
 Technology peripherals
AI
DetectGPT: Zero-shot machine-generated text detection using probabilistic curvature
Technology peripherals
AI
DetectGPT: Zero-shot machine-generated text detection using probabilistic curvature
DetectGPT: Zero-shot machine-generated text detection using probabilistic curvature

The purpose of DetectGPT is to determine whether a piece of text was generated by a specific llm, such as GPT-3. To classify paragraph x, DetectGPT first generates a small perturbation on paragraph ~xi using a common pre-trained model (e.g., T5). DetectGPT then compares the log probability of the original sample x with each perturbed sample ~xi. If the average log ratio is high, the sample is likely from the source model.

ChatGPT is a hot topic. There is ongoing discussion about whether it is possible to detect that an article was generated by a large language model (LLM). DetectGPT defines a new curvature-based criterion for judging whether to generate from a given LLM. DetectGPT does not require training a separate classifier, collecting a dataset of real or generated passages, or explicitly watermarking the generated text. It uses only log probabilities computed by the model of interest and article random perturbations from another general-purpose pretrained language model (e.g., T5).
1. DetectGPT: Random permutations and assumptions

Identifies and utilizes the machine-generated channel x~pθ (left) located in the negative of logp (x) Trend in regions of curvature where nearby samples have lower model log probability on average. In contrast, human-written text x~preal(.) (right) tends not to occupy regions with significant negative log-probability curvature.
DetectGPT is based on the assumption that samples from the source model pθ usually lie in the negative curvature region of the pθ logarithmic probability function, which is different from human text. If we apply a small perturbation to a piece of text x~pθ, yielding ~x, the number of machine-generated samples log pθ(x) - log pθ(~x) should be relatively large compared to human-written text. Using this assumption, first consider a perturbation function q(.|x), which gives a distribution over ~x, a slightly modified version of x with similar meaning (usually consider a rough paragraph-length text x). For example, q(.|x) might be the result of simply asking a human to rewrite one of the sentences for x while preserving the meaning of x. Using the concept of perturbation function, the perturbation difference d (x; pθ, q) can be defined:
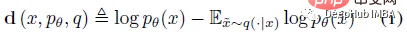


Sampling in semantic space ensures that all samples stay close to the data manifold, since the log probability is expected to always decrease if perturbation markers are added randomly. So the goal can be interpreted as approximately constraining the curvature on the data manifold.
4. Results display
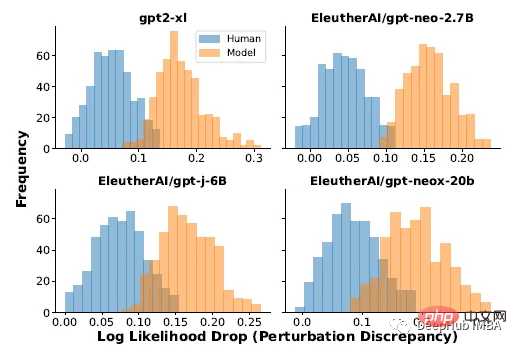
Zero-sample machine-generated text detection

Each experiment uses 150 to 500 examples for evaluation. Machine-generated text is generated by prompting the first 30 tokens of real text. Use AUROC) to evaluate performance.
It can be seen that DetectGPT maximizes the average detection accuracy of XSum stories (AUROC increased by 0.1) and SQuAD Wikipedia context (AUROC increased by 0.05).
For 14 of the 15 dataset and model combinations, DetectGPT provides the most accurate detection performance, with an average improvement in AUROC of 0.06.
Comparison with supervised detectors

# Supervised machine-generated text detection models trained on large datasets of real and generated text are The performance on text within the distribution (top row) is as good as DetectGPT, or even better. The zero-shot method is applied to new domains (bottom row) such as PubMed medical text and German news data in WMT16.
Evaluated on 200 samples from each dataset, the supervised detector performs similarly to DetectGPT on in-distribution data such as English news, but in the case of English scientific writing, its performance is significantly worse than zero sample approach, which completely fails in German writing.

DetectGPT’s average AUROC for GPT-3 is comparable to supervised models trained specifically for machine-generated text detection.
150 examples were extracted from PubMedQA, XSum and writingprompt data sets. Two pre-trained roberta-based detector models are compared with DetectGPT and the probabilistic threshold baseline. DetectGPT can provide detections that compete with more powerful supervised models.
Variation of machine-generated text detection

