
 Technology peripherals
AI
Insert the Stable Diffusion model into the iPhone and make it into an APP to produce pictures in one minute
Technology peripherals
AI
Insert the Stable Diffusion model into the iPhone and make it into an APP to produce pictures in one minute
Insert the Stable Diffusion model into the iPhone and make it into an APP to produce pictures in one minute

Is it difficult to run Stable Diffusion on iPhone? In the article we are going to introduce today, the author gives the answer: it is not difficult, and the iPhone still has 50% performance left.
As we all know, every year Apple launches a new iPhone that claims to be faster and better in every way, mainly due to the rapid development of new vision models and image sensors. Take photography as an example. If you go back to 10 years ago, can you take high-quality pictures with an iPhone? The answer is no, because the development of technology is gradual. 10 years is enough to improve mobile phone photography technology.
Because of this (progressive) development pattern of technology, there will come a time when some programs will become almost unusable even on the best computing equipment. But these new programs with newly enabled scenarios attracted the attention of some users and people were willing to study it.
The author of this article is one of them. In the past 3 weeks, the author has developed an application that can generate (summon) images through Stable Diffusion, and then press your Edit it the way you like. The app takes just a minute to generate images on the latest iPhone 14 Pro, using about 2GiB of app memory, plus about 2GiB of initial data needs to be downloaded to get started.
App store link: https://apps.apple.com/us/app/draw-things-ai-generation/id6444050820
This result attracted many discussions among netizens. Some people began to worry about the power consumption of mobile phones, and joked: This is cool, but this seems to be a good way to consume mobile phone batteries.

"I have never been so happy to feel the heat of my iPhone."
"This In the cold winter, you can use your mobile phone as a hand warmer."
However, while everyone is making fun of the heating problem of mobile phones, they also give this work a very high rating.
"This is incredible. It takes about 45 seconds to generate a complete image on my iPhone SE3 - which is almost the same speed as the original version on my M1 Pro macbook Hurry!」

