

Construction of automotive knowledge graph for recommendation

Background
1. Introduction
The concept of knowledge graph was first proposed by Google in 2012, aiming to achieve a more intelligent search engine, and began to be used in academia after 2013. and industrial-grade popularization. At present, with the rapid development of artificial intelligence technology, knowledge graphs have been widely used in search, recommendation, advertising, risk control, intelligent scheduling, speech recognition, robots and other fields.
2. Development status
Knowledge graph, as the core technology driving force of artificial intelligence, can alleviate the problem of deep learning relying on massive training data and large-scale computing power. It can be widely adapted to different It can perform downstream tasks and has good interpretability. Therefore, large Internet companies around the world are actively deploying their own knowledge graphs.
For example, in 2013, Facebook released Open Graph, which was used for intelligent search on social networks; in 2014, Baidu launched the knowledge graph, which was mainly used in search, assistant, and toB business scenarios; in 2015, Alibaba launched the product knowledge graph. It plays a key role in front-end shopping guide, platform governance and intelligent question and answer business; Tencent Cloud Knowledge Graph launched by Tencent in 2017 effectively assists scenarios such as financial search and entity risk prediction; Meituan Brain launched by Meituan in 2018 Knowledge graphs have been implemented in multiple businesses such as intelligent search recommendations and intelligent merchant operations.
3. Goals and benefits
Currently, the domain map is mainly concentrated in business fields such as e-commerce, medical care, and finance, while the semantic network of automotive knowledge And there is a lack of systematic guidance method for knowledge graph construction. This article takes knowledge in the automotive field as an example, focusing on entities and relationships such as car series, models, dealers, manufacturers, brands, etc., to provide an idea for building a domain map from scratch, and details the steps and methods in building a knowledge map. Description, and introduces several typical applications based on this map.
The data source is the Autohome website. Autohome is an automotive service platform composed of multiple sections such as shopping guides, information, reviews, and word-of-mouth. It has accumulated a large number of views, purchases, and uses. Car data is organized and mined by building a knowledge graph to organize and mine car-centered content, providing rich knowledge information, structured and accurately depicting interests, and supporting multiple dimensions such as cold start, recall, sorting, and display of recommended users, to provide business Lift brings results.
2. Graph construction
1. Construction challenges
Knowledge graph is a semantic representation of the real world, and its basic unit is [entity-relationship-entity]. A triplet of [entity-attribute-attribute value], entities are connected to each other through relationships, thus forming a semantic network. There will be greater challenges in constructing the graph, but after it is constructed, it can show rich application value in multiple scenarios such as data analysis, recommendation calculation, and interpretability.
Construction challenges:
- Schema is difficult to define: there is currently no unified and mature ontology construction process, and the definition of ontology in specific fields usually requires the participation of experts;
- Heterogeneous data types: Usually, the data sources faced in the construction of a knowledge graph will not be of a single type, including structured, semi-structured, and unstructured data, and data with different structures will be faced. , knowledge transfer and mining are more difficult;
- Rely on professional knowledge: Domain knowledge graphs usually rely on strong professional knowledge, such as maintenance methods corresponding to vehicle models, involving machinery, electrical engineering, materials, mechanics, etc. Domain knowledge, and this type of relationship has high requirements for accuracy, and it is necessary to ensure that the knowledge is correct enough. Therefore, a better combination of experts and algorithms is also needed for efficient graph construction;
- No data quality Guarantee: Mining or extracting information requires knowledge fusion or manual verification before it can be used as knowledge to assist downstream applications.
Benefit:
- Knowledge graph unifies knowledge representation: forming a unified view by integrating multi-source heterogeneous data;
- Rich semantic information: New relationship edges can be discovered through relational reasoning and richer semantic information can be obtained;
- Strong interpretability: Explicit reasoning paths are more interpretable than deep learning results;
- High quality and continuous accumulation: Design a reasonable knowledge storage solution based on business scenarios to achieve knowledge update and accumulation.
2. Graph architecture design
The technical architecture is mainly divided into three layers: construction layer, storage layer and application layer. The architecture diagram is as follows:
- Building layer: including schema definition, structured data transformation, unstructured data mining, and knowledge fusion;
- Storage layer: including knowledge storage and indexing, knowledge update, metadata Management, and support basic knowledge query;
- Service layer: including intelligent reasoning, structured query and other business-related downstream application layers.

3. Specific construction steps and processes
According to the architecture diagram, the specific construction process can be divided into four steps: ontology design, knowledge acquisition, Knowledge storage, and application service design and use.
3.1 Ontology construction
Ontology is a recognized collection of concepts. The construction of ontology refers to constructing the ontology structure and knowledge framework of the knowledge graph based on the definition of ontology.
The main reasons for constructing a graph based on ontology are as follows:
- Clear professional terms, relationships and their domain axioms. When a piece of data must satisfy the pre-defined Schema Entity objects and types are allowed to be updated into the knowledge graph.
- Separate domain knowledge and operational knowledge. Through Schema, you can gain a macroscopic understanding of the graph structure and related definitions, without the need to summarize and organize from triples.
- Achieve a certain degree of domain knowledge reuse. Before building an ontology, you can first investigate whether a relevant ontology has been built, so that you can improve and expand based on the existing ontology to achieve twice the result with half the effort.
- Based on the definition of ontology, it can avoid the situation where the graph is disconnected from the application, or the cost of modifying the graph schema is higher than rebuilding it. For example, storing "BMW x3" and "2022 BMW x3" as car entities may cause confusion in instance relationships and poor usability when applied. This situation can be solved by converting "car" into the ontology design stage. This can be avoided by subdividing "car series" and "model" subcategories into "class entities".
According to the coverage of knowledge, knowledge graphs can be divided into general knowledge graphs and domain knowledge graphs. Currently, there are many cases of general knowledge graphs, such as Google’s Knowledge Graph, Microsoft’s Satori and Probase etc. The domain map is a map of specific industries such as finance and e-commerce. General graphs pay more attention to breadth and emphasize the integration of more entities, but do not have high requirements for accuracy. It is difficult to reason and use axioms, rules and constraints with the help of ontology libraries; while the knowledge coverage of domain graphs is smaller, But the depth of knowledge is deeper and is often built in a certain professional field.
