

"Life is short, You need python"!
Old coders love the elegance of Python. However, in a production environment, dynamic language features like Python that are not built to optimize performance can be dangerous. Therefore, popular high-performance libraries such as TensorFlow or PyTorch mainly uses python as an interface language for interacting with optimized C/C libraries.
There are many ways to optimize the performance of Python programs. From a compiler perspective, high performance can be embedded into a lower-level, statically analyzable language, such as C or C, and compiled into a runtime Lower overhead native machine code, allowing it to be comparable in performance to C/C.
Codon can be seen as such a compiler, using ahead-of-time compilation, specialized bidirectional type checking, and a new bidirectional intermediate representation to enable optional specificity in the language's syntax and compiler optimizations. Domain expansion. It enables professional programmers to write high-performance code in an intuitive, high-level and familiar way.
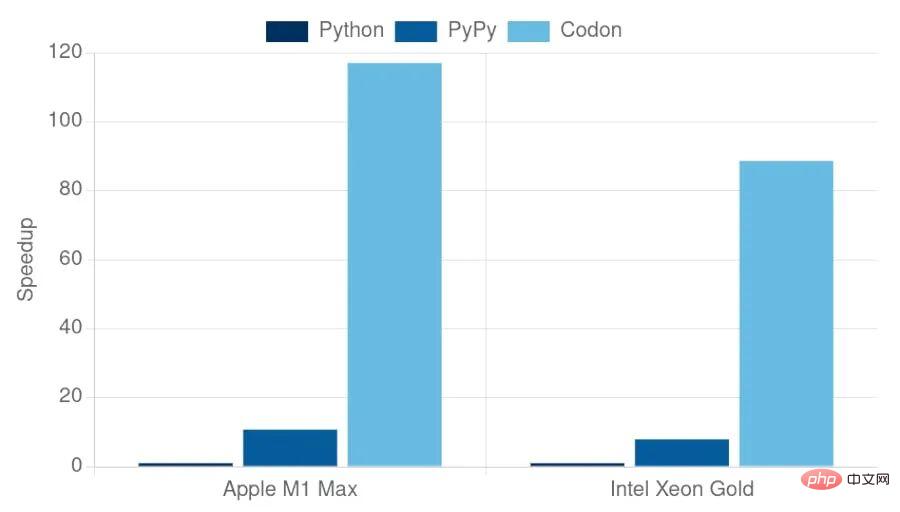
Unlike other performance-oriented Python implementations (such as PyPy or Numba), Codon is built from the ground up as a standalone system, compiled ahead of time into a static executable, without the need for an existing Python runtime (e.g., CPython). Therefore, in principle, Codon can achieve better performance and overcome Python runtime-specific issues such as global interpreter locks. In practice, Codon compiles Python scripts (like a C compiler) into native code, running 10 to 100 times faster than interpreted execution.
Codon is modeled based on the Seq language, which is a bioinformatics DSL. Seq was originally designed as a pyramid-style DSL with many advantages, such as ease of adoption, excellent performance, and powerful expressive capabilities. However, due to strict type rules, Seq does not support many common Python language constructs, nor does it provide a mechanism to easily implement new compiler optimizations. By applying bidirectional IR and improved type checkers, Codon provides a general solution to these problems based on Seq.
Codon covers most of Python's features and provides a framework for optimization in specific areas. In addition, a flexible type system is provided to better handle various language features. The type system is similar to RPython and PyPy and the static type system. These ideas have also been applied in the context of other dynamic languages, such as PRuby. The approach used by bidirectional IR has similarities to forward pluggable type systems, such as Java's inspection framework.
Although Codon's Intermediate Expression is not the first customizable IR, it does not support customization of all content, instead opting for a simple, clearly defined customization that can be combined with bidirectionality to achieve more complex characteristics. In terms of structure, CIR is inspired by LLVM and Rust's IR. These IRs benefit from a greatly simplified node set and structure, which in turn simplifies the implementation of IR channels. Structurally, however, those implementations fundamentally restructure the source code, eliminating semantic information that must be refactored to perform the transformation. To address this shortcoming, Taichi adopts a hierarchical structure that maintains control flow and semantic information at the expense of increased complexity. However, unlike Codon, these IRs are largely agnostic to the front-end of their language, making maintaining type correctness and generating new code somewhat impractical or even impossible. Therefore, CIR exploits the simplified hierarchy of these methods, maintaining the source code's control flow nodes and a completely reduced subset of internal nodes. Importantly, it enhances this structure with bidirectionality, making new IRs easy to generate and manipulate.
