
 Backend Development
Python Tutorial
Python face recognition system with an offline recognition rate of up to 99%, open source~
Backend Development
Python Tutorial
Python face recognition system with an offline recognition rate of up to 99%, open source~
Python face recognition system with an offline recognition rate of up to 99%, open source~


In the past, face recognition mainly included technologies and systems such as face image collection, face recognition preprocessing, identity confirmation, and identity search. Now face recognition has slowly extended to driver detection, pedestrian tracking, and even dynamic object tracking in ADAS.
It can be seen that the face recognition system has developed from simple image processing to real-time video processing. Moreover, the algorithm has changed from traditional statistical methods such as Adaboots and PCA to deep learning methods such as CNN and RCNN and their modifications. Now a considerable number of people have begun to study 3D face recognition, and this kind of project is currently supported by academia, industry and the country.
First, let’s take a look at the current research status. As can be seen from the above development trends, the current main research direction is to use deep learning methods to solve video face recognition.
Main researchers:
are as follows: Professor Shan Shiguang from the Institute of Computing Technology, Chinese Academy of Sciences, Professor Li Ziqing from the Institute of Biometrics, Chinese Academy of Sciences, Professor Su Guangda from Tsinghua University, and Professor Tang Xiaoou from the Chinese University of Hong Kong , Ross B. Girshick, etc.
Main open source projects:
SeetaFace face recognition engine. The engine was developed by the face recognition research group led by researcher Shan Shiguang of the Institute of Computing Technology, Chinese Academy of Sciences. The code is implemented based on C and does not rely on any third-party library functions. The open source license is BSD-2 and can be used free of charge by academia and industry.
Main software API/SDK:
- face. Face.com is a cloud service platform that provides free face detection, face recognition, face attribute analysis and other services. Face is a new face technology cloud platform owned by Beijing Megvii Technology Co., Ltd. In the dark horse competition, Face won the annual championship and has received Lenovo Star investment.
- skybiometry. It mainly includes face detection, face recognition, and face grouping.
Main face recognition image database:
The better face image databases currently disclosed include LFW (Labelled Faces in the Wild) and YFW (Youtube Faces in the Wild) ). The current experimental data set is basically derived from LFW, and the accuracy of current image face recognition has reached 99%. Basically, the existing image database has been exhausted. The following is a summary of the existing face image database:

There are more and more companies doing face recognition in China, and its applications are also very widespread. Among them, Hanwang Technology has the highest market share. The research directions and current status of the main companies are as follows:
- Hanwang Technology: Hanwang Technology mainly does face recognition authentication, which is mainly used in access control systems, attendance systems, etc.
- iFlytek: iFlytek, with the support of Professor Tang Xiaoou’s team at the Chinese University of Hong Kong, has developed a face recognition technology based on Gaussian process – Gussian face. The recognition rate of this technology on LFW is 98.52%. , the current recognition rate of the company's DEEPID2 on LFW has reached 99.4%.
- Sichuan University Zhisheng: The current research highlight of the company is 3D face recognition, and it has expanded to the industrialization of 3D full-face cameras and so on.
- SenseTime: It is mainly a company dedicated to leading breakthroughs in the core "deep learning" technology of artificial intelligence and building industry solutions for artificial intelligence and big data analysis. It is currently engaged in face recognition, text recognition, and human body recognition. , vehicle recognition, object recognition, image processing and other directions have strong competitiveness. In face recognition, there are 106 face key points for recognition.
The process of face recognition
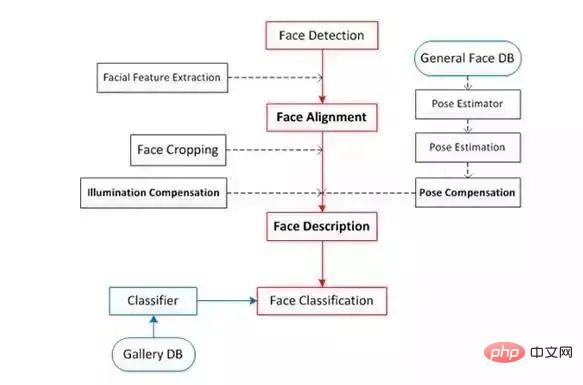
Face recognition is mainly divided into four major parts: face detection (face detection), face calibration (face alignment), and face confirmation ( face verification), face identification (face identification).