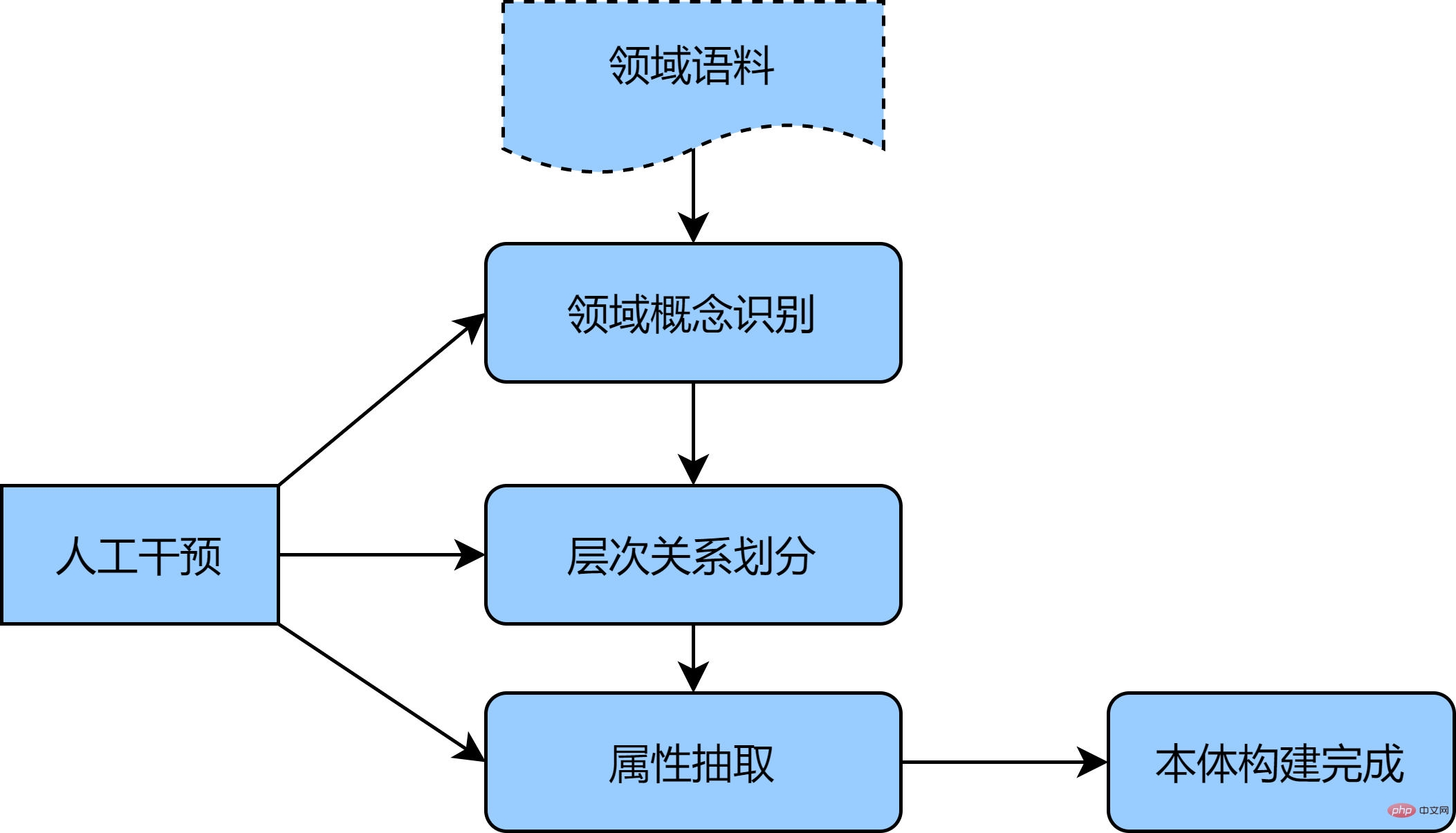
Considering the requirements for accuracy, domain ontology construction tends to be done manually, such as the representative seven-step method, IDEF5 method, etc. [1]. The core idea of this type of method is to Structured data, conduct ontology analysis, summarize and construct an ontology that meets the application purpose and scope, and then optimize and verify the ontology to obtain the first version of the ontology definition. If you want to obtain a larger domain ontology, you can supplement it from unstructured corpus. Considering that the manual construction process is relatively large, this article takes the automotive field as an example to provide a method of semi-automatic ontology construction. The detailed steps are as follows:
- First collect a large amount of unstructured automotive corpus (such as car series consultation, new car shopping guide articles, etc.) as an initial individual concept set, using statistical methods or unsupervised models (TF-IDF, BERT, etc.) to obtain character features and word features;
- Secondly, the BIRCH clustering algorithm is used to divide the concepts into hierarchies, initially build a hierarchical relationship between concepts, and perform manual concept verification and induction on the clustering results to obtain Equivalence, superior and inferior concepts of ontology;
- Finally, convolutional neural network combined with remote supervision method is used to extract the entity relationship of ontology attributes, supplemented by manual identification of the concepts of classes and attributes in the ontology, to construct Automotive domain ontology.
