
 Technology peripherals
AI
Understand the Hash algorithm and application scenarios in one article
Technology peripherals
AI
Understand the Hash algorithm and application scenarios in one article
Understand the Hash algorithm and application scenarios in one article

1. What is a hash algorithm
Both hash and hash come from the word hash, the former is a transliteration and the latter is a free translation. It is an algorithm that can map a binary value of any length into a fixed-length binary value. The mapped fixed-length binary value is called a hash value. An excellent hash algorithm needs to meet the following requirements:
cannot reversely deduce the original data from the hash value;
is very sensitive to the input data, and a different bit will cause hashing. The hash values are very different;
The probability of hash conflict must be very small;
The calculation process of the hash algorithm must be simple and efficient enough, so that even if the original data is very long, the hash value can be obtained quickly Hash value;
2. Usage scenarios of hash algorithms
2.1 Secure encryption
The more common hash encryption algorithms are MD5 (MD5 Message-Digest Algorithm, MD5 message Digest algorithm) and SHA (Secure Hash Algorithm, secure hash algorithm).
The plaintext password cannot be deduced from the hash value ciphertext, and the probability of hash conflict is relatively small. These two points ensure the reliability of the hash algorithm as a secure encryption method.
Why hash algorithms cannot completely avoid hash conflicts, but can only minimize them?
The pigeon nest principle tells us that if 11 pigeons fly into 10 pigeon cages, then there must be 2 or more pigeons in one pigeon cage. Then the hash value is of fixed length, which determines that the hash value can be exhausted, but in theory the original data is infinite, so it is possible to cause a hash conflict.
This application scenario uses the characteristics 1 and 3 of the hash algorithm. Among them, 3 ensures that the password is very difficult to be cracked in the forward direction (taking MD5 as an example, the hash value length is 128 bits, and there are 2 ^128 different hashes, very difficult to crack).
There is no absolute security in the security field. Although MD5 is difficult to crack, there are still ways to crack it. For example, using rainbow table matching can easily crack common passwords.
So generally we will use a salted hash algorithm for secure encryption. The salting method needs to be kept strictly confidential, which greatly increases the difficulty and cost of cracking.
2.2 Unique flag
When we verify whether two files are the same, we cannot simply judge by the file name. Because the existence of files with the same name is too common.
We can take some binary data from a large file according to specific rules, and use the hash algorithm to obtain the hash value as the unique identifier of the file. In this way, the same files must have the same hash value, that is, the same unique identifier; different files have a high probability of having different hash value unique identifiers;
Even if you really encounter a scattered If there is a column conflict, we can compare all the binary data of the two files in detail to further determine whether they are the same file. The probability of this event happening is too small. However, this solution ensures both efficiency and reliability.
This application scenario uses features 2 and 3 of the hash algorithm.
2.3 Data Verification
In the P2P download protocol, we will download different parts of the same movie from different machines, and then assemble the movie on our own machine. If there is an error in the downloading process of some part of the movie or the content is tampered with, it may cause downloading errors or viruses.
Therefore, we first perform hash calculation on all parts and save them in the seed file. After all parts are downloaded, we hash all parts to obtain the hash value, and then compare it with the one in the seed file to verify whether the file is complete.
This application scenario uses features 2 and 4 of the hash algorithm.
2.4 Hash function
This scenario has been introduced before when talking about hash tables. In this scenario, the requirements for Feature 1 are not very high. The requirement for Feature 2 is that the hash values should be distributed as evenly as possible. Feature 3 can also accept conflicts to a certain extent, which can be solved by using the open addressing method and the zipper method. Feature 4 is more demanding and needs to pursue performance.
2.5 Load Balancing
There are many load balancing algorithms, such as polling, random, weighted polling, etc., but the goal is to implement a session sticky load balancing algorithm, that is, the same All client requests during a session are routed to the same server.
