

Ten alternative data processing techniques for Pandas

The techniques compiled in this article are different from the common techniques compiled in 10 Pandas before. You may not use it often, but sometimes when you encounter some very difficult problems, these techniques can help you quickly Solve some uncommon problems.

1. Categorical type
By default, columns with a limited number of options will be assigned the object type. But it's not an efficient choice in terms of memory. We can index these columns and use only references to the objects and not the actual values. Pandas provides a Dtype called Categorical to solve this problem.
For example, it consists of a large data set with image paths. Each row has three columns: anchor, positive, and negative.
If you use Categorical for categorical columns, you can significantly reduce memory usage.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
The value of the filename column will be copied frequently. Therefore, memory usage can be greatly reduced by using Categorical.
Let's read the target data set and see the difference in memory:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
The difference is very large, and the difference grows non-linearly as the number of repetitions increases.
2. Row-column conversion
The problem of row-column conversion is often encountered in sql. Pandas sometimes also needs it. Let's take a look at the data set from the Kaggle competition. census_start .csv file:
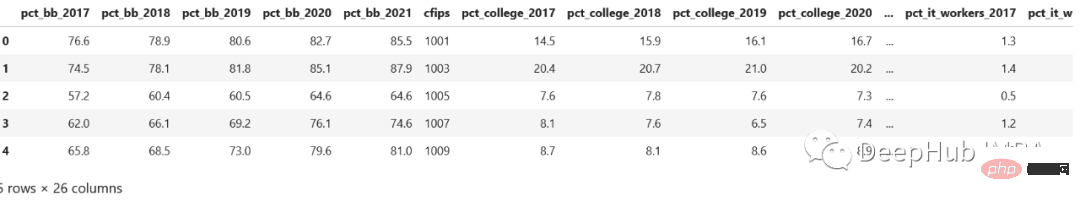
As you can see, these are saved by year. If there is a column year and pct_bb, and each row has a corresponding value, it will be better A lot, right.
1 2 3 4 5 6 7 |
|
Look at the result, is this much better:

As we introduced last time, it is best not to use this method because it iterates through each row and calls the specified method. But if we have no other choice, is there any way to increase the speed? You can use packages such as swifter or pandarallew to parallelize the process. Swifter
1
2
3
4
5
6
7
8
9
10
11
import pandas as pd
import swifter
def target_function(row):
return row * 10
def traditional_way(data):
data['out'] = data['in'].apply(target_function)
def swifter_way(data):
data['out'] = data['in'].swifter.apply(target_function)
Copy after login
Pandaralllel 1 2 3 4 5 6 7 8 9 10 11 |
|
1
2
3
4
5
6
7
8
9
10
11
12
import pandas as pd
from pandarallel import pandarallel
def target_function(row):
return row * 10
def traditional_way(data):
data['out'] = data['in'].apply(target_function)
def pandarallel_way(data):
pandarallel.initialize()
data['out'] = data['in'].parallel_apply(target_function)
Copy after login
Through multi-threading, the speed of calculation can be improved. Of course, if there is a cluster, it is best to use dask or pyspark4. Null value, int, Int64The standard integer data type does not support null value, so it will be automatically converted to a floating point number. So if your data requires null values in integer fields, consider using the Int64 data type as it will use pandas.NA to represent null values. 5. Csv, compression or parquet? Choose parquet as much as possible. Parquet will retain the data type, so there is no need to specify dtypes when reading data. Parquet files are compressed using snappy by default, so they take up little disk space. Below you can see a few comparisons1 2 3 4 5 6 7 8 9 10 11 12 |
|
1 2 3 4 5 6 7 |
|
1 2 3 4 5 |
|

1 2 3 4 |
|

If you often encounter complex semi-structured data and need to separate individual columns from it, you can use this method:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|

9、读写剪贴板
这个技巧有人一次也用不到,但是有人可能就是需要,比如:在分析中包含PDF文件中的表格时。通常的方法是复制数据,粘贴到Excel中,导出到csv文件中,然后导入Pandas。但是,这里有一个更简单的解决方案:pd.read_clipboard()。我们所需要做的就是复制所需的数据并执行一个方法。
有读就可以写,所以还可以使用to_clipboard()方法导出到剪贴板。
但是要记住,这里的剪贴板是你运行python/jupyter主机的剪切板,并不可能跨主机粘贴,一定不要搞混了。
10、数组列分成多列
假设我们有这样一个数据集,这是一个相当典型的情况:
1 2 3 4 5 6 7 |
|

我们想将category分成多列显示,例如下面的

先看看最慢的apply:
1 2 3 4 5 6 7 8 9 |
|
sklearn的MultiLabelBinarizer
1 2 3 4 5 6 7 |
|
是不是快了很多,我们还可以使用一般的向量化操作对其求和:
1 2 3 4 5 6 7 |
|

使用第一个方法(在StackOverflow上的回答中非常常见)会给出一个非常慢的结果。而其他两个优化的方法的时间是非常快速的。
总结
我希望每个人都能从这些技巧中学到一些新的东西。重要的是要记住尽可能使用向量化操作而不是apply()。此外,除了csv之外,还有其他有趣的存储数据集的方法。不要忘记使用分类数据类型,它可以节省大量内存。感谢阅读!
The above is the detailed content of Ten alternative data processing techniques for Pandas. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
52