Codon utilizes static type checking and compiles to LLVM IR without using any runtime Type information, similar to previous work on end-to-end type checking in the context of dynamic languages such as Python. To this end, Codon ships with a static two-way type system, called LTS-DI, which utilizes HindleyMilner-style inference to infer types in the program without requiring the user to manually annotate the types (this practice, while supported, is not supported in Python Not common among developers).
Due to the nature of Python's syntax and common Pythonic idioms, LTS-DI adapts standard hm-like reasoning to support notable Python constructs such as comprehensions, iterators, generators, complex Function operations, variable parameters, static type checking, etc. To handle these and many other structures, LTS-DI relies on:
Many Python constructs also require compile-time expressions (similar to C's packed pr expressions), which are supported by codon. While these approaches are not uncommon in practice (e.g., C's templates use singletons), and lazy instantiation is already used in the HMF type system, we are not aware of their combined use in the context of type-checked Python programs. Finally, please note that Codon's type system in its current implementation is completely static and does not perform any runtime type inference; therefore, some Python features, such as runtime polymorphism or runtime reflection, are not supported. In the context of scientific computing, removing these features has been found to represent a reasonable trade-off between utility and performance.
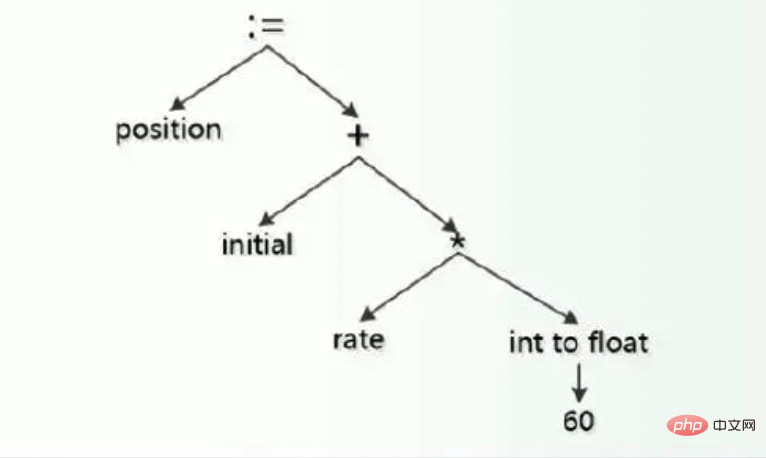
Many languages compile in a relatively straightforward way: the source code is parsed into an abstract syntax tree (AST), usually with the help of a framework such as LLVM, optimized and Convert to machine code. While this approach is relatively easy to implement, often the AST contains many more node types than are needed to represent a given program. This complexity can make implementing optimization, transformation, and analysis difficult or even impractical. Another approach is to convert the AST into an intermediate representation (IR) before performing the optimization pass. The intermediate representation usually contains a simplified set of nodes with well-defined semantics, making them more conducive to conversion and optimization.
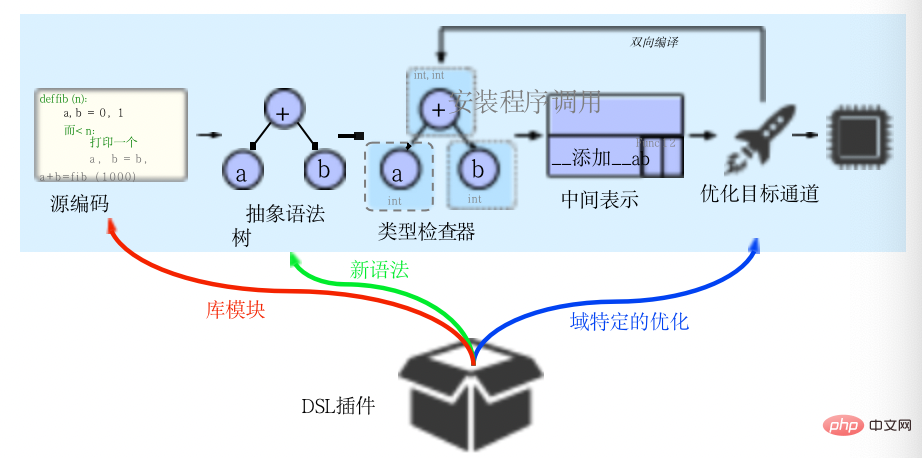
Codon implements this approach in its IR, which sits between the type checking and optimization phases, as shown in the image above. Codon's intermediate representation (CIR) is much simpler than the AST, with a simpler structure and fewer node types. Despite its simplicity, Codon's intermediate representations maintain much of the semantic information of the source code and facilitate "progressive reduction", enabling optimization at multiple levels of abstraction.