Face positioning (face detection):
Detect the face in the image and frame the result in a rectangular frame. In openCV, there is a Harr classifier that can be used directly.
Face alignment:
Correct the posture of the detected face to make the face as "positive" as possible. Through correction, the accuracy of face recognition can be improved. Accuracy. Correction methods include 2D correction and 3D correction. The 3D correction method can enable better recognition of side faces.
When performing face correction, there is a step of detecting the location of feature points. These feature point locations are mainly locations such as the left side of the nose, the underside of the nostrils, the pupil position, the underside of the upper lip, etc. After knowing the positions of these feature points, perform position-driven deformation, and the face can be "corrected". As shown in the figure below:
Here is a technology developed by MSRA in 2014: Joint Cascade Face Detection and Alignment (ECCV14). This article directly does both detection and alignment in 30ms.
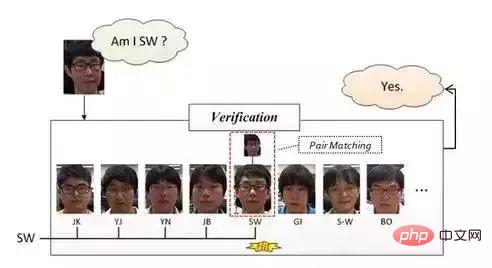
Face verification:
Face verification, face verification is based on pair matching, so the answer it gets is "yes" or "no". In the specific operation, a test image is given, and then pair matching is performed one by one. If the matching is successful, it means that the test image and the matched face are the faces of the same person.
This method is (should) generally used in small office face-scanning punch-in systems. The specific operation method is roughly the following process: offline enter the face photos of employees one by one (the person entered by an employee There is usually more than one face). After the camera captures the image when the employee swipes the face to check in, it first performs face detection through the above-mentioned methods, then performs face correction, and then performs face verification. Once the match result is "Yes" ", indicating that the person who scanned the face belongs to this office, and the face verification is completed at this step.
When entering an employee's face offline, we can match the face with the person's name, so that once the face verification is successful, we can know who the person is.
The advantage of the system mentioned above is that it has low development costs and is suitable for small offices. The disadvantage is that it cannot be blocked during capture, and it also requires the face posture to be relatively straight (we own this system, but Have not experienced it). The following figure gives a schematic explanation:
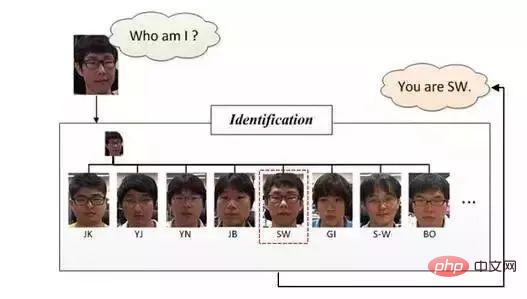
Face identification/recognition:
Face identification or Face recognition, face recognition is as follows As shown in the figure, what it wants to answer is "Who am I?". Compared with the pair matching used in face verification, it uses more classification methods in the recognition stage. It actually classifies images (faces) after performing the previous two steps, namely face detection and face correction.
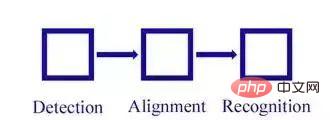
According to the introduction of the above four concepts, we can understand that face recognition mainly includes three large, independent modules:
We split the above steps in detail and get the following process diagram:
Face recognition classification
Nowadays, with the development of face recognition technology, face recognition technology is mainly divided into three categories: first, image-based recognition methods, second, video-based recognition methods, and third, three-dimensional face recognition methods.
