

Many applications in computer science and machine learning (ML) require processing of multidimensional data sets that span coordinate systems, and a single data set may also need to store terabytes or petabytes of data. On the other hand, working with such datasets is also challenging because users may read and write data at irregular intervals and at different scales, often performing large amounts of parallel work.
In order to solve the above problems, Google developed TensorStore, an open source C and Python software library, designed for storing and operating n-dimensional data. Jeff Dean, head of Google AI, also tweeted that TensorStore is now officially open source.
The main functions of TensorStore include:
TensorStore has been used to solve engineering challenges in scientific computing and has also been used to create large machine learning models, such as to manage PaLM models during distributed training Parameters (checkpoints).
##GitHub address: https://github.com/google/tensorstore
API for data access and manipulationTensorStore provides a simple Python API for loading and manipulating large array data. For example, the following code creates a TensorStore object that represents a 56 trillion voxel 3D image of a fly brain and allows access to a 100x100 image patch data in a NumPy array:
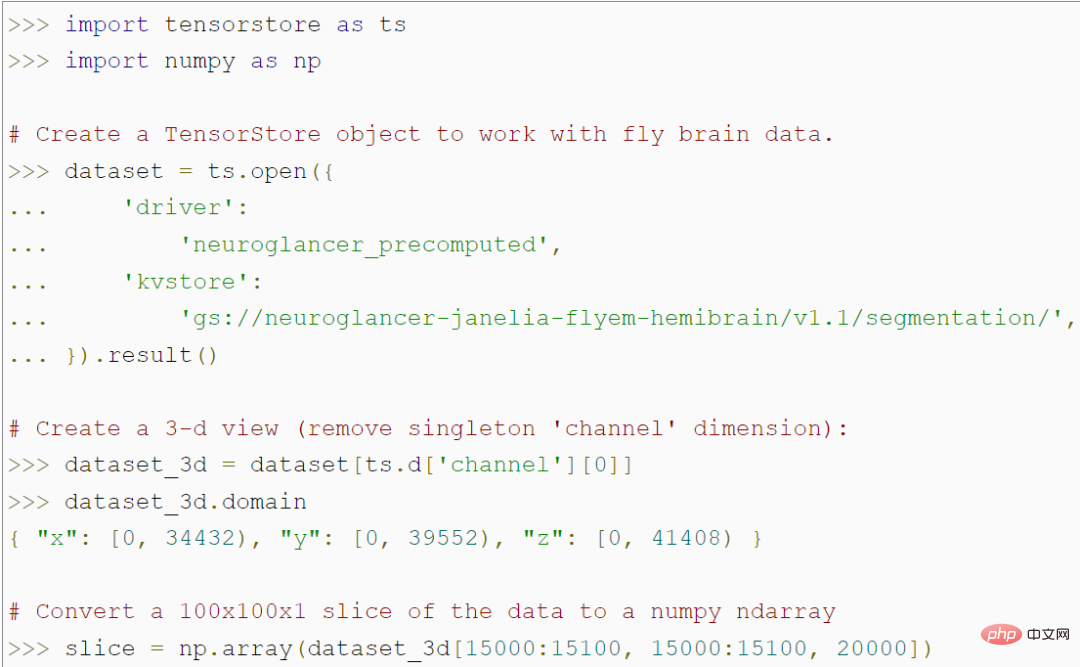
It is worth noting that this program does not access the actual data in memory until it accesses the specific 100x100 patch, so arbitrarily large underlying data sets can be loaded and manipulated without the need to convert the entire data Sets are stored in memory. TensorStore uses essentially the same indexing and operation syntax as standard NumPy.
In addition, TensorStore provides extensive support for advanced indexing features, including alignment, virtual views, and more.