We can hash the client's IP or session ID, and perform a modulo operation on the hash value and the number of servers. The final value is the server that needs routing, so that session stickiness can be achieved. purpose of stagnation.
2.6 Data Sharding
When we need to process massive data, a single server cannot load and calculate such massive data, then we need to evenly distribute the massive data to N servers The server performs parallel computing. How to distribute the data evenly to N servers?
We perform a hash calculation on the data, and use the obtained hash value modulo the number of servers N. Data with the same result will be assigned to the same server and handed over to this server for processing. N servers process massive data in parallel and finally merge the results.
2.7 Distributed Storage
Store massive data in a distributed cache or distributed database. The idea of borrowing is similar to the above data sharding. However, what should be done when the number of originally set servers is not enough?
It cannot be solved by simply adding a few machines. This will destroy the modulo operation of the hash value, lead to cache penetration, and cause an avalanche effect. Likewise, the same problem can result when a machine fault is removed. At this time, we need to use consistent hashing algorithm to solve this problem.
The consistent hash algorithm is simply to construct a hash ring with 2^32 nodes on the ring, and hash the server IP and files to the corresponding nodes. The first server that all files encounter clockwise is the server where they are stored. In this way, when a server is added or deleted, the number of files affected can be controlled and will not cause a global avalanche.
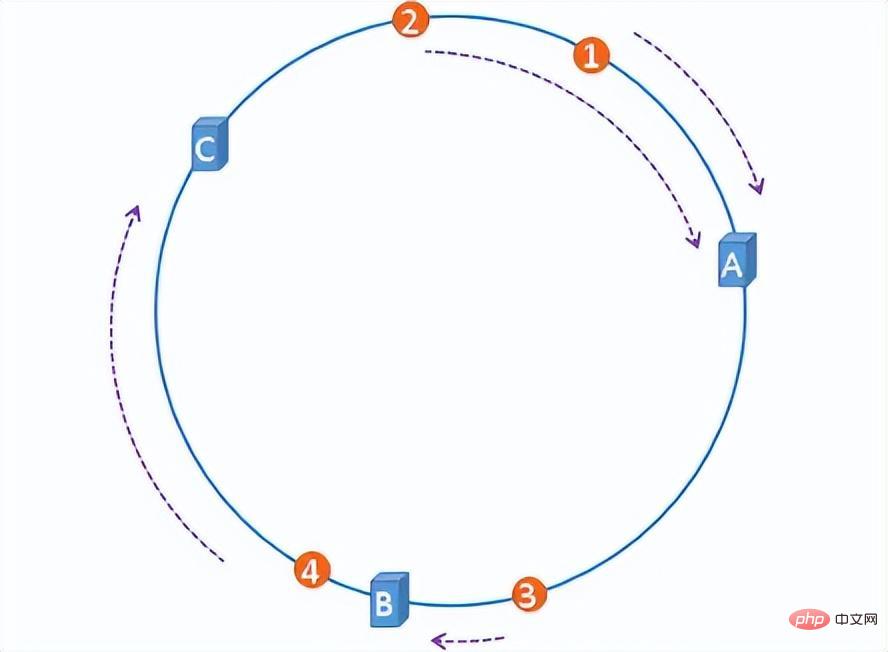
hash ring
However, with a certain probability, when the server IP is mapped to the hash ring, the problem of hash ring skew will occur. This will lead to extremely uneven distribution of files on the server, degenerating into a scenario that easily causes an avalanche effect when adding or deleting servers at the beginning.