Image-based recognition method:
This process is a static image recognition process, which mainly uses image processing. The main algorithms include PCA, EP, kernel method, Bayesian Framwork, SVM, HMM, Adaboot and other algorithms. But in 2014, face recognition achieved a major breakthrough using Deep learning technology, represented by 97.25% of deepface and 97.27% of face. However, the training set of deep face is 4 million sets. At the same time, Gussian by Tang Xiaoou of the Chinese University of Hong Kong The training set of face is 2w.
Real-time recognition method based on video:
This process can be seen in the tracking process of face recognition, which not only requires finding the position and size of the face in the video, but also needs to determine the inter-frame Correspondence between different faces.
DeepFace
Reference papers (information):
1. DeepFace paper. DeepFace: Closing the Gap to Human-level Performance in Face Verificaion
2. Convolutional neural network understanding blog. http://blog.csdn.net/zouxy09/article/details/8781543
3. Derivation blog of convolutional neural network. http://blog.csdn.net/zouxy09/article/details/9993371/
4. Note on convolution Neural Network.
5. Neural Network for Recognition of Handwritten Digits
6. DeepFace blog post: http://blog.csdn.net/Hao_Zhang_Vision/article/details/52831399?locationNum=2&fps=1
DeepFace was proposed by FaceBook, followed by DeepID and FaceNet. . Moreover, DeepFace can be seen in DeepID and FaceNet, so DeepFace can be said to be the foundation of CNN in face recognition. At present, deep learning has also achieved very good results in face recognition. So here we start learning from DeepFace.
During the learning process of DeepFace, not only the methods used by DeepFace will be introduced, but also other main algorithms currently used in this step will be introduced to give a simple and comprehensive description of the existing image face recognition technology.
Basic framework of DeepFace
1. Basic process of face recognition
face detection -> face alignment -> face verification -> face identification
2. Face detection
2.1 Existing technology:
haar classifier:
Face detection (detection) has already had a haar classifier that can be used directly in opencv, based on the Viola-Jones algorithm.
Adaboost algorithm (cascade classifier):
1. Reference paper: Robust Real-Time face detection.
2. Reference Chinese blog: http://blog.csdn.net/cyh_24/article/details/39755661
3. Blog: http://blog.sina.com.cn /s/blog_7769660f01019ep0.html
2.2 Method used in the article
This article uses a face detection method based on detection points (fiducial Point Detector).
- First select 6 reference points, 2 eye centers, 1 nose point, and 3 points on the mouth.
- Use SVR to learn the reference point through LBP features.
The effect is as follows:

3. Face alignment (face alignment)
2D alignment:
- Perform two-dimensional cropping of the detected image, scale, rotate and translate the image into six anchor locations. Cut out the face part.
3D alignment:
- Find a 3D model and use this 3D model to crop the 2D face into a 3D face. 67 base points, then Delaunay triangulation, adding triangles at the contour to avoid discontinuities.
- Convert the triangulated face into a 3D shape
- The triangulated face becomes a deep 3D triangle mesh
- Deflect the triangle mesh so that The front of the face is facing forward
- The final face placed straight
The effect is as follows:
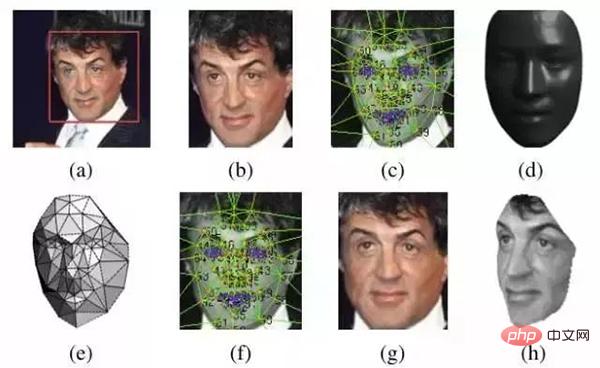
The above 2D alignment corresponds (b) Picture, 3D alignment corresponds to (c) ~ (h).
4 Face verification
4.1 Existing technology
LBP && joint Bayesian:
Through the two high-dimensional LBP and Joint Bayesian combination of methods.