This part is to see if the detector can detect human-edited machine-generated text. Manual revision was simulated by replacing 5 word spans of the text with samples from T5–3B until r% of the text was replaced. DetectGPT maintains detection AUROC above 0.8 even though nearly a quarter of the text in the model sample has been replaced. DetectGPT shows the strongest detection performance across all revision levels.
The above is the detailed content of DetectGPT: Zero-shot machine-generated text detection using probabilistic curvature. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Image classification with few-shot learning using PyTorch
Apr 09, 2023 am 10:51 AM
Image classification with few-shot learning using PyTorch
Apr 09, 2023 am 10:51 AM
In recent years, deep learning-based models have performed well in tasks such as object detection and image recognition. On challenging image classification datasets like ImageNet, which contains 1,000 different object classifications, some models now exceed human levels. But these models rely on a supervised training process, they are significantly affected by the availability of labeled training data, and the classes the models are able to detect are limited to the classes they were trained on. Since there are not enough labeled images for all classes during training, these models may be less useful in real-world settings. And we want the model to be able to recognize classes it has not seen during training, since it is almost impossible to train on images of all potential objects. We will learn from a few samples
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Implementing OpenAI CLIP on custom datasets
Sep 14, 2023 am 11:57 AM
Implementing OpenAI CLIP on custom datasets
Sep 14, 2023 am 11:57 AM
In January 2021, OpenAI announced two new models: DALL-E and CLIP. Both models are multimodal models that connect text and images in some way. The full name of CLIP is Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training), which is a pre-training method based on contrasting text-image pairs. Why introduce CLIP? Because the currently popular StableDiffusion is not a single model, but consists of multiple models. One of the key components is the text encoder, which is used to encode the user's text input, and this text encoder is the text encoder CL in the CLIP model
 How to split a dataset correctly? Summary of three common methods
Apr 08, 2023 pm 06:51 PM
How to split a dataset correctly? Summary of three common methods
Apr 08, 2023 pm 06:51 PM
Decomposing the dataset into a training set helps us understand the model, which is important for how the model generalizes to new unseen data. A model may not generalize well to new unseen data if it is overfitted. Therefore good predictions cannot be made. Having an appropriate validation strategy is the first step to successfully creating good predictions and using the business value of AI models. This article has compiled some common data splitting strategies. A simple train and test split divides the data set into training and validation parts, with 80% training and 20% validation. You can do this using Scikit's random sampling. First, the random seed needs to be fixed, otherwise the same data split cannot be compared and the results cannot be reproduced during debugging. If the data set
 Google AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features
Feb 26, 2024 am 09:58 AM
Google AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features
Feb 26, 2024 am 09:58 AM
After the AI video model Sora became popular, major companies such as Meta and Google have stepped aside to do research and catch up with OpenAI. Recently, researchers from the Google team proposed a universal video encoder - VideoPrism. It can handle various video understanding tasks through a single frozen model. Image paper address: https://arxiv.org/pdf/2402.13217.pdf For example, VideoPrism can classify and locate the person blowing candles in the video below. Image video-text retrieval, based on the text content, the corresponding content in the video can be retrieved. For another example, describe the video below - a little girl is playing with building blocks. QA questions and answers are also available.
 PyTorch parallel training DistributedDataParallel complete code example
Apr 10, 2023 pm 08:51 PM
PyTorch parallel training DistributedDataParallel complete code example
Apr 10, 2023 pm 08:51 PM
The problem of training large deep neural networks (DNN) using large datasets is a major challenge in the field of deep learning. As DNN and dataset sizes increase, so do the computational and memory requirements for training these models. This makes it difficult or even impossible to train these models on a single machine with limited computing resources. Some of the major challenges in training large DNNs using large datasets include: Long training time: The training process can take weeks or even months to complete, depending on the complexity of the model and the size of the dataset. Memory limitations: Large DNNs may require large amounts of memory to store all model parameters, gradients, and intermediate activations during training. This can cause out of memory errors and limit what can be trained on a single machine.
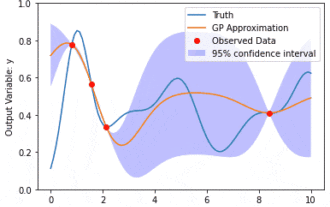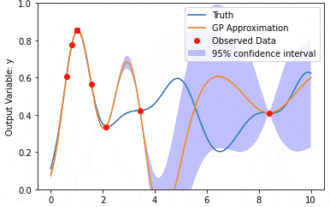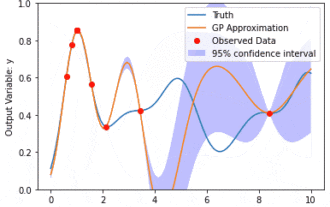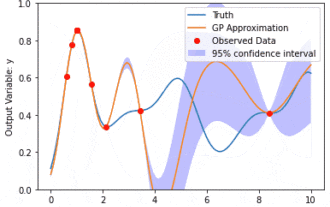 Data modeling using Kernel Model Gaussian Processes (KMGPs)
Jan 30, 2024 am 11:15 AM
Data modeling using Kernel Model Gaussian Processes (KMGPs)
Jan 30, 2024 am 11:15 AM
Kernel Model Gaussian Processes (KMGPs) are sophisticated tools for handling the complexity of various data sets. It extends the concept of traditional Gaussian processes through kernel functions. This article will discuss in detail the theoretical basis, practical applications and challenges of KMGPs. The kernel model Gaussian process is an extension of the traditional Gaussian process and is used in machine learning and statistics. Before understanding kmgp, you need to master the basic knowledge of Gaussian process, and then understand the role of the kernel model. Gaussian processes (GPs) are a set of random variables, a finite number of variables jointly distributed with a Gaussian distribution, and are used to define function probability distributions. Gaussian processes are commonly used in regression and classification tasks in machine learning and can be used to fit the probability distribution of data. An important feature of Gaussian processes is their ability to provide uncertainty estimates and predictions
 Calculating the carbon cost of artificial intelligence
Apr 12, 2023 am 08:52 AM
Calculating the carbon cost of artificial intelligence
Apr 12, 2023 am 08:52 AM
If you are looking for interesting topics, Artificial Intelligence (AI) will not disappoint you. Artificial intelligence encompasses a set of powerful, mind-bending statistical algorithms that can play chess, decipher sloppy handwriting, understand speech, classify satellite images, and more. The availability of giant data sets for training machine learning models has been one of the key factors in the success of artificial intelligence. But all this computational work isn't free. Some AI experts are increasingly concerned about the environmental impacts associated with building new algorithms, a debate that has spurred new ideas on how to make machines learn more efficiently to reduce AI's carbon footprint. Back on Earth To get into the details, we first need to consider the thousands of data centers (scattered around the world) that handle our computing requests 24/7.
