same person, and you can identify them.
Photo 1: N’s identification system
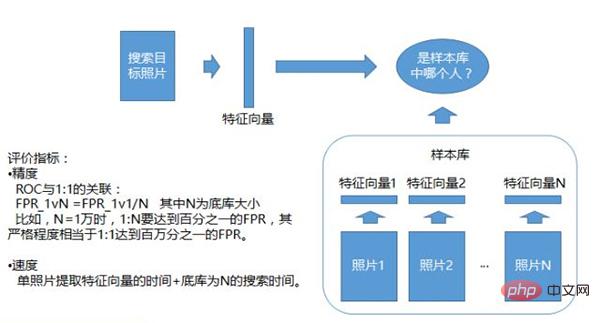
1: N’s identification system, which determines whether the photo material is in a sample library. This sample library is prepared in advance and may have a whitelist or a blacklist. It contains a photo of each person, and a series of feature vectors are generated from this photo. This is used as a sample library. The uploaded photos are compared with all the features in the sample library to see which one is most similar to the person. This is a 1:N recognition system.
Video 1:1 recognition system
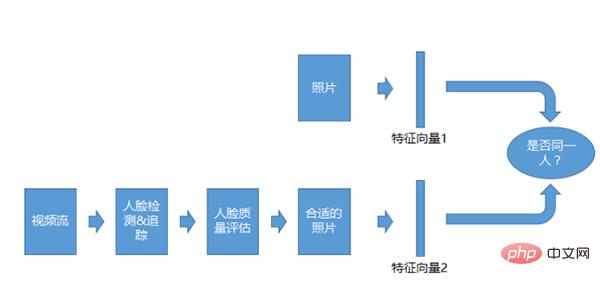
Video 1:1 recognition system is similar to the 1:1 system of photos, but the comparison object is not Photos, but video streams. After getting the video stream, we will do detection, tracking, and quality assessment, and then we will compare it after we get the appropriate photos.
Video 1: N recognition system
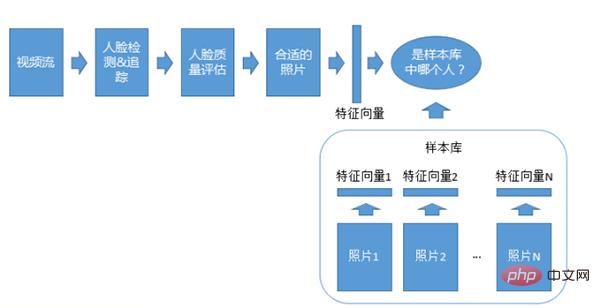
Video 1: N adaptation system is similar to the 1:N photo system, except that it is used for recognition What’s important is video streaming, which also requires detection, tracking, and quality assessment.
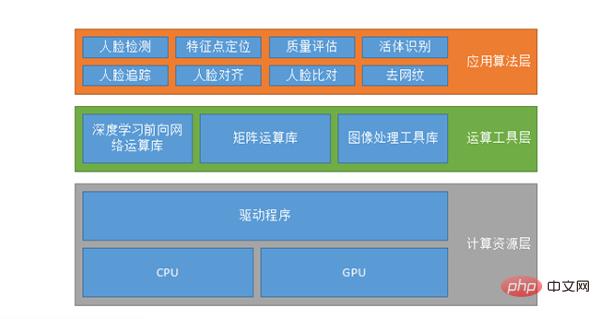
# Generally speaking, the so-called system configuration is not necessarily a face recognition system, and this is probably the case for various AI systems. The first is the computing resource layer, which runs on the CPU or GPU. Running on the GPU may also have support for CUDA, CUDN, etc.
The second is the computing tool layer, including the deep learning forward network computing library, matrix computing library and image processing tool library. Since it is impossible for everyone who makes algorithms to write their own data operations, they will use some existing data operation libraries, such as TensorFlow or MXNET or Caffe, etc., or they can write their own set.
The above is the detailed content of A long article of 10,000 words, popular science on facial recognition algorithms and systems. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
 Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
The convergence of artificial intelligence (AI) and law enforcement opens up new possibilities for crime prevention and detection. The predictive capabilities of artificial intelligence are widely used in systems such as CrimeGPT (Crime Prediction Technology) to predict criminal activities. This article explores the potential of artificial intelligence in crime prediction, its current applications, the challenges it faces, and the possible ethical implications of the technology. Artificial Intelligence and Crime Prediction: The Basics CrimeGPT uses machine learning algorithms to analyze large data sets, identifying patterns that can predict where and when crimes are likely to occur. These data sets include historical crime statistics, demographic information, economic indicators, weather patterns, and more. By identifying trends that human analysts might miss, artificial intelligence can empower law enforcement agencies
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 How to turn off face recognition on Apple phone_How to disable face recognition on Apple phone settings
Mar 23, 2024 pm 08:20 PM
How to turn off face recognition on Apple phone_How to disable face recognition on Apple phone settings
Mar 23, 2024 pm 08:20 PM
1. We can ask Siri before going to bed: Whose phone is this? Siri will automatically help us disable face recognition. 2. If you don’t want to disable it, you can turn on Face ID and choose to turn on [Require gaze to enable Face ID]. In this way, the lock screen can only be opened when we are watching.
 How to enter DingTalk face recognition
Mar 05, 2024 am 08:46 AM
How to enter DingTalk face recognition
Mar 05, 2024 am 08:46 AM
As an intelligent service software, DingTalk not only plays an important role in learning and work, but is also committed to improving user efficiency and solving problems through its powerful functions. With the continuous advancement of technology, facial recognition technology has gradually penetrated into our daily life and work. So how to use the DingTalk app for facial recognition entry? Below, the editor will bring you a detailed introduction. Users who want to know more about it can follow the pictures and text of this article! How to record faces on DingTalk? After opening the DingTalk software on your mobile phone, click "Workbench" at the bottom, then find "Attendance and Clock" and click to open. 2. Then click "Settings" on the lower right side of the attendance page to enter, and then click "My Settings" on the settings page to switch.
 Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
1. Background of the Construction of 58 Portraits Platform First of all, I would like to share with you the background of the construction of the 58 Portrait Platform. 1. The traditional thinking of the traditional profiling platform is no longer enough. Building a user profiling platform relies on data warehouse modeling capabilities to integrate data from multiple business lines to build accurate user portraits; it also requires data mining to understand user behavior, interests and needs, and provide algorithms. side capabilities; finally, it also needs to have data platform capabilities to efficiently store, query and share user profile data and provide profile services. The main difference between a self-built business profiling platform and a middle-office profiling platform is that the self-built profiling platform serves a single business line and can be customized on demand; the mid-office platform serves multiple business lines, has complex modeling, and provides more general capabilities. 2.58 User portraits of the background of Zhongtai portrait construction