- Paper: Bayesian Face Revisited: A Joint Formulation
DeepID Series:
Fuse seven joint Bayesian models using SVM, accuracy Reaching 99.15%
- Thesis: Deep Learning Face Representation by Joint Identification-Verification
4.2 Method in the article
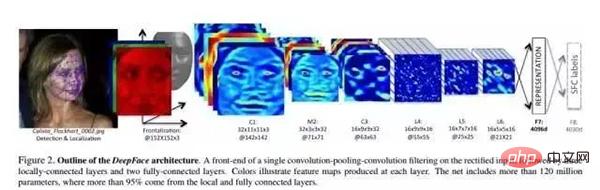
In the paper, a deep neural network (DNN) is trained through a multi-category face recognition task. The network structure is shown in the figure above.
Structural parameters:
After 3D alignment, the images formed are all 152×152 images, which are input into the above network structure. The parameters of the structure are as follows:
- Conv: 32 convolution kernels of 11×11×3
- max-pooling: 3×3, stride=2
- Conv: 16 convolution kernels of 9×9
- Local-Conv: 16 9×9 convolution kernels, Local means that the parameters of the convolution kernel are not shared
- Local-Conv: 16 7×7 convolution kernels , parameters are not shared
- Local-Conv: 16 5×5 convolution kernels, parameters are not shared
- Fully-connected: 4096 dimensions
- Softmax: 4030 dimensions
Extract low-level features:
The process is as follows:
- Pre-processing stage: input the 3-channel face, perform 3D correction, and then Normalized to 152*152 pixel size - 152*152*3.
- Through the convolution layer C1: C1 contains 32 11*11*3 filters (ie, convolution kernel), resulting in 32 Feature map - 32*142*142*3.
- Through the max-polling layer M2: the sliding window size of M2 is 3*3, the sliding step size is 2, and the three channels are polled independently.
- Through another convolution layer C3: C3 contains 16 3-dimensional convolution kernels of 9*9*16.
The above 3-layer network is to extract low-level features, such as simple edge features and texture features. The Max-polling layer makes the convolutional network more robust to local transformations. If the input is a corrected face, it makes the network more robust to small labeling errors.
However, such a polling layer will cause the network to lose some information on the detailed structure of the face and the precise location of tiny textures. Therefore, the paper only adds the Max-polling layer after the first convolutional layer. These previous layers are called front-end adaptive preprocessing levels. However, for many calculations, where this is necessary, these layers have very few parameters. They simply expand the input image into a simple local feature set.
Subsequent layers:
L4, L5, and L6 are all locally connected layers. Just like the convolutional layer uses filters, a different set of layers are trained and learned at each position of the feature image. filter. Since different regions have different statistical properties after correction, the assumption of spatial stability of the convolutional network cannot be established.
For example, compared to the area between the nose and mouth, the area between the eyes and eyebrows exhibits a very different appearance and is highly differentiated. In other words, by utilizing the input rectified image, the structure of the DNN is customized.
The use of local connection layers does not affect the computational burden during feature extraction, but it affects the number of training parameters. Simply because there is such a large library of labeled faces, we can afford three large locally connected layers. The output unit of the local connection layer is affected by a large input patch, and the use (parameters) of the local connection layer can be adjusted accordingly (no weights are shared)
For example, the output of the L6 layer is affected by a 74* The influence of the 74*3 input patch, in the corrected face, it is difficult to have any statistical parameter sharing between such large patches.
Top layer:
Finally, the top two layers of the network (F7, F8) are fully connected: every output unit is connected to all inputs. These two layers can capture the correlation between features in distant areas in the face image. For example, the correlation between the position and shape of the eyes and the position and shape of the mouth (this part also contains information) can be obtained from these two layers. The output of the first fully connected layer F7 is our original facial feature expression vector.
In terms of feature expression, this feature vector is very different from the traditional LBP-based feature description. Traditional methods usually use local feature descriptions (compute histograms) and serve as input to the classifier.