 Win11 Tips Sharing: Skip Microsoft Account Login with One Trick
Mar 27, 2024 pm 02:57 PM
Win11 Tips Sharing: Skip Microsoft Account Login with One Trick
Mar 27, 2024 pm 02:57 PM
Win11 Tips Sharing: One trick to skip Microsoft account login Windows 11 is the latest operating system launched by Microsoft, with a new design style and many practical functions. However, for some users, having to log in to their Microsoft account every time they boot up the system can be a bit annoying. If you are one of them, you might as well try the following tips, which will allow you to skip logging in with a Microsoft account and enter the desktop interface directly. First, we need to create a local account in the system to log in instead of a Microsoft account. The advantage of doing this is
 A must-have for veterans: Tips and precautions for * and & in C language
Apr 04, 2024 am 08:21 AM
A must-have for veterans: Tips and precautions for * and & in C language
Apr 04, 2024 am 08:21 AM
In C language, it represents a pointer, which stores the address of other variables; & represents the address operator, which returns the memory address of a variable. Tips for using pointers include defining pointers, dereferencing pointers, and ensuring that pointers point to valid addresses; tips for using address operators & include obtaining variable addresses, and returning the address of the first element of the array when obtaining the address of an array element. A practical example demonstrating the use of pointer and address operators to reverse a string.
 What are the tips for novices to create forms?
Mar 21, 2024 am 09:11 AM
What are the tips for novices to create forms?
Mar 21, 2024 am 09:11 AM
We often create and edit tables in excel, but as a novice who has just come into contact with the software, how to use excel to create tables is not as easy as it is for us. Below, we will conduct some drills on some steps of table creation that novices, that is, beginners, need to master. We hope it will be helpful to those in need. A sample form for beginners is shown below: Let’s see how to complete it! 1. There are two methods to create a new excel document. You can right-click the mouse on a blank location on the [Desktop] - [New] - [xls] file. You can also [Start]-[All Programs]-[Microsoft Office]-[Microsoft Excel 20**] 2. Double-click our new ex
 VSCode Getting Started Guide: A must-read for beginners to quickly master usage skills!
Mar 26, 2024 am 08:21 AM
VSCode Getting Started Guide: A must-read for beginners to quickly master usage skills!
Mar 26, 2024 am 08:21 AM
VSCode (Visual Studio Code) is an open source code editor developed by Microsoft. It has powerful functions and rich plug-in support, making it one of the preferred tools for developers. This article will provide an introductory guide for beginners to help them quickly master the skills of using VSCode. In this article, we will introduce how to install VSCode, basic editing operations, shortcut keys, plug-in installation, etc., and provide readers with specific code examples. 1. Install VSCode first, we need
 How does Golang improve data processing efficiency?
May 08, 2024 pm 06:03 PM
How does Golang improve data processing efficiency?
May 08, 2024 pm 06:03 PM
Golang improves data processing efficiency through concurrency, efficient memory management, native data structures and rich third-party libraries. Specific advantages include: Parallel processing: Coroutines support the execution of multiple tasks at the same time. Efficient memory management: The garbage collection mechanism automatically manages memory. Efficient data structures: Data structures such as slices, maps, and channels quickly access and process data. Third-party libraries: covering various data processing libraries such as fasthttp and x/text.
 PHP programming skills: How to jump to the web page within 3 seconds
Mar 24, 2024 am 09:18 AM
PHP programming skills: How to jump to the web page within 3 seconds
Mar 24, 2024 am 09:18 AM
Title: PHP Programming Tips: How to Jump to a Web Page within 3 Seconds In web development, we often encounter situations where we need to automatically jump to another page within a certain period of time. This article will introduce how to use PHP to implement programming techniques to jump to a page within 3 seconds, and provide specific code examples. First of all, the basic principle of page jump is realized through the Location field in the HTTP response header. By setting this field, the browser can automatically jump to the specified page. Below is a simple example demonstrating how to use P
 Win11 Tricks Revealed: How to Bypass Microsoft Account Login
Mar 27, 2024 pm 07:57 PM
Win11 Tricks Revealed: How to Bypass Microsoft Account Login
Mar 27, 2024 pm 07:57 PM
Win11 tricks revealed: How to bypass Microsoft account login Recently, Microsoft launched a new operating system Windows11, which has attracted widespread attention. Compared with previous versions, Windows 11 has made many new adjustments in terms of interface design and functional improvements, but it has also caused some controversy. The most eye-catching point is that it forces users to log in to the system with a Microsoft account. For some users, they may be more accustomed to logging in with a local account and are unwilling to bind their personal information to a Microsoft account.
 How do the data processing capabilities in Laravel and CodeIgniter compare?
Jun 01, 2024 pm 01:34 PM
How do the data processing capabilities in Laravel and CodeIgniter compare?
Jun 01, 2024 pm 01:34 PM
Compare the data processing capabilities of Laravel and CodeIgniter: ORM: Laravel uses EloquentORM, which provides class-object relational mapping, while CodeIgniter uses ActiveRecord to represent the database model as a subclass of PHP classes. Query builder: Laravel has a flexible chained query API, while CodeIgniter’s query builder is simpler and array-based. Data validation: Laravel provides a Validator class that supports custom validation rules, while CodeIgniter has less built-in validation functions and requires manual coding of custom rules. Practical case: User registration example shows Lar