The above method can effectively use deep learning technologies such as BERT to better capture the internal relationships between corpus, use clustering to construct each module of the ontology hierarchically, supplemented by manual intervention, and can quickly , Accurately complete the preliminary ontology construction. The following figure is a schematic diagram of semi-automated ontology construction:
Using the Protégé ontology construction tool [2], the ontology concept can be carried out The construction of classes, relationships, attributes and instances. The following figure is a visual example of ontology construction:
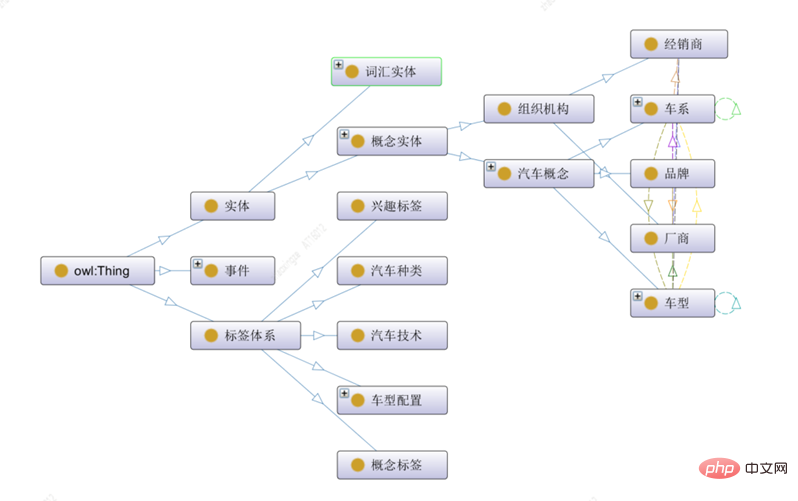
This article divides the top-level ontology concepts in the automotive field into three categories: entities and events And label system:
1) Entity class represents conceptual entities with specific meanings, including vocabulary entities and automobile entities, among which automobile entities include sub-entity types such as organizations and automobile concepts;
2) Label system represents Tag systems in various dimensions, including content classification, concept tags, interest tags and other tags described in the material dimension;
3) Event classes represent the objective facts of one or more roles, and there is an evolutionary relationship between different types of events .
Protégé Different types of Schema configuration files can be exported, among which the owl.xml structure configuration file is as shown in the figure below. This configuration file can be directly loaded and used in MYSQL and JanusGraph to realize automatic creation of Schema.

3.2 Knowledge Acquisition
The data sources of knowledge graphs usually include three types of data structures, namely structured data, semi-structured data, Unstructured data. For different types of data sources, the key technologies involved in knowledge extraction and the technical difficulties that need to be solved are different.
3.2.1 Structured knowledge transfer
Structured data is the most direct source of knowledge for the graph. It can be used basically through preliminary conversion. Compared with other types of data, the cost is the lowest. Therefore, generally graph data gives priority to structured data. Structured data may involve multiple database sources, and usually requires the use of ETL methods to convert the model. ETL refers to Extract, Transform, and Load. Extraction is to read data from various original business systems. , which is the premise of all work; conversion is to convert the extracted data according to pre-designed rules so that the originally heterogeneous data formats can be unified; loading is to import the converted data incrementally or entirely into the data as planned In the warehouse.
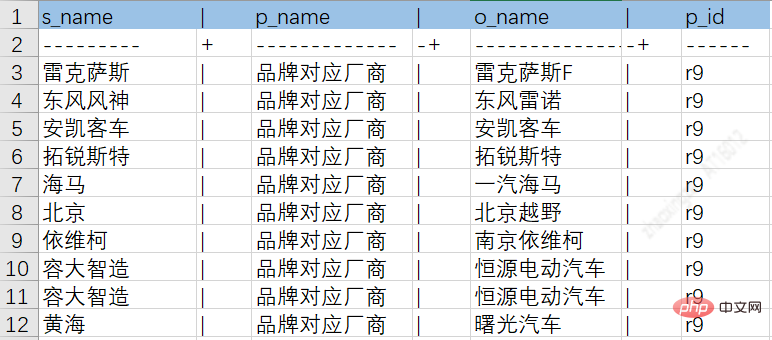
Through the above ETL process, data from different sources can be dropped into intermediate tables to facilitate subsequent knowledge storage. The following figure is an example diagram of car series entity attributes and relationship tables:
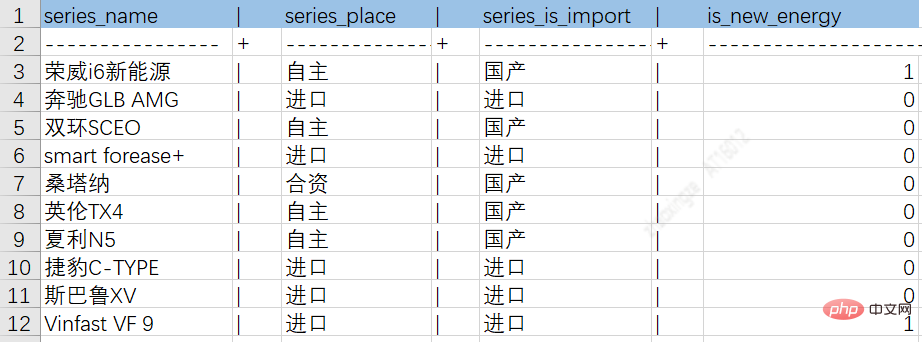
Car series and brand relationship table:
3.2.2 Unstructured knowledge extraction-Triple extraction
In addition to structured data, there is also a large amount of knowledge (triple) information in unstructured data. Generally speaking, the amount of unstructured data in an enterprise is much larger than structured data. Mining unstructured knowledge can greatly expand and enrich the knowledge graph.
Challenges of triple extraction algorithm
Problem 1: Within a single field, document content and formats are diverse, requiring a large amount of annotated data and high cost
Problem 2: The effect of migration between fields is not good enough, and the cost of scalable expansion across fields is high
The models are basically aimed at specific scenarios in specific industries. If you change the scenario, the effect will be different. There was a significant decline.
Solution idea, Pre-train Finetune paradigm, pre-training: the heavyweight base allows the model to "see more" and make full use of large-scale and multi-industry unlabeled documents to train a unified Pre-training base enhances the model's ability to represent and understand various types of documents.
Fine-tuning: lightweight document structuring algorithm. Based on pre-training, a lightweight document-oriented structured algorithm is constructed to reduce labeling costs.
Pre-training method for documents
There are existing pre-training models for documents. If the text is shorter, Bert can completely encode the entire text. files; however, our actual documents are usually relatively long, and many of the attribute values that need to be extracted exceed 1024 characters. Bert’s encoding will cause the attribute values to be truncated.
Advantages and shortcomings of long text pre-training methods
The Sparse Attention method optimizes the calculation of O(n2) to O(n) by optimizing Self-Attention. ), greatly improving the input text length. Although the text length of the ordinary model has been increased from 512 to 4096, it still cannot completely solve the fragmentation problem of truncated text. Baidu proposed ERNIE-DOC [3] using the Recurrence Transformer method, which can theoretically model unlimited text. Since all text information needs to be input for modeling, it is very time-consuming.