The output of the last fully connected layer F8 enters a K-way softmax (K is the number of categories), which can generate a probability distribution of category labels. Let Ok represent the k-th output of an input image after passing through the network, that is, the probability of the output class label k can be expressed by the following formula:
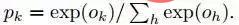
The goal of training is to maximize the correct output Probability of class (id of face). This is achieved by minimizing the cross-entropy loss for each training sample. Let k represent the label of the correct category of the given input, then the cross-entropy loss is:
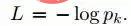
By calculating the gradient of the cross-entropy loss L on the parameters and using the stochastic gradient reduction method to minimize cross entropy loss.
The gradient is calculated by standard backpropagation of the error. Interestingly enough, the features produced by this network are very sparse. More than 75% of top-level feature elements are 0. This is mainly due to the use of the ReLU activation function. This soft threshold nonlinear function is used in all convolutional layers, locally connected layers and fully connected layers (except the last layer F8), resulting in highly nonlinear and sparse features after the overall cascade.
Sparsity is also related to the use of dropout regularization, which sets random feature elements to 0 during training. We only used dropout in the F7 fully connected layer. Due to the large training set, we did not find significant overfitting during the training process.
Given an image I, its feature expression G(I) is calculated through the feedforward network. The feedforward network of each L layer can be regarded as a series of functions:

Normalization:
At the last level, we normalize the elements of the feature to 0 to 1 to reduce the sensitivity of the feature to lighting changes. Each element in the feature vector is divided by the corresponding maximum value in the training set. Then perform L2 normalization. Since we use the ReLU activation function, our system is less invariant to the scale of the image.
For the output 4096-d vector:
- First normalize each dimension, that is, for each dimension in the result vector, divide the dimension by the entire The maximum value on the training set.
- Each vector is L2 normalized.
2. Verification
2.1 Chi-square distance
In this system, the normalized DeepFace feature vector is consistent with the traditional histogram-based features (such as LBP) have the following similarities:
- All values are negative
- Very sparse
- The values of the feature elements are all between the interval [0, 1]
The chi-square distance calculation formula is as follows:
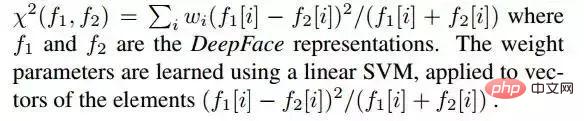
2.2 Siamese network
The article also mentioned end-to-end metric learning Method, once learning (training) is completed, the face recognition network (up to F7) is reused on the two input pictures, and the two obtained feature vectors are directly used to predict whether the two input pictures belong to the same person. This is divided into the following steps:
a. Calculate the absolute difference between two features;
b, a fully connected layer, mapped to a single logical unit (output same/different) .
3. Experimental evaluation
3.1 Data set
- Social Face Classification Dataset(SFC): 4.4M faces/4030 people
- LFW: 13323 faces/5749 people
- restricted: only yes/no Tag
- unrestricted: Other training pairs can also get
- unsupervised: Not trained on LFW
- Youtube Face(YTF): 3425videos/1595 people
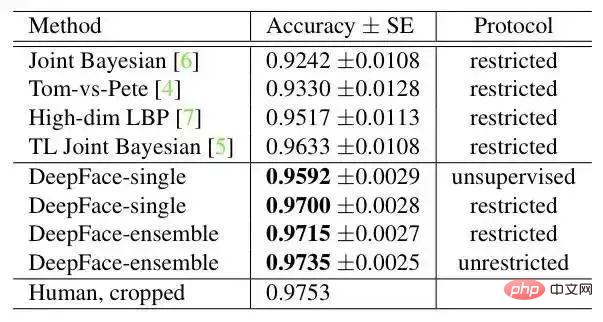
result on LFW:
result on YTF:
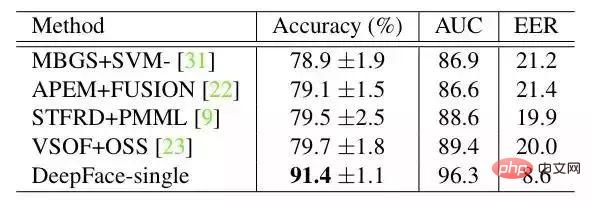
DeepFace and the maximum of the following methods The difference is that DeepFace uses an alignment method before training the neural network. The paper believes that the reason why neural networks can work is that once the face is aligned, the features of the face area are fixed on certain pixels. At this time, the convolutional neural network can be used to learn the features.
