

Eight ready-to-use Python automation scripts!


Every day you may perform many repetitive tasks, such as reading news, sending emails, checking the weather, cleaning folders, etc. With automated scripts, you don’t need to do it manually again and again. It is very convenient to complete these tasks. To a certain extent, Python is synonymous with automation.
Today I share 8 very useful Python automation scripts. If you like, remember to collect, follow and like.
1. Automatically read web news
This script can capture text from the web page and then automatically read it by voice. When you want to listen to the news, this is a Not a bad choice.
The code is divided into two parts. The first is to crawl the web page text, and the second is to read the text aloud through the reading tool.
Required third-party libraries:
Beautiful Soup - a classic HTML/XML text parser, used to extract crawled web page information.
requests - A very useful HTTP tool for sending requests to web pages to obtain data.
Pyttsx3 - Convert text to speech and control rate, frequency and voice.
import pyttsx3
import requests
from bs4 import BeautifulSoup
engine = pyttsx3.init('sapi5')
voices = engine.getProperty('voices')
newVoiceRate = 130 ## Reduce The Speech Rate
engine.setProperty('rate',newVoiceRate)
engine.setProperty('voice', voices[1].id)
def speak(audio):
engine.say(audio)
engine.runAndWait()
text = str(input("Paste articlen"))
res = requests.get(text)
soup = BeautifulSoup(res.text,'html.parser')
articles = []
for i in range(len(soup.select('.p'))):
article = soup.select('.p')[i].getText().strip()
articles.append(article)
text = " ".join(articles)
speak(text)
# engine.save_to_file(text, 'test.mp3') ## If you want to save the speech as a audio file
engine.runAndWait()2. Automated data exploration
Data exploration is the first step in a data science project. You need to understand the basic information of the data to further analyze the deeper value.
Generally, we use pandas, matplotlib and other tools to explore data, but we need to write a lot of code ourselves. If we want to improve efficiency, Dtale is a good choice.
Dtale is characterized by generating automated analysis reports with one line of code. It combines the Flask backend and React frontend to provide us with an easy way to view and analyze Pandas data structures.
We can use Dtale on Jupyter.
Required third-party libraries:
Dtale - Automatically generate analysis reports.
### Importing Seaborn Library For Some Datasets
import seaborn as sns
### Printing Inbuilt Datasets of Seaborn Library
print(sns.get_dataset_names())
### Loading Titanic Dataset
df=sns.load_dataset('titanic')
### Importing The Library
import dtale
#### Generating Quick Summary
dtale.show(df)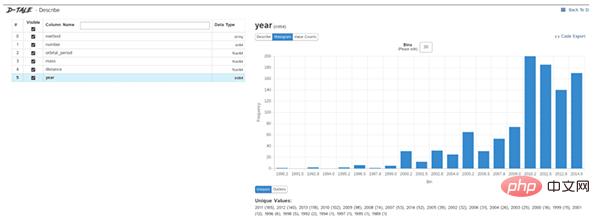
3. Automatically send multiple emails
This script can help us send emails in batches and at regular intervals. The email content and attachments can also be customized. Adjustment is very practical.
Compared with email clients, the advantage of Python scripts is that they can deploy email services intelligently, in batches, and with high customization.
Required third-party libraries:
Email - for managing email messages
Smtlib - for sending emails to SMTP servers, It defines an SMTP client session object that can send mail to any computer on the Internet with an SMTP or ESMTP listener
Pandas - Tool for data analysis and cleaning.
import smtplib
from email.message import EmailMessage
import pandas as pd
def send_email(remail, rsubject, rcontent):
email = EmailMessage()## Creating a object for EmailMessage
email['from'] = 'The Pythoneer Here'## Person who is sending
email['to'] = remail## Whom we are sending
email['subject'] = rsubject ## Subject of email
email.set_content(rcontent) ## content of email
with smtplib.SMTP(host='smtp.gmail.com',port=587)as smtp:
smtp.ehlo() ## server object
smtp.starttls() ## used to send data between server and client
smtp.login("deltadelta371@gmail.com","delta@371") ## login id and password of gmail
smtp.send_message(email)## Sending email
print("email send to ",remail)## Printing success message
if __name__ == '__main__':
df = pd.read_excel('list.xlsx')
length = len(df)+1
for index, item in df.iterrows():
email = item[0]
subject = item[1]
content = item[2]
send_email(email,subject,content)4. Convert PDF to audio file
The script can convert pdf to audio file. The principle is also very simple. First use PyPDF to extract the text in the pdf, and then use Pyttsx3 Convert text to speech.