The above two pre-training methods based on long text do not consider document characteristics, such as spatial (Spartial), visual (Visual) and other information. And the PretrainTask based on the text design is designed for pure text as a whole, without the logical structure design of the document.
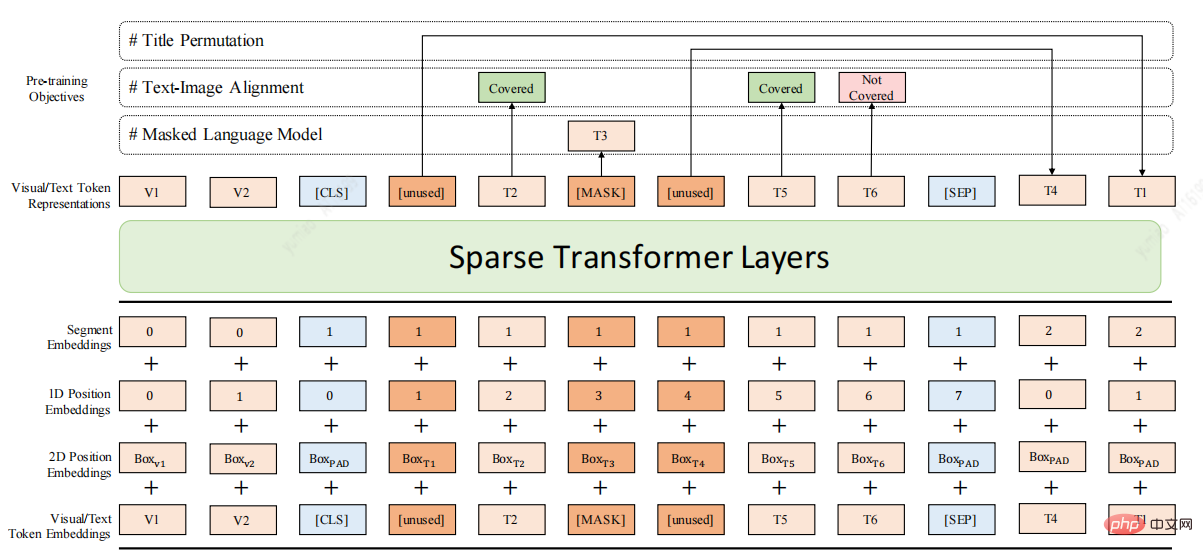
In view of the above shortcomings, here is a long document pre-training model DocBert[4], DocBert model design:
Use large-scale (million-level) unlabeled document data for pre-training, and build self-supervised learning tasks based on the text semantics (Text), layout information (Layout), and visual features (Visual) of the document , allowing the model to better understand document semantics and structural information.
1.Layout-Aware MLM: Consider the position and font size information of the text in the Mask language model to achieve document layout-aware semantic understanding.
2.Text-Image Alignment: Fusion of document visual features, reconstructing the masked text in the image, helping the model learn the alignment relationship between different modes of text, layout, and image.
3.Title Permutation: Construct the title reconstruction task in a self-supervised manner to enhance the model's ability to understand the logical structure of the document.
4.Sparse Transformer Layers: Use Sparse Attention method to enhance the model’s ability to process long documents.
3.2.3 Mining concepts, interest word tags, related to car series and entities
In addition to obtaining triples from structured and unstructured text , Autohome also mines the categories, concept tags and interest keyword tags contained in materials, and establishes associations between materials and vehicle entities, bringing new knowledge to the automotive knowledge graph. The following introduces some of the content understanding work and thinking done by Autohome from the perspective of classification, concept tags, and interest word tags.
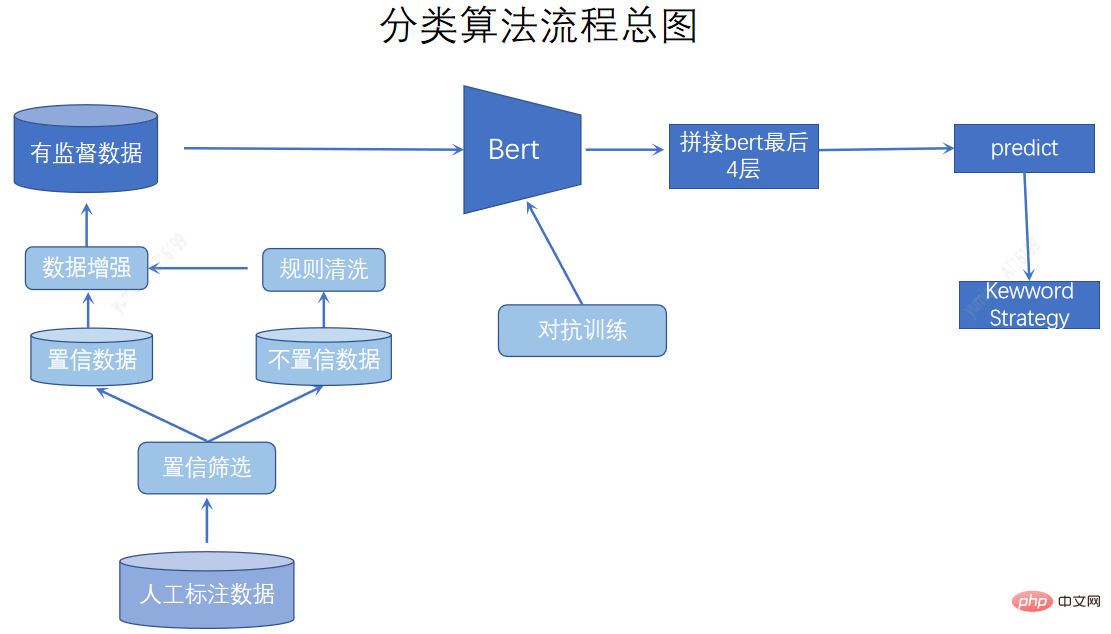
The classification system serves as the basis for content description and coarse-grained classification of materials. The unified content system established is more based on manual definition and is divided through AI models. In terms of classification methods, we use active learning to label data that is difficult to classify. We also use data enhancement, adversarial training, and keyword fusion to improve the classification effect.