The model of this article uses the latest face recognition method based on deep learning in the C toolbox dlib. Based on the benchmark level of the outdoor face data test library Labeled Faces in the Wild, it reaches an accuracy of 99.38%. .
More algorithms
http://www.gycc.com/trends/face recognition/overview/
dlib: http://dlib.net/Data testing library Labeled Faces in the Wild: http://vis-www.cs.umass.edu/lfw/
The model provides a simple face_recognition command line tool for Users can directly use the picture folder to perform face recognition operations through commands.
Capture facial features in pictures
Capture all faces in one picture
Find and process the features of faces in pictures
Find the position and outline of each person's eyes, nose, mouth and chin.
import face_recognition
image = face_recognition.load_image_file("your_file.jpg")
face_locations = face_recognition.face_locations(image)
Capture facial features It has very important uses. Of course, it can also be used for digital make-up of pictures (such as Meitu Xiu Xiu)
digital make-up: https://github.com/ageitgey/face_recognition /blob/master/examples/digital_makeup.py
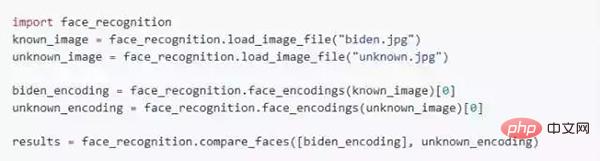
Recognize faces in pictures
Recognize who appears in photos
Install Step
This method supports Python3/python2. We have only tested it on macOS and Linux. We don’t know whether it is applicable to Windows.
Install this module using pip3 of pypi (or pip2 of Python 2)
Important note: There may be problems when compiling dlib, you can install it from source (instead of pip) dlib to fix the error, please see the installation manual How to install dlib from source
https://gist.github.com/ageitgey/629d75c1baac34dfa5ca2a1928a7aeaf
Install dlib manually and run pip3 install face_recognition to complete the installation.
How to use command line interface
When you install face_recognition, you can get a simple command line program called face_recognition, which can help you recognize a photo or a photo folder of all faces.
First of all, you need to provide a folder containing a photo, and you already know who the person in the photo is. Each person must have a photo file, and the file name needs to be named after that person’s name. ;
Then you need to prepare another folder containing the photos of faces you want to recognize;
Then you only need to run the face_recognition command, and the program can pass the files of known faces Folder identifies who the person in the unknown face photo is;

# One line is output for each face. The data is the file name plus the recognized name of the person, separated by commas. Separate.
If you just want to know the name of the person in each photo but not the file name, you can do the following:

Python module
You can complete the face recognition operation by introducing face_recognition:
API documentation: https://face-recognition.readthedocs.io.
Automatically recognize all faces in pictures
Please refer to this example: https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py
Recognize faces in pictures and tell names
Please refer to this example: https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.py
Python code case
All examples are here.
https://github.com/ageitgey/face_recognition/tree/master/examples
·Find faces in a photograph
https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py · 识别照片中的面部特征Identify specific facial features in a photograph https://github.com/ageitgey/face_recognition/blob/master/examples/find_facial_features_in_picture.py · 使用数字美颜Apply (horribly ugly) digital make-up https://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py ·基于已知人名找到并识别出照片中的未知人脸Find and recognize unknown faces in a photograph based on photographs of known people https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.pypython人脸
Okay, that’s it for today’s sharing~
The above is the detailed content of Python face recognition system with an offline recognition rate of up to 99%, open source~. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Do mysql need to pay
Apr 08, 2025 pm 05:36 PM
Do mysql need to pay
Apr 08, 2025 pm 05:36 PM
MySQL has a free community version and a paid enterprise version. The community version can be used and modified for free, but the support is limited and is suitable for applications with low stability requirements and strong technical capabilities. The Enterprise Edition provides comprehensive commercial support for applications that require a stable, reliable, high-performance database and willing to pay for support. Factors considered when choosing a version include application criticality, budgeting, and technical skills. There is no perfect option, only the most suitable option, and you need to choose carefully according to the specific situation.