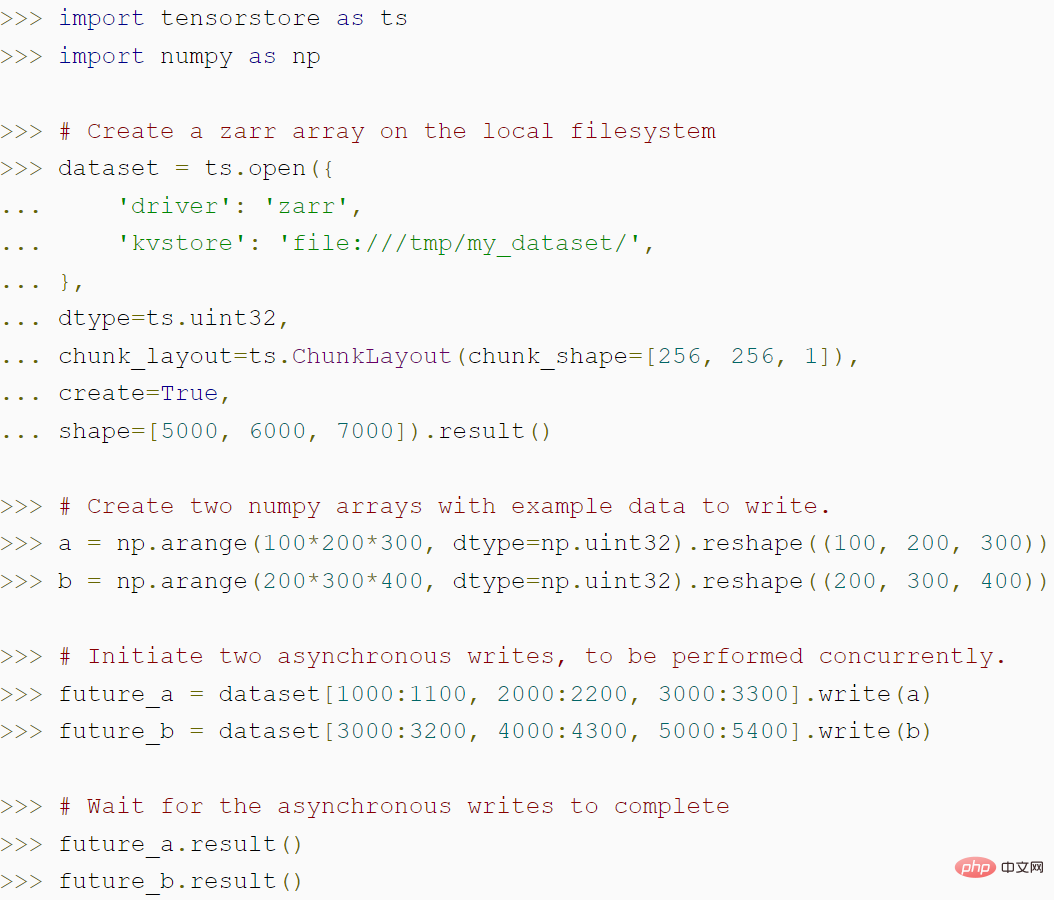
The following code demonstrates how to use TensorStore to create a zarr array, and how TensorStore's asynchronous API can achieve higher throughput:
It is well known that analyzing and processing large data sets requires extensive computing resources, often requiring parallelization of CPU or accelerator cores distributed across multiple machines. accomplish. Therefore, a basic goal of TensorStore is to implement parallel processing to achieve both safety and high performance. In fact, in tests in Google data centers, they found that as the number of CPUs increases, TensorStore read and write performance increases almost linearly:
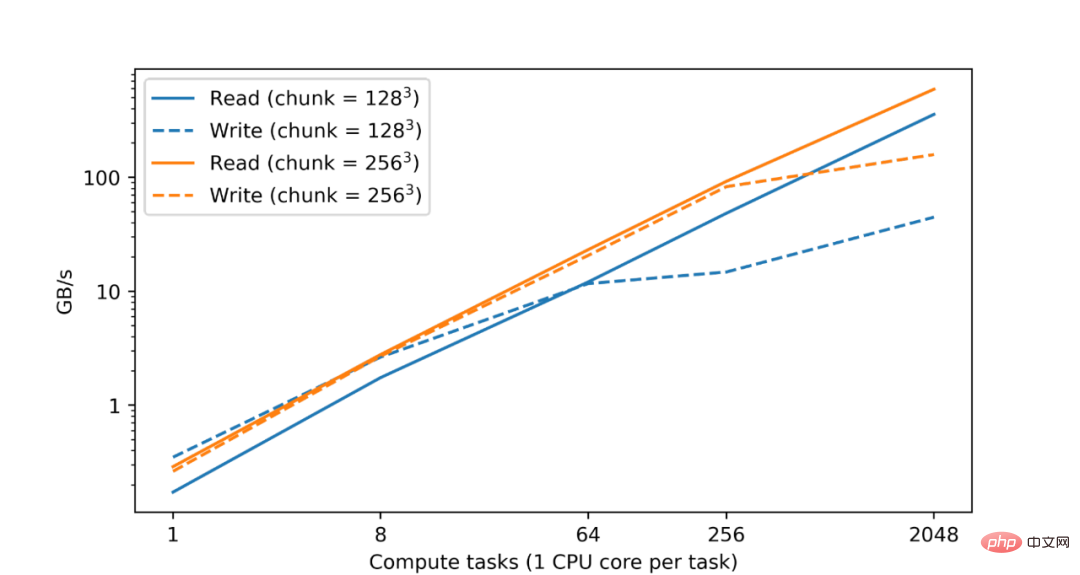
In terms of read and write performance of zarr format data sets on Google Cloud Storage (GCS), the read and write performance increases almost linearly with the number of computing tasks.