The concept label granularity is between classification and interest word labels, finer than classification granularity, and more complete description of interest points than interest words. We have established a car vision The three dimensions of human vision and content vision enrich the label dimension and refine the label granularity. Rich and specific material tags make it easier to search and recommend tag-based model optimization, and can be used for tag outreach to attract users and secondary traffic. The mining of concept tags combines the use of machine mining methods on important data such as queries, and generalization analysis. Through manual review, we obtain a set of concept tags and use a multi-label model for classification.
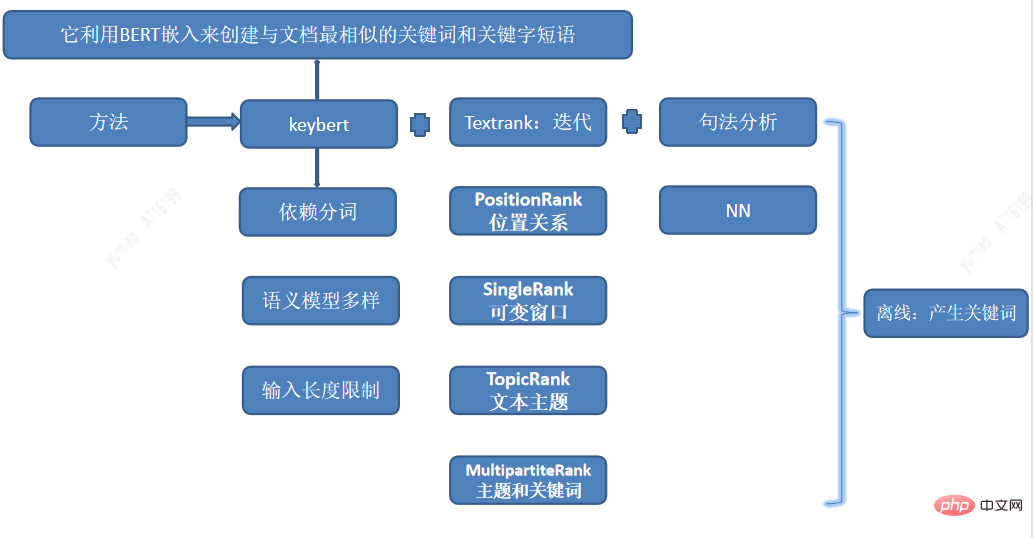
Interest word tags are the most fine-grained tags and are mapped to user interests. According to different user interest preferences, personalized recommendations can be better made. Keyword mining uses a combination of multiple interest word mining methods, including Keybert extraction of key substrings, combined with various syntax analysis methods such as TextRank, positionRank, singlerank, TopicRank, MultipartiteRank, etc. to generate interest word candidates.
The mined words have relatively high similarity, and synonyms need to be identified, which requires improving manual efficiency. Therefore, we also use clustering to perform automatic semantic similarity identification. Features used for clustering include word2vec, bert emding and other artificial features. Then using the clustering method, and finally through manual correction, we generated a batch of high-quality keywords offline.
For labels with different granularities, we still need to associate the labels with the cars at the material level. First, we calculate the labels of the title article respectively, and then identify the entities in the title article and obtain several labels. -Entity pseudo-labels. Finally, based on a large amount of corpus, labels with high co-occurrence probability will be marked as the label of the entity. Through the above three tasks, we have obtained rich and massive labels. Associating these tags with car series and entities will greatly enrich our car map and establish car tags that attract media and user attention.
3.2.4 Human efficiency improvement:
With larger-scale training samples, how to obtain better model quality, how to solve the high cost of labeling, and the long labeling cycle have become urgent problems to be solved . First, we can use semi-supervised learning to use massive unlabeled data for pre-training. Then an active learning method is used to maximize the value of the annotated data, and iteratively select high-information samples for annotation. Finally, remote supervision can be used to leverage the value of existing knowledge and discover the correlation between tasks. For example, after having the map and title, you can use remote supervision method to construct NER training data based on the map.
3.3 Knowledge storage
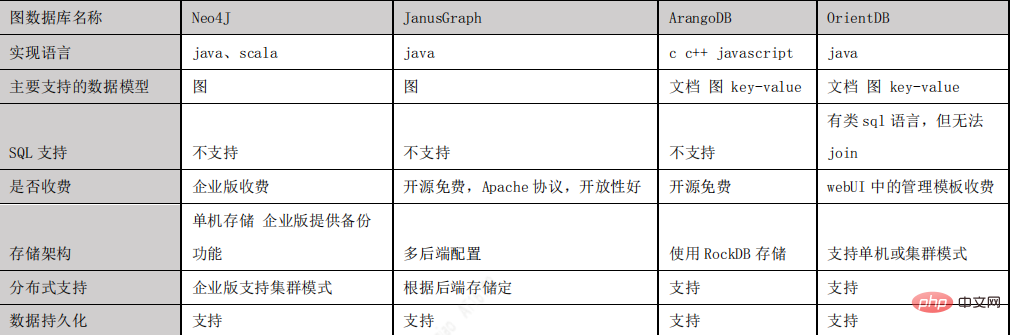
The knowledge in the knowledge graph is represented through the RDF structure, and its basic unit is a fact. Each fact is a triplet (S, P, O). In actual systems, according to different storage methods, the storage of knowledge graphs can be divided into storage based on RDF table structure and storage based on attribute graph structure. Picture galleries are mostly stored using attribute graph structures. Common storage systems include Neo4j, JanusGraph, OritentDB, InfoGrid, etc.
Graph database selection
After comparing JanusGraph with several mainstream graph databases such as Neo4J, ArangoDB, and OrientDB, we finally chose JanusGraph as the graph database for the project. The main reasons for choosing JanusGraph are as follows Reason:
- It is open source based on the Apache 2 license agreement and has good openness.
- Supports the use of Hadoop framework for global graph analysis and batch graph processing.
- Supports large concurrent transaction processing and graph operation processing. By adding machines to horizontally expand the transaction processing capabilities of JanusGraph, complex queries on large graphs can be processed at the millisecond level.