import pyttsx3,PyPDF2
pdfreader = PyPDF2.PdfFileReader(open('story.pdf','rb'))
speaker = pyttsx3.init()
for page_num in range(pdfreader.numPages):
text = pdfreader.getPage(page_num).extractText()## extracting text from the PDF
cleaned_text = text.strip().replace('n',' ')## Removes unnecessary spaces and break lines
print(cleaned_text)## Print the text from PDF
#speaker.say(cleaned_text)## Let The Speaker Speak The Text
speaker.save_to_file(cleaned_text,'story.mp3')## Saving Text In a audio file 'story.mp3'
speaker.runAndWait()
speaker.stop()5. Play random music from the list
This script will randomly select a song from the song folder to play. What needs to be noted is os.startfile Only supports Windows systems.
import random, os music_dir = 'G:\new english songs' songs = os.listdir(music_dir) song = random.randint(0,len(songs)) print(songs[song])## Prints The Song Name os.startfile(os.path.join(music_dir, songs[0]))
6. Intelligent weather information
The National Weather Service website provides an API for obtaining weather forecasts, which directly returns weather data in json format. So you only need to extract the corresponding fields from json.
The following is the URL of the weather for the designated city (county, district). Open the URL directly and the weather data of the corresponding city will be returned. For example:
http://www.weather.com.cn/data/cityinfo/101021200.html The weather URL corresponding to Xuhui District, Shanghai.
The specific code is as follows:
mport requests
import json
import logging as log
def get_weather_wind(url):
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
info = json.loads(r.content.decode())
# get wind data
data = info['weatherinfo']
WD = data['WD']
WS = data['WS']
return "{}({})".format(WD, WS)
def get_weather_city(url):
# open url and get return data
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
# convert string to json
info = json.loads(r.content.decode())
# get useful data
data = info['weatherinfo']
city = data['city']
temp1 = data['temp1']
temp2 = data['temp2']
weather = data['weather']
return "{} {} {}~{}".format(city, weather, temp1, temp2)
if __name__ == '__main__':
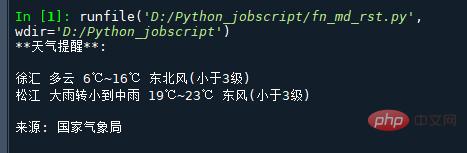
msg = """**天气提醒**:
{} {}
{} {}
来源: 国家气象局
""".format(
get_weather_city('http://www.weather.com.cn/data/cityinfo/101021200.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101021200.html'),
get_weather_city('http://www.weather.com.cn/data/cityinfo/101020900.html'),
get_weather_wind('http://www.weather.com.cn/data/sk/101020900.html')
)
print(msg)The running result is as follows:
7, long URL Shortening URL
Sometimes those big URLs become really annoying and hard to read and share, this kick can turn long URLs into short URLs.
import contextlib
from urllib.parse import urlencode
from urllib.request import urlopen
import sys
def make_tiny(url):
request_url = ('http://tinyurl.com/api-create.php?' +
urlencode({'url':url}))
with contextlib.closing(urlopen(request_url)) as response:
return response.read().decode('utf-8')
def main():
for tinyurl in map(make_tiny, sys.argv[1:]):
print(tinyurl)
if __name__ == '__main__':
main()This script is very practical. For example, if a content platform blocks public account articles, you can change the link of the public account article into a short link and then insert it into it to achieve bypass.
8. Clean the download folder
One of the most confusing things in the world is the developer's download folder, which contains a lot of disorganized files. This script Your downloads folder will be cleaned based on size limits, with limited cleaning of older files:
import os
import threading
import time
def get_file_list(file_path):
#文件按最后修改时间排序
dir_list = os.listdir(file_path)
if not dir_list:
return
else:
dir_list = sorted(dir_list, key=lambda x: os.path.getmtime(os.path.join(file_path, x)))
return dir_list
def get_size(file_path):
"""[summary]
Args:
file_path ([type]): [目录]
Returns:
[type]: 返回目录大小,MB
"""
totalsize=0
for filename in os.listdir(file_path):
totalsize=totalsize+os.path.getsize(os.path.join(file_path, filename))
#print(totalsize / 1024 / 1024)
return totalsize / 1024 / 1024
def detect_file_size(file_path, size_Max, size_Del):
"""[summary]
Args:
file_path ([type]): [文件目录]
size_Max ([type]): [文件夹最大大小]
size_Del ([type]): [超过size_Max时要删除的大小]
"""
print(get_size(file_path))
if get_size(file_path) > size_Max:
fileList = get_file_list(file_path)
for i in range(len(fileList)):
if get_size(file_path) > (size_Max - size_Del):
print ("del :%d %s" % (i + 1, fileList[i]))
#os.remove(file_path + fileList[i])The above is the detailed content of Eight ready-to-use Python automation scripts!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Google AI announces Gemini 1.5 Pro and Gemma 2 for developers
Jul 01, 2024 am 07:22 AM
Google AI announces Gemini 1.5 Pro and Gemma 2 for developers
Jul 01, 2024 am 07:22 AM
Google AI has started to provide developers with access to extended context windows and cost-saving features, starting with the Gemini 1.5 Pro large language model (LLM). Previously available through a waitlist, the full 2 million token context windo
 How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download DeepSeek Xiaomi? Search for "DeepSeek" in the Xiaomi App Store. If it is not found, continue to step 2. Identify your needs (search files, data analysis), and find the corresponding tools (such as file managers, data analysis software) that include DeepSeek functions.