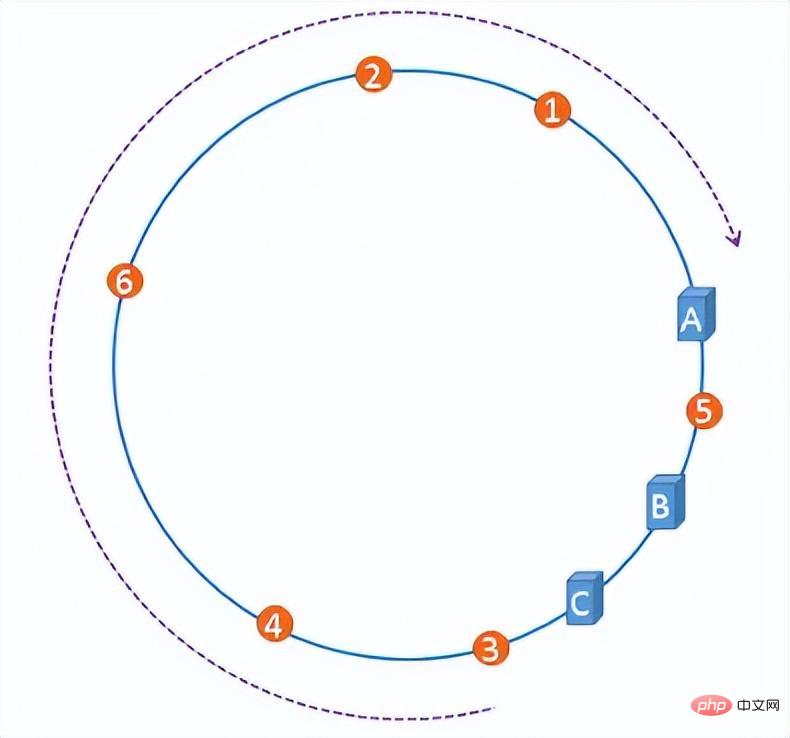
The skewness of the hash ring
We can artificially add a number of virtual nodes to these servers so that all server nodes are evenly distributed on the hash ring.
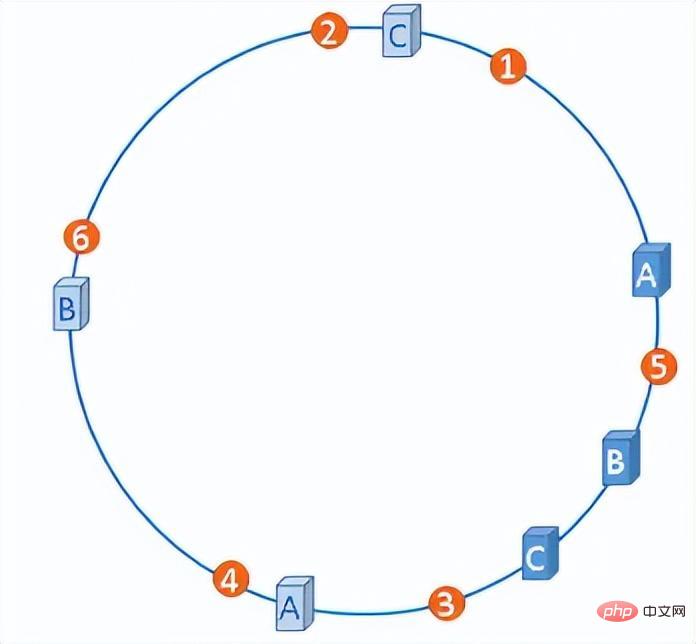
Hash ring with virtual nodes
3. Summary
The usage scenarios of Hash algorithm are far more than the above, there are also such as CRC check.