- Native support for the currently popular property graph data model described by Apache TinkerPop.
- Natively supports the graph traversal language Gremlin.
- The following picture is a comparison of mainstream graph databases:
Introduction to Janusgraph
JanusGraph[5] is a graph database engine. It focuses on compact graph serialization, rich graph data modeling, and efficient query execution. The composition of the gallery schema can be expressed by the following formula:
janusgraph schema = vertex label edge label property keys
It is worth noting here that the property key is usually used for graph index.
In order to achieve better graph query performance, janusgraph has established an index. The index is divided into Graph Index and Vertex-centric Indexes. Graph Index includes composite index (Composite Index) and mixed index (Mixed Index).
Combined index is limited to equal search. (The combined index does not need to configure an external index backend and is supported by the main storage backend (of course, hbase, Cassandra, and Berkeley can also be configured))
Example:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">mgmt</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">buildIndex</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'byNameAndAgeComposite'</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">Vertex</span>.<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">class</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">addKey</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">name</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">addKey</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">age</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">buildCompositeIndex</span>() <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">#构建一个组合索引“name</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">-</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">age”</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'age'</span>, <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">30</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'小明'</span>)<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">#查找</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">名字为小明年龄30的节点</span>
Hybrid index requires ES as the backend End index to support multi-condition queries other than equality (equal queries are also supported, but equal queries, combined indexes are faster). According to whether word segmentation is needed, it is divided into full-text search and string search
JanusGraph data storage model
Understanding the way Janusgraph stores data will help us make better use of the library. JanusGraph stores graphs in adjacency list format, which means that the graph is stored as a collection of vertices and their adjacency lists.
The adjacency list of a vertex contains all incident edges (and attributes) of the vertex.
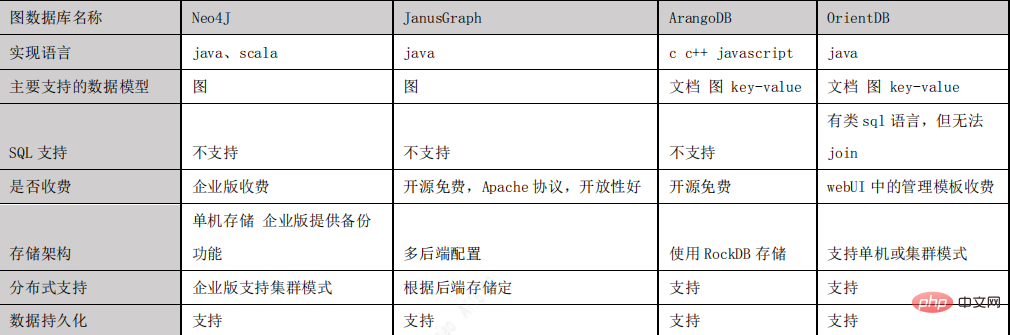
#JanusGraph stores each adjacency list as a row in the underlying storage backend. The (64-bit) vertex ID (uniquely assigned to each vertex by JanusGraph) is the key pointing to the row containing the vertex's adjacency list.
Each edge and attribute is stored as a separate cell in the row, allowing efficient insertion and deletion. Therefore, the maximum number of cells allowed per row in a particular storage backend is also the maximum degree of vertices that JanusGraph can support for that backend.
If the storage backend supports key-order, the adjacency list will be sorted by vertex id, and JanusGraph can assign vertex ids to effectively partition the graph. Assign ids so that frequently visited vertices have ids with small absolute differences.
3.4 GraphQuery Service
Janusgraph uses the gremlin language for graph search. We provide a unified graph query service. External users do not need to care about the specific implementation of the gremlin language. , using a common interface for querying. We divide it into three interfaces: conditional search interface, node-centered outward query, and inter-node path query interface. The following are several examples of gremlin implementation:
- Conditional search:Query the car with the highest sales volume of about 100,000:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'price'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">gt</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">8</span>)).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'price'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">lt</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">12</span>)).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">order</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">by</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'sales'</span>,<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">desc</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">valueMap</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">limit</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">1</span>)
Output:
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span>{<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">name</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xuanyi</span>], <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">price</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span>], <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sales</span><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span>[<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">45767</span>]}The Sylphy sales volume is the highest, which is 45767
- Query outwards with the node as the center: The query is centered on Xiao Ming, 2 degree node
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">repeat</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">out</span>()).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">times</span>(<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">2</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">valueMap</span>()
- Inter-node path query:Recommend two articles to Xiao Ming , these two articles introduce Corolla and Sylphy respectively. Query the path of Xiao Ming and these two articles:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">g</span>.<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">V</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">repeat</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">out</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">simplePath</span>()).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">until</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">or</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"car"</span>,<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'kaluola'</span>),<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">has</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"car"</span>, <span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'name'</span>,<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">'xuanyi'</span>))).<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>().<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">by</span>(<span style="color: rgb(102, 153, 0); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">"name"</span>)
Output
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">around</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">w</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">kaluola</span>]<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">==></span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">path</span>[<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xiaoming</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">around</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">10</span><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">w</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">xuanyi</span>]
Discover Xiao Ming and these two articles There is a node between the articles "about 100,000"
3. Knowledge graph in recommended applications
There is a large amount of non-European data in the knowledge graph. Recommendation applications based on KG effectively use non-European data to improve the accuracy of the recommendation system, and then Let the recommendation system achieve effects that traditional systems cannot achieve. Recommendations based on KG can be divided into three categories, based on KG representation technology (KGE), path-based method, and graph neural network. This chapter will introduce KG’s applications and papers in three aspects: cold start, reason, and ranking in recommendation systems.
3.1 Application of knowledge graph in recommending cold start
Knowledge graph can model the high-order relationships hidden in KG from user-item interaction, which is a good solution to the problem of user-related problems. The data sparsity caused by calling a limited number of behaviors can be applied to solve the cold start problem. There are also related studies on this issue in the industry.
Sang et al. [6] proposed a dual-channel neural interaction method called knowledge graph-enhanced residual recursive neural collaborative filtering (KGNCF-RRN), which exploits the long-term relationship dependencies of KG context and User items interact to make recommendations.