 How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
The key to using DeepSeek effectively is to ask questions clearly: express the questions directly and specifically. Provide specific details and background information. For complex inquiries, multiple angles and refute opinions are included. Focus on specific aspects, such as performance bottlenecks in code. Keep a critical thinking about the answers you get and make judgments based on your expertise.
 Tsinghua University and Zhipu AI open source GLM-4: launching a new revolution in natural language processing
Jun 12, 2024 pm 08:38 PM
Tsinghua University and Zhipu AI open source GLM-4: launching a new revolution in natural language processing
Jun 12, 2024 pm 08:38 PM
Since the launch of ChatGLM-6B on March 14, 2023, the GLM series models have received widespread attention and recognition. Especially after ChatGLM3-6B was open sourced, developers are full of expectations for the fourth-generation model launched by Zhipu AI. This expectation has finally been fully satisfied with the release of GLM-4-9B. The birth of GLM-4-9B In order to give small models (10B and below) more powerful capabilities, the GLM technical team launched this new fourth-generation GLM series open source model: GLM-4-9B after nearly half a year of exploration. This model greatly compresses the model size while ensuring accuracy, and has faster inference speed and higher efficiency. The GLM technical team’s exploration has not
 How to search deepseek
Feb 19, 2025 pm 05:18 PM
How to search deepseek
Feb 19, 2025 pm 05:18 PM
Just use the search function that comes with DeepSeek. Its powerful semantic analysis algorithm can accurately understand the search intention and provide relevant information. However, for searches that are unpopular, latest information or problems that need to be considered, it is necessary to adjust keywords or use more specific descriptions, combine them with other real-time information sources, and understand that DeepSeek is just a tool that requires active, clear and refined search strategies.
 The Mistral open source code model takes the throne! Codestral is crazy about training in over 80 languages, and domestic Tongyi developers are asking to participate!
Jun 08, 2024 pm 09:55 PM
The Mistral open source code model takes the throne! Codestral is crazy about training in over 80 languages, and domestic Tongyi developers are asking to participate!
Jun 08, 2024 pm 09:55 PM
Produced by 51CTO technology stack (WeChat ID: blog51cto) Mistral released its first code model Codestral-22B! What’s crazy about this model is not only that it’s trained on over 80 programming languages, including Swift, etc. that many code models ignore. Their speeds are not exactly the same. It is required to write a "publish/subscribe" system using Go language. The GPT-4o here is being output, and Codestral is handing in the paper so fast that it’s hard to see! Since the model has just been launched, it has not yet been publicly tested. But according to the person in charge of Mistral, Codestral is currently the best-performing open source code model. Friends who are interested in the picture can move to: - Hug the face: https
 How to program deepseek
Feb 19, 2025 pm 05:36 PM
How to program deepseek
Feb 19, 2025 pm 05:36 PM
DeepSeek is not a programming language, but a deep search concept. Implementing DeepSeek requires selection based on existing languages. For different application scenarios, it is necessary to choose the appropriate language and algorithms, and combine machine learning technology. Code quality, maintainability, and testing are crucial. Only by choosing the right programming language, algorithms and tools according to your needs and writing high-quality code can DeepSeek be successfully implemented.
 How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
Question: Is DeepSeek available for accounting? Answer: No, it is a data mining and analysis tool that can be used to analyze financial data, but it does not have the accounting record and report generation functions of accounting software. Using DeepSeek to analyze financial data requires writing code to process data with knowledge of data structures, algorithms, and DeepSeek APIs to consider potential problems (e.g. programming knowledge, learning curves, data quality)