The above is the detailed content of Understand the Hash algorithm and application scenarios in one article. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Golang function hash, crc32, md5 and sha1 calculation methods
May 18, 2023 am 08:12 AM
Golang function hash, crc32, md5 and sha1 calculation methods
May 18, 2023 am 08:12 AM
Golang is a new high-performance programming language with a rich standard library and built-in functions. These include hash functions, which can be used to generate hash values of data for file verification, data verification, etc. This article will introduce the calculation methods and applications of the commonly used functions hash, crc32, md5 and sha1 in Golang. 1. Hash function Golang’s hash function includes a variety of hash algorithms, such as SHA-1, MD5, SHA-224, SHA-256, SH
 How to implement Redis Hash operation in php
May 30, 2023 am 08:58 AM
How to implement Redis Hash operation in php
May 30, 2023 am 08:58 AM
Hash operation //Assign values to fields in the hash table. Returns 1 on success and 0 on failure. If the hash table does not exist, the table will be created first and then the value will be assigned. If the field already exists, the old value will be overwritten. $ret=$redis->hSet('user','realname','jetwu');//Get the value of the specified field in the hash table. If the hash table does not exist, return false. $ret=$redis->hGet('user','rea
 Golang file reading operations: tips for reading large files quickly
Jan 19, 2024 am 08:33 AM
Golang file reading operations: tips for reading large files quickly
Jan 19, 2024 am 08:33 AM
Golang file reading operation: Tips for quickly reading large files, specific code examples are required In Golang programming, file reading is a very common operation. But when large files need to be read, it is usually a time- and resource-consuming operation. Therefore, how to read large files quickly is a topic worth discussing. This article will introduce how to use Golang's features and some techniques to quickly read large files, and provide specific code examples. Using bufio to read files in Golang, file reading
 What are the commonly used hash algorithm tools in Java function libraries?
Apr 30, 2024 pm 03:21 PM
What are the commonly used hash algorithm tools in Java function libraries?
Apr 30, 2024 pm 03:21 PM
In the Java function library, the MessageDigest class can be used for hash algorithms and provides implementations of MD5, SHA and other hash algorithms, including: 1. MD5 algorithm: Use MessageDigest.getInstance("MD5") to obtain an instance. 2.SHA algorithm: including SHA-1, SHA-256, SHA-384 and SHA-512, use MessageDigest.getInstance("SHA-256") to obtain the instance. 3. Other hashing algorithms: You can use third-party libraries, such as Algorithms.MessageDigest or BouncyCastle library.
 Laravel development: How to generate password hash using Laravel Hash?
Jun 17, 2023 am 10:59 AM
Laravel development: How to generate password hash using Laravel Hash?
Jun 17, 2023 am 10:59 AM
Laravel is currently one of the most popular PHP web frameworks, providing developers with many powerful features and components, among which LaravelHash is one of them. LaravelHash is a PHP library for password hashing that can be used to keep passwords secure and make your application's user data more secure. In this article, we will learn how LaravelHash works and how to use it to hash and verify passwords. Prerequisite knowledge in learning Lara
 How to implement MD5 hash algorithm using java
Sep 21, 2023 am 08:31 AM
How to implement MD5 hash algorithm using java
Sep 21, 2023 am 08:31 AM
How to use Java to implement the MD5 hash algorithm MD5 (MessageDigestAlgorithm5) is a commonly used hash algorithm used to encrypt and verify data. In Java, we can use the MessageDigest class to implement the MD5 hash algorithm. The following is a simple sample code that demonstrates how to implement the MD5 algorithm using Java. importjava.security.MessageDigest;
 Implement your own sha-256 hashing algorithm in PHP!
May 23, 2022 am 11:39 AM
Implement your own sha-256 hashing algorithm in PHP!
May 23, 2022 am 11:39 AM
Hash is also called "hash". It receives any set of input information of any length and transforms it into a fixed-length data fingerprint through the hash algorithm. The fingerprint is the hash value. Overall, a hash can be thought of as a message digest.
 Python's underlying technology revealed: how to implement a hash table
Nov 08, 2023 am 11:53 AM
Python's underlying technology revealed: how to implement a hash table
Nov 08, 2023 am 11:53 AM
Python’s underlying technology revealed: How to implement a hash table A hash table is a very common and important data structure in the computer field. It can efficiently store and search a large number of key-value pairs. In Python, we can use hash tables using dictionaries, but few people understand its implementation details in depth. This article will reveal the underlying implementation technology of hash tables in Python and give specific code examples. The core idea of a hash table is to map keys into a fixed-size array through a hash function, rather than simply storing them sequentially.