(1) For the KG context interaction channel, a residual recurrent network (RRN) is proposed to construct context-based path embedding, and residual learning is integrated into the traditional recurrent neural network (RNN) to effectively Encoding KG's long-term relational dependencies. Self-attention networks are then applied to path embeddings to capture the ambiguity of various user interaction behaviors.
(2) For the user-item interaction channel, user and item embeddings are input into the newly designed two-dimensional interaction diagram.
(3) Finally, on top of the dual-channel neural interaction matrix, a convolutional neural network is used to learn the complex correlation between users and items. This method can capture rich semantic information and also capture complex implicit relationships between users and items for recommendation.
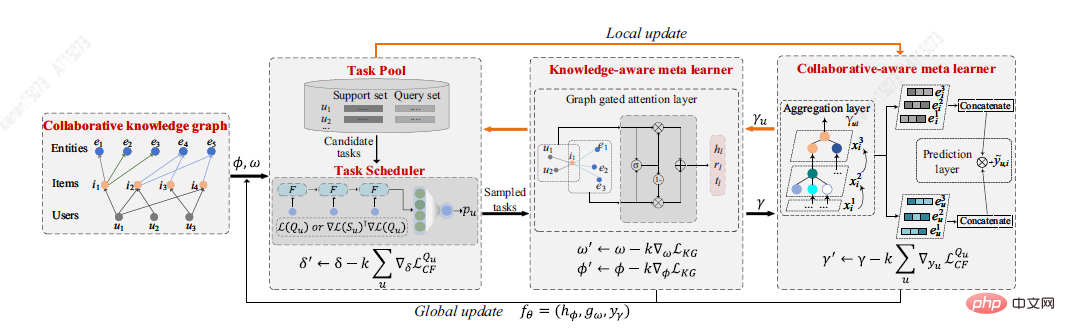
Du Y et al. [7] proposed a new solution to the cold start problem based on a meta-learning framework MetaKG, including collaborative-aware meta learner and knowledge-aware meta learner, capturing User preferences and entity cold start knowledge. The collaborative-aware meta learner learning task aims to aggregate each user's preferred knowledge representation. In contrast, the knowledge-aware meta learner learning task is to globally generalize different user-preferred knowledge representations. Under the guidance of two learners, MetaKG can effectively capture high-order collaborative relationships and semantic representations, and can easily adapt to cold start scenarios. In addition, the author also designed an adaptive task that can adaptively select KG information for learning to prevent the model from being interfered with by noise information. The MetaKG architecture is shown in the figure below.
3.2 Application of knowledge graph in generating recommendation reasons
Recommendation reasons can improve the interpretability of the recommendation system and allow users to understand The calculation process for generating recommendation results can also explain why the item is popular. Users understand the principle of generating recommended results through recommendation reasons, which can enhance users' confidence in the system's recommended results and make them more tolerant of incorrect results in the event of recommendation errors.
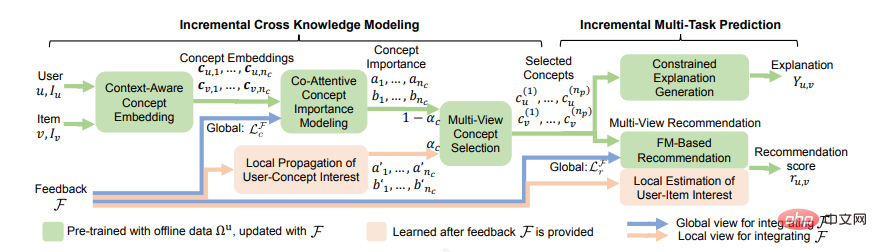
The earliest interpretable recommendations were based on templates. The advantage of templates is that they ensure readability and high accuracy. However, the templates need to be sorted manually, and they are not very general, giving people a repetitive feeling. Later, a free-form form that did not require presets was developed, and a knowledge graph was added. One of the paths was used as an explanation. Along with the annotation, there were some generative methods that combined KG paths. Each point or edge selected in the model was A reasoning process that can be demonstrated to the user. Recently, Chen Z [8] et al. proposed an incremental multi-task learning framework ECR, which can achieve close collaboration between recommendation prediction, explanation generation and user feedback integration. It consists of two parts. The first part, Incremental Cross Knowledge Modeling, learns the transferred cross knowledge in the recommendation task and the explanation task, and explains how to use the cross knowledge to be updated by using incremental learning. The second part, incremental multi-task prediction, explains how to generate explanations based on cross-knowledge and how to predict recommendation scores based on cross-knowledge and user feedback.
3.3 Application of knowledge graph in recommendation sorting
KG can create user- The interaction between items combines the uesr-item graph and KG into one large graph, which can capture the high-order connections between items. The traditional recommendation method is to model the problem as a supervised learning task. This method ignores the intrinsic relationship between items (such as the competitive product relationship between Camry and Accord) and cannot obtain synergistic signals from user behavior. The following introduces two papers on KG application in recommendation ranking.
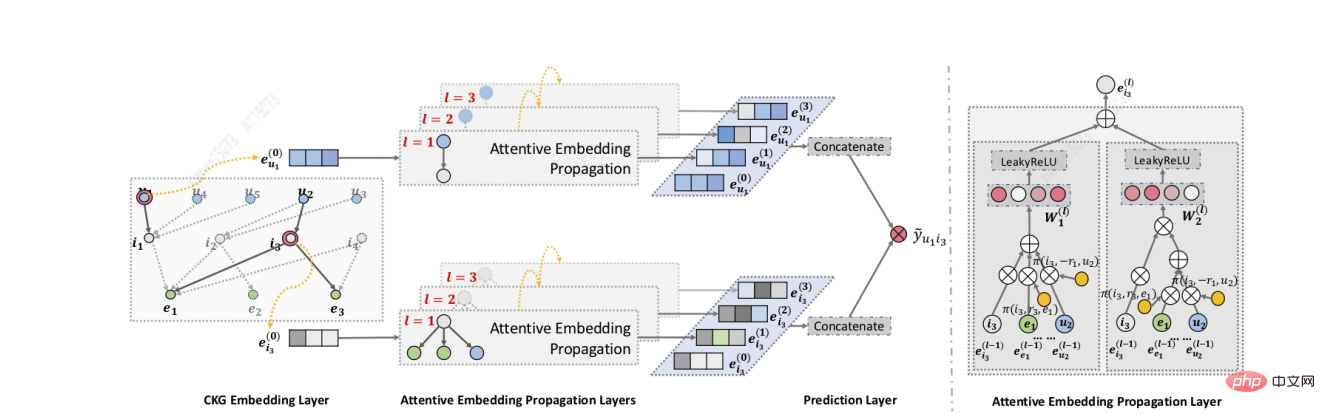
Wang[9] and others designed the KGAT algorithm. First, they used GNN to iteratively propagate and update the embedding, so that they can quickly capture high-order connections. Secondly, they used the attention mechanism during aggregation to learn each feature during the propagation process. The weight of the neighbor reflects the importance of high-order connections; finally, N implicit representations of user-item are obtained through N-order propagation updates, and different layers represent different orders of connection information. KGAT can capture richer, unspecific higher-order connections.