 HadiDB: A lightweight, horizontally scalable database in Python
Apr 08, 2025 pm 06:12 PM
HadiDB: A lightweight, horizontally scalable database in Python
Apr 08, 2025 pm 06:12 PM
HadiDB: A lightweight, high-level scalable Python database HadiDB (hadidb) is a lightweight database written in Python, with a high level of scalability. Install HadiDB using pip installation: pipinstallhadidb User Management Create user: createuser() method to create a new user. The authentication() method authenticates the user's identity. fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
It is impossible to view MongoDB password directly through Navicat because it is stored as hash values. How to retrieve lost passwords: 1. Reset passwords; 2. Check configuration files (may contain hash values); 3. Check codes (may hardcode passwords).
 Does mysql need the internet
Apr 08, 2025 pm 02:18 PM
Does mysql need the internet
Apr 08, 2025 pm 02:18 PM
MySQL can run without network connections for basic data storage and management. However, network connection is required for interaction with other systems, remote access, or using advanced features such as replication and clustering. Additionally, security measures (such as firewalls), performance optimization (choose the right network connection), and data backup are critical to connecting to the Internet.
 How to solve mysql cannot connect to local host
Apr 08, 2025 pm 02:24 PM
How to solve mysql cannot connect to local host
Apr 08, 2025 pm 02:24 PM
The MySQL connection may be due to the following reasons: MySQL service is not started, the firewall intercepts the connection, the port number is incorrect, the user name or password is incorrect, the listening address in my.cnf is improperly configured, etc. The troubleshooting steps include: 1. Check whether the MySQL service is running; 2. Adjust the firewall settings to allow MySQL to listen to port 3306; 3. Confirm that the port number is consistent with the actual port number; 4. Check whether the user name and password are correct; 5. Make sure the bind-address settings in my.cnf are correct.
 Can mysql workbench connect to mariadb
Apr 08, 2025 pm 02:33 PM
Can mysql workbench connect to mariadb
Apr 08, 2025 pm 02:33 PM
MySQL Workbench can connect to MariaDB, provided that the configuration is correct. First select "MariaDB" as the connector type. In the connection configuration, set HOST, PORT, USER, PASSWORD, and DATABASE correctly. When testing the connection, check that the MariaDB service is started, whether the username and password are correct, whether the port number is correct, whether the firewall allows connections, and whether the database exists. In advanced usage, use connection pooling technology to optimize performance. Common errors include insufficient permissions, network connection problems, etc. When debugging errors, carefully analyze error information and use debugging tools. Optimizing network configuration can improve performance
 How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
MySQL database performance optimization guide In resource-intensive applications, MySQL database plays a crucial role and is responsible for managing massive transactions. However, as the scale of application expands, database performance bottlenecks often become a constraint. This article will explore a series of effective MySQL performance optimization strategies to ensure that your application remains efficient and responsive under high loads. We will combine actual cases to explain in-depth key technologies such as indexing, query optimization, database design and caching. 1. Database architecture design and optimized database architecture is the cornerstone of MySQL performance optimization. Here are some core principles: Selecting the right data type and selecting the smallest data type that meets the needs can not only save storage space, but also improve data processing speed.
 How to use AWS Glue crawler with Amazon Athena
Apr 09, 2025 pm 03:09 PM
How to use AWS Glue crawler with Amazon Athena
Apr 09, 2025 pm 03:09 PM
As a data professional, you need to process large amounts of data from various sources. This can pose challenges to data management and analysis. Fortunately, two AWS services can help: AWS Glue and Amazon Athena.
