
 Technology peripherals
AI
Using software visualization and transfer learning in software defect prediction
Technology peripherals
AI
Using software visualization and transfer learning in software defect prediction
Using software visualization and transfer learning in software defect prediction

The motivation of the article is to avoid the intermediate representation of the source code, represent the source code as an image, and directly extract the semantic information of the code to improve the performance of defect prediction.
First, see the motivation example as shown below. Although both examples of File1.java and File2.java contain 1 if statement, 2 for statements and 4 function calls, the semantics and structural characteristics of the code are different. In order to verify whether converting source code into images can help distinguish different codes, the author conducted an experiment: map the source code to pixels according to the ASCII decimal number of the characters, arrange them into a pixel matrix, and obtain an image of the source code. The author points out that there are differences between different source code images.

Fig. 1 Motivation Example
The main contributions of the article are as follows:
Convert the code into an image and extract semantic and structural information from it ;
Propose an end-to-end framework that combines self-attention mechanism and transfer learning to achieve defect prediction.
The model framework proposed in the article is shown in Figure 2, which is divided into two stages: source code visualization and deep transfer learning modeling.
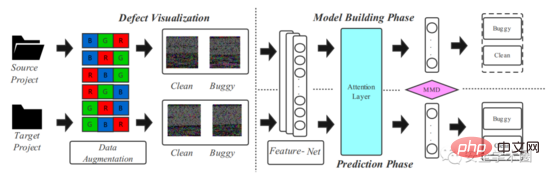
Fig. 2 Framework
1. Source code visualization
The article converts the source code into 6 images, the process is shown in Figure 3 shown. Convert the decimal ASCII codes of the source code characters into 8-bit unsigned integer vectors, arrange these vectors by rows and columns, and generate an image matrix. 8-bit integers directly correspond to gray levels. In order to solve the problem of the small original data set, the author proposed a data set expansion method based on color enhancement in the article: the values of the three color channels of R, G, and B are arranged and combined to generate 6 color images. It looks very confusing here. After changing the channel value, the semantic and structural information should change, right? But the author explains it in a footnote, as shown in Figure 4.
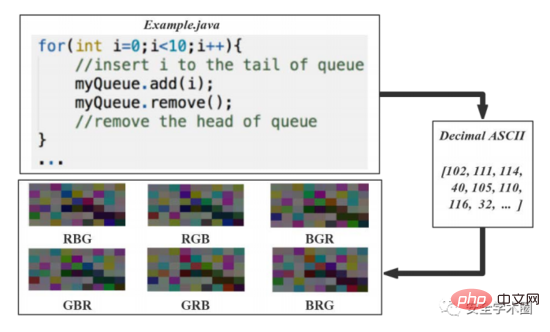
Fig. 3 Source code visualization process

Fig. 4 Article footnote 2
2 .Deep transfer learning modeling
The article uses DAN network to capture the semantic and structural information of the source code. In order to enhance the model's ability to express important information, the author added an Attention layer to the original DAN structure. The training and testing process is shown in Figure 5, in which conv1-conv5 come from AlexNet, and four fully connected layers fc6-fc9 are used as classifiers. The author mentioned that for a new project, training a deep learning model requires a large amount of labeled data, which is difficult. Therefore, the author first trained a pre-trained model on ImageNet 2012, and used the parameters of the pre-trained model as initial parameters to fine-tune all convolutional layers, thereby reducing the difference between code images and images in ImageNet 2012.
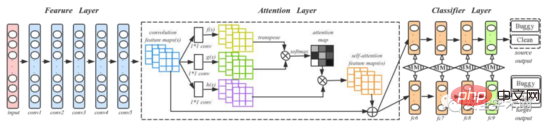
Fig. 5 Training and testing process
3. Model training and prediction
For the tagged code and Target in the Source project The unlabeled code in the project generates code images and feeds them into the model at the same time; both share the convolutional layer and the Attention layer to extract their respective features. Calculate MK-MDD (Multi Kernel Variant Maximum Mean Discrepancy) between Source and Target in the fully connected layer. Since Target has no label, cross entropy is only calculated for Source. The model is trained along the loss function using mini-batch stochastic gradient descent. For each
In the experimental part, the author selected all open source Java projects in the PROMISE data warehouse and collected their version numbers, class names, and whether there were bug tags. Download the source code from github based on the version number and class name. Finally, data from 10 Java projects were collected. The data set structure is shown in Figure 6.
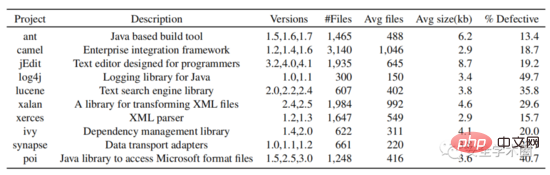
Fig. 6 Dataset structure
For intra-project defect prediction, the article selects the following baseline model for comparison:

For cross-project defect prediction, the article selects the following baseline model for comparison:

To summarize, although the paper was written two years ago, the idea is still relatively novel. , avoiding a series of code intermediate representations such as AST, and directly converting the code into image extraction features. But I am still confused. Does the image converted from the code really contain the semantic and structural information of the source code? It doesn’t feel very explainable, haha. We need to do some experimental analysis later.
The above is the detailed content of Using software visualization and transfer learning in software defect prediction. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 What software is bonjour and can it be uninstalled?
Feb 20, 2024 am 09:33 AM
What software is bonjour and can it be uninstalled?
Feb 20, 2024 am 09:33 AM
Title: Explore the Bonjour software and how to uninstall it Abstract: This article will introduce the functions, scope of use and how to uninstall the Bonjour software. At the same time, it will also be explained how to use other tools to replace Bonjour to meet the needs of users. Introduction: Bonjour is a common software in the field of computer and network technology. Although this may be unfamiliar to some users, it can be very useful in some specific situations. If you happen to have Bonjour software installed but now want to uninstall it, then
 What software is crystaldiskmark? -How to use crystaldiskmark?
Mar 18, 2024 pm 02:58 PM
What software is crystaldiskmark? -How to use crystaldiskmark?
Mar 18, 2024 pm 02:58 PM
CrystalDiskMark is a small HDD benchmark tool for hard drives that quickly measures sequential and random read/write speeds. Next, let the editor introduce CrystalDiskMark to you and how to use crystaldiskmark~ 1. Introduction to CrystalDiskMark CrystalDiskMark is a widely used disk performance testing tool used to evaluate the read and write speed and performance of mechanical hard drives and solid-state drives (SSD). Random I/O performance. It is a free Windows application and provides a user-friendly interface and various test modes to evaluate different aspects of hard drive performance and is widely used in hardware reviews
 What to do if WPS Office cannot open the PPT file - What to do if WPS Office cannot open the PPT file
Mar 04, 2024 am 11:40 AM
What to do if WPS Office cannot open the PPT file - What to do if WPS Office cannot open the PPT file
Mar 04, 2024 am 11:40 AM
Recently, many friends have asked me what to do if WPSOffice cannot open PPT files. Next, let us learn how to solve the problem of WPSOffice not being able to open PPT files. I hope it can help everyone. 1. First open WPSOffice and enter the homepage, as shown in the figure below. 2. Then enter the keyword "document repair" in the search bar above, and then click to open the document repair tool, as shown in the figure below. 3. Then import the PPT file for repair, as shown in the figure below.
![Corsair iCUE software not detecting RAM [Fixed]](https://img.php.cn/upload/article/000/465/014/170831448976874.png?x-oss-process=image/resize,m_fill,h_207,w_330) Corsair iCUE software not detecting RAM [Fixed]
Feb 19, 2024 am 11:48 AM
Corsair iCUE software not detecting RAM [Fixed]
Feb 19, 2024 am 11:48 AM
This article will explore what users can do when the CorsairiCUE software does not recognize the RAM in a Windows system. Although the CorsairiCUE software is designed to let users control their computer's RGB lighting, some users have found that the software does not function properly, resulting in an inability to detect RAM modules. Why doesn't ICUE pick up my memory? The main reason why ICUE cannot correctly identify RAM is usually related to background software conflicts. In addition, incorrect SPD write settings may also cause this problem. Fixed issue with CorsairIcue software not detecting RAM If CorsairIcue software is not detecting RAM on your Windows computer, please use the following suggestions.
 CrystalDiskinfo usage tutorial-What software is CrystalDiskinfo?
Mar 18, 2024 pm 04:50 PM
CrystalDiskinfo usage tutorial-What software is CrystalDiskinfo?
Mar 18, 2024 pm 04:50 PM
CrystalDiskInfo is a software used to check computer hardware devices. In this software, we can check our own computer hardware, such as reading speed, transmission mode, interface, etc.! So in addition to these functions, how to use CrystalDiskInfo and what exactly is CrystalDiskInfo? Let me sort it out for you! 1. The Origin of CrystalDiskInfo As one of the three major components of a computer host, a solid-state drive is the storage medium of a computer and is responsible for computer data storage. A good solid-state drive can speed up file reading and affect consumer experience. When consumers receive new devices, they can use third-party software or other SSDs to
 How to set the keyboard increment in Adobe Illustrator CS6 - How to set the keyboard increment in Adobe Illustrator CS6
Mar 04, 2024 pm 06:04 PM
How to set the keyboard increment in Adobe Illustrator CS6 - How to set the keyboard increment in Adobe Illustrator CS6
Mar 04, 2024 pm 06:04 PM
Many users are using the Adobe Illustrator CS6 software in their offices, so do you know how to set the keyboard increment in Adobe Illustrator CS6? Then, the editor will bring you the method of setting the keyboard increment in Adobe Illustrator CS6. Interested users can take a look below. Step 1: Start Adobe Illustrator CS6 software, as shown in the figure below. Step 2: In the menu bar, click the [Edit] → [Preferences] → [General] command in sequence. Step 3: The [Keyboard Increment] dialog box pops up, enter the required number in the [Keyboard Increment] text box, and finally click the [OK] button. Step 4: Use the shortcut key [Ctrl]
 What kind of software is bonjour? Is it useful?
Feb 22, 2024 pm 08:39 PM
What kind of software is bonjour? Is it useful?
Feb 22, 2024 pm 08:39 PM
Bonjour is a network protocol and software launched by Apple for discovering and configuring network services within a local area network. Its main role is to automatically discover and communicate between devices connected in the same network. Bonjour was first introduced in the MacOSX10.2 version in 2002, and is now installed and enabled by default in Apple's operating system. Since then, Apple has opened up Bonjour's technology to other manufacturers, so many other operating systems and devices can also support Bonjour.
 How to resolve an incompatible software attempt to load with Edge?
Mar 15, 2024 pm 01:34 PM
How to resolve an incompatible software attempt to load with Edge?
Mar 15, 2024 pm 01:34 PM
When we use the Edge browser, sometimes incompatible software attempts to be loaded together, so what is going on? Let this site carefully introduce to users how to solve the problem of trying to load incompatible software with Edge. How to solve an incompatible software trying to load with Edge Solution 1: Search IE in the start menu and access it directly with IE. Solution 2: Note: Modifying the registry may cause system failure, so operate with caution. Modify registry parameters. 1. Enter regedit during operation. 2. Find the path\HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Micros