Zhang[20] and others proposed the RippleNet model. The key idea is interest propagation: RippleNet uses the user's historical interests as a seed set in KG, and then Expand user interests outward along the connections of KG to form the distribution of user interests on KG. The biggest advantage of RippleNet is that it can automatically mine possible paths from items that users have clicked on in history to candidate items, without any manual design of meta-paths or meta-graphs.
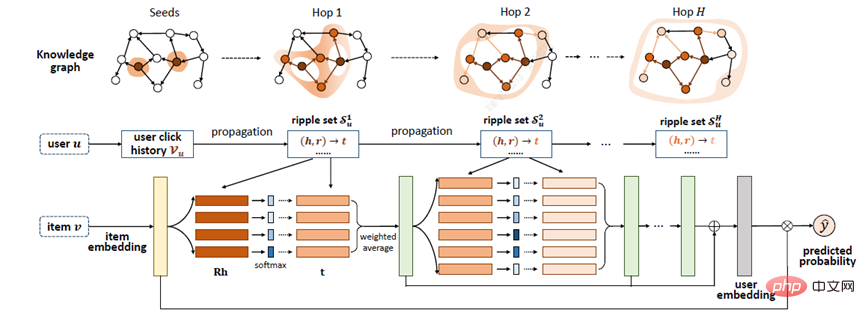
#RippleNet takes user U and item V as input, and outputs the predicted probability of user U clicking item V. For user U, taking its historical interest V_{u} as the seed, you can see in the figure that the initial starting point is two, and then continues to spread to the surroundings. Given itemV and each triple left(h_{i},r_{i},t_{i}right) in the 1-hop ripple set V_{u_{}^{1}} of user U, by comparing V Assign associated probabilities to nodes h_{i} and relationships r_{i} in triples.
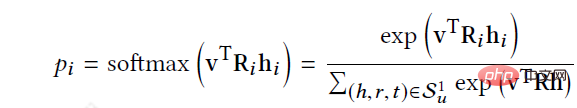
After obtaining the correlation probability, multiply the tail of the triplet in V_{u_{}^{1}} by the corresponding correlation probability for a weighted sum, and get User U's historical interest is a first-order response to V. The user's interest is transferred from V_{u} to o_{u}^{1}, and o_{u}^{2}, o_{u}^{3} can be calculated. ...o_{u}^{n}, and then the characteristics of U about item V can be calculated to fuse all his order responses.
4. Summary
In summary, we mainly focused on recommendations, introduced the detailed process of graph construction, and analyzed the difficulties and challenges involved. At the same time, it also summarizes a lot of important work and gives specific solutions, ideas and suggestions. Finally, the application including knowledge graph is introduced, especially the role and use of knowledge graph in the field of recommendation, including cold start, interpretability, and recall ranking.
Citation:
[1] Kim S, Oh S G. Extracting and Applying Evaluation Criteria for Ontology Quality Assessment[J]. Library Hi Tech, 2019.
[2]Protege: https://www.php.cn/link/9d405c24be657bbf7a5244815a908922
[3] Ding S, Shang J, Wang S, et al. ERNIE-DOC: The Retrospective Long-Document Modeling Transformer[J]. 2020.
[4]DocBert,[1] Adhikari A , Ram A , Tang R ,et al. DocBERT: BERT for Document Classification[J]. 2019.
[5]JanusGraph,https://www.php.cn /link/fc0de4e0396fff257ea362983c2dda5a
[6] Sang L, Xu M, Qian S, et al. Knowledge graph enhanced neural collaborative filtering with residual recurrent network[J]. Neurocomputing, 2021 , 454: 417-429.
[7] Du Y , Zhu X , Chen L , et al. MetaKG: Meta-learning on Knowledge Graph for Cold-start Recommendation[J]. arXiv e-prints, 2022.
[8] Chen Z , Wang X , Xie X , et al. Towards Explainable Conversational Recommendation[C]// Twenty-Ninth International Joint Conference on Artificial Intelligence and Seventeenth Pacific Rim International Conference on Artificial Intelligence {IJCAI-PRICAI-20. 2020.
[9] Wang X , He X , Cao Y , et al. KGAT: Knowledge Graph Attention Network for Recommendation[J]. ACM, 2019.
[10]Wang H, Zhang F, Wang J, et al. RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems[J]. ACM, 2018.
##
The above is the detailed content of Construction of automotive knowledge graph for recommendation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
1. Background Introduction First, let’s introduce the development history of Yunwen Technology. Yunwen Technology Company...2023 is the period when large models are prevalent. Many companies believe that the importance of graphs has been greatly reduced after large models, and the preset information systems studied previously are no longer important. However, with the promotion of RAG and the prevalence of data governance, we have found that more efficient data governance and high-quality data are important prerequisites for improving the effectiveness of privatized large models. Therefore, more and more companies are beginning to pay attention to knowledge construction related content. This also promotes the construction and processing of knowledge to a higher level, where there are many techniques and methods that can be explored. It can be seen that the emergence of a new technology does not necessarily defeat all old technologies. It is also possible that the new technology and the old technology will be integrated with each other.
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