TensorStore also provides a configurable memory cache and an asynchronous API to allow read and write operations to continue in the background while the program completes other work. To make TensorStore's distributed computing compatible with data processing workflows, Google also integrates TensorStore with parallel computing libraries such as Apache Beam.
Example 1 Language model: In recent times, some advanced language models such as PaLM have appeared in the field of machine learning. These models contain hundreds of billions of parameters and exhibit astonishing capabilities in natural language understanding and generation. However, these models pose challenges to computing facilities. In particular, training a language model like PaLM requires thousands of TPUs working in parallel.
Efficiently reading and writing model parameters is a problem faced in the training process: for example, training is distributed on different machines, but parameters must be regularly saved to checkpoints; Another example is that a single training must only read a specific set of parameters to avoid the overhead required to load the entire model parameter set (which may be hundreds of GB).
TensorStore can solve the above problems. It has been used to manage checkpoints related to large (multipod) models and has been integrated with frameworks such as T5X and Pathways. TensorStore converts checkpoints to zarr format storage and chooses the block structure to allow each TPU's partitions to be read and written in parallel and independently.

When saving the checkpoint, the parameters are written in zarr format, block network The lattice is further divided for parameter meshing on the TPU. The host writes zarr blocks in parallel for each partition assigned to the host's TPU. Using TensorStore's asynchronous API, training continues even as data is still being written to persistent storage. When recovering from a checkpoint, each host reads only the partition blocks assigned to that host.
Example 2 Brain 3D Mapping: Synapse-Resolved Connectomics The goal is to map the wiring of the animal and human brain at the level of individual synaptic connections. Accomplishing this requires imaging the brain at extremely high resolution (nanoscale) over a field of view of millimeters or larger, resulting in data in the petabyte range. However, even now, data sets face problems with storage, processing, etc. Even a single brain sample can require millions of gigabytes of space.
Google has used TensorStore to solve the computational challenges associated with large-scale connectomics datasets. Specifically, TensorStore has begun to manage some connectomics datasets and uses Google Cloud Storage as the underlying object storage system.
Currently, TensorStore has been used for the human cerebral cortex dataset H01, and the original imaging data is 1.4 PB (approximately 500000 * 350000 * 5000 pixels). The raw data is then subdivided into independent blocks of 128x128x16 pixels and stored in a "Neuroglancer precomputed" format, which can be easily manipulated by TensorStore.

##Using TensorStore, you can easily access and manipulate the underlying data (fly brain reconstruction)
Those who want to get started can use the following method to install the TensorStore PyPI package:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tensorstore</span>
The above is the detailed content of Google solves the problem of storing and manipulating n-dimensional data with an open source software library. For more information, please follow other related articles on the PHP Chinese website!
 Data encryption storage measures
Data encryption storage measures
 What's going on with the red light on the light signal?
What's going on with the red light on the light signal?
 What are the marquee parameters?
What are the marquee parameters?
 How to reference css in html
How to reference css in html
 Configuration of python environment variables
Configuration of python environment variables
 The difference between a++ and ++a
The difference between a++ and ++a
 What are the drawing software?
What are the drawing software?
 A collection of common computer commands
A collection of common computer commands








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