Optimize memory and hardware at the same time
How is this done? Next, let’s take a look at the author’s implementation process:
If you want to run Stable Diffusion on the iPhone and still have 50% performance savings, a major challenge is that you need 6GiB RAM Run the program on your iPhone device. 6GiB sounds like a lot, but if you use more than 2.8GiB on a 6GiB device, or 2GiB on a 4GiB device, iOS will kill your app.
So how much memory does the Stable Diffusion model require for inference?
This also starts with the structure of the model. Usually the Stable Diffusion model contains 4 parts: 1. Text encoder, which generates text feature vectors to guide image generation; 2. Optional image encoder, which encodes images into latent space (for image-to-image generation); 3 . Denoiser model, which slowly denoises the latent representation of the image from the noise; 4. Image decoder, which decodes the image from the latent representation.
The 1st, 2nd and 4th modules are run once during inference and require a maximum of about 1GiB. The denoiser model takes about 3.2GiB (full floating point) and needs to be executed multiple times, so the author wants to keep the module in RAM longer.
The original Stable Diffusion model required close to 10GiB to perform single image inference. Between a single input (2x4x64x64) and an output (2x4x64x64), there are many output layers interspersed. Not all layer outputs can be reused immediately, some of them must retain some parameters for subsequent use (residual networks).
For some time, researchers have been optimizing PyTorch Stable Diffusion. They have reserved temporary storage space for the NVIDIA CUDNN and CUBLAS libraries used by PyTorch. These optimizations are all to reduce memory usage. Therefore the Stable Diffusion model can run with cards as low as 4GiB.
But it still exceeded the author’s expectations. Therefore, the author began to focus on Apple hardware and optimization.
At first, the author considered 3.2GiB or 1.6GiB half floating point number. If he did not want to trigger Apple's OOM (Out of Memory, which refers to the memory occupied by the App reaching the limit of the iOS system for a single After the app occupies the upper memory limit and is forcibly killed by the system), the author has about 500MiB of space to use.
The first question is, what is the size of each intermediate output?
It turns out that most of them are relatively small, under 6MiB each (2x320x64x64). The framework used by the author (s4nnc) can reasonably package them into less than 50MiB for reuse.
It is worth mentioning that the denoiser has a self-attention mechanism that takes its own latent representation of the image as input. During the self-attention computation, there is a batch matrix of size 16x4096x4096, which after applying softmax is about 500MiB in FP16 and can be done "inplace", which means it can safely rewrite its input without Will not be damaged. Fortunately, both Apple and NVIDIA low-level libraries provide inplace softmax implementations, whereas higher-level libraries such as PyTorch do not.
So can it really be done using about 550MiB and 1.6GiB of memory?
On Apple hardware, a common choice for implementing a neural network backend is to use the MPSGraph framework. So the author first tried to use MPSGraph to implement all neural network operations. The peak memory usage at FP16 precision is about 6GiB, which is obviously much more than the expected memory usage. What's going on?
The author analyzed the reasons in detail. First, he did not use MPSGraph in the common TensorFlow way. MPSGraph requires encoding the entire computational graph, then consuming input/output tensors, handling internal allocations, and letting the user submit the entire graph for execution.
The author uses MPSGraph very much like PyTorch - as an operation execution engine. To perform inference tasks, many compiled MPSGraphExecutables are executed on the Metal command queue, each of which may hold some intermediate allocated memory. If submitted in one go, all these commands hold allocated memory until they complete execution.
A simple way to solve this problem is to adjust the submission speed. There is no need to submit all commands at once. In fact, Metal has a limit of 64 concurrent submissions per queue. The author tried changing to submitting 8 operations at a time, and the peak memory was reduced to 4GiB.
However, that's still 2 GiB more than the iPhone can handle.
To compute self-attention using CUDA, there is a common trick in the original Stable Diffusion code implementation: use permutation instead of transpose. This trick works because CUBLAS can handle permuted strided tensors directly, avoiding the need to use dedicated memory to transpose the tensor.
But MPSGraph does not have strided tensor support, a permuted tensor will be transposed internally anyway, which requires intermediate memory allocation. By explicitly transposing, allocations will be handled by higher-level layers, avoiding MPSGraph internal inefficiencies. Using this trick, the memory usage will be close to 3GiB.
It turns out that starting with iOS 16.0, MPSGraph can no longer make optimal allocation decisions for softmax. Even if the input and output tensors both point to the same data, MPSGraph allocates an additional output tensor and then copies the result to the location pointed to.
The author found that using the Metal Performance Shaders alternative met the requirements perfectly and reduced the memory usage to 2.5GiB without any performance degradation.
On the other hand, MPSGraph's GEMM kernel requires internal transposition. Explicit transposes won't help here either, since these transposes are not "inplace" operations of higher-level layers, and for a specific 500MiB size tensor, this extra allocation is unavoidable. By switching to Metal Performance Shaders, the project authors reclaimed another 500MiB with a performance penalty of about 1%, ultimately reducing memory usage to the ideal 2GiB.
The above is the detailed content of Insert the Stable Diffusion model into the iPhone and make it into an APP to produce pictures in one minute. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
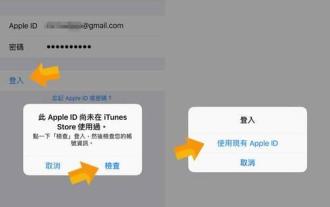 Steps and precautions for registering a Hong Kong Apple ID (enjoy the unique advantages of the Hong Kong Apple Store)
Sep 02, 2024 pm 03:47 PM
Steps and precautions for registering a Hong Kong Apple ID (enjoy the unique advantages of the Hong Kong Apple Store)
Sep 02, 2024 pm 03:47 PM
Apple's products and services have always been loved by users around the world. Registering a Hong Kong Apple ID will bring more convenience and privileges to users. Let’s take a look at the steps to register a Hong Kong Apple ID and what you need to pay attention to. How to register a Hong Kong Apple ID When using Apple devices, many applications and functions require using Apple ID to log in. If you want to download applications from Hong Kong or enjoy the preferential content of the Hong Kong AppStore, it is very necessary to register a Hong Kong Apple ID. This article will detail the steps on how to register a Hong Kong Apple ID and what you need to pay attention to. Steps: Select language and region: Find the "Settings" option on your Apple device and enter
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