CIR is partly inspired by LLVM’s IR. In LLVM, a structure similar to the form of Single Static Allocation (SSA) is adopted, distinguishing values and variables allocated in a location, which are conceptually similar to memory locations. Compilation first proceeds in a linear manner, where the source code is Parsed into an abstract syntax tree on which type checking is performed to generate intermediate expressions. However, unlike other compilation frameworks, Codon is bidirectional, and IR optimization can return to the type checking stage to generate new nodes that were not in the original program. The framework is "domain extensible" and a "DSL plug-in" consists of library modules, syntax and domain-specific optimizations.
In order to achieve mapping of source code structure, a value can be nested into an arbitrarily large tree. This structure allows a CIR to be easily reduced to a control flow graph, for example. However, unlike LLVM, CIR originally used explicit nodes called streams to represent control flow, allowing a close structural correspondence with the source code. Explicitly representing the control flow hierarchy is similar to the approach taken by Taichi. Importantly, this makes optimizations and transformations that rely on precise concepts of control flow easier to implement. A simple example is streams, which keeps explicit loops in CIR and allows codon to easily identify common patterns of loops, rather than deciphering a maze of branches as it does in LLVM IR.
CIR does not explicitly represent operators like " ", but converts them into corresponding function calls. This enables seamless operator overloading of any type, with the same semantics as Python's. For example, the operator resolves to an add call.
A natural question that arises from this approach is how to implement operators for primitive types such as ints and floating point numbers. Codon solves this problem by allowing inline LLVM IR via @llvm function annotations, which enables all primitive operators to be written in codon source code. Information about operator properties such as commutativity and associativity can be passed as annotations in IR.
The traditional compilation pipeline is linear in its data flow: source code is parsed into AST, usually converted into IR, optimized, and finally converted into machine code. Codon introduced the concept of bidirectional IR, where the IR channel can return to the type checking stage, generating new IR nodes and specialized nodes that do not exist in the source program. The benefits include:
Similarly, the IR channel itself can be generic, using Codon's expression type system to operate on various types. IR types have no associated generics (unlike AST types). However, each CIR type carries a reference to the AST type used to generate it, as well as any AST generic type parameters. These associated AST types are used when re-invoking the type checker and allow CIR types to be queried for their underlying generics. Note that CIR types correspond to high-level abstractions; LLVM IR types are lower and do not map directly to Codon types.
In fact, the ability to instantiate new types during CIR delivery is critical to many CIR operations. For example, creating a tuple (x,y) from the given CIR values x and y requires instantiating a new tuple type tuple[X,Y] (where the uppercase identifier is the expression type), which in turn requires Instantiate new tuple operators for equality and inequality checking, iteration, hashing, and more. However, calling back the type checker makes this a seamless process.

The above picture is a simple example of mapping the Fibonacci function to CIR source code. The function fib maps to a CIR BodiedFunc with a single integer argument. The body contains an If control flow, which returns a constant or calls the function recursively to obtain the result. Note that operators like this are translated into function calls (e.g., add), but IR is mapped to the original source code in its structure, allowing simple pattern matching and conversion. In this case, simply overload the Call handler, check whether the function meets the conditions for replacement, and perform the action if it matches. Users can also define their own traversal scheme and modify the IR structure at will.
CIR provides a comprehensive analysis and transformation infrastructure: users write passes and register them with the password manager using various CIR built-in application classes, where More complex channels can take advantage of the bidirectionality of CIR and re-invoke the type checker for new CIR types, functions and methods, examples of which are shown in the figure below.
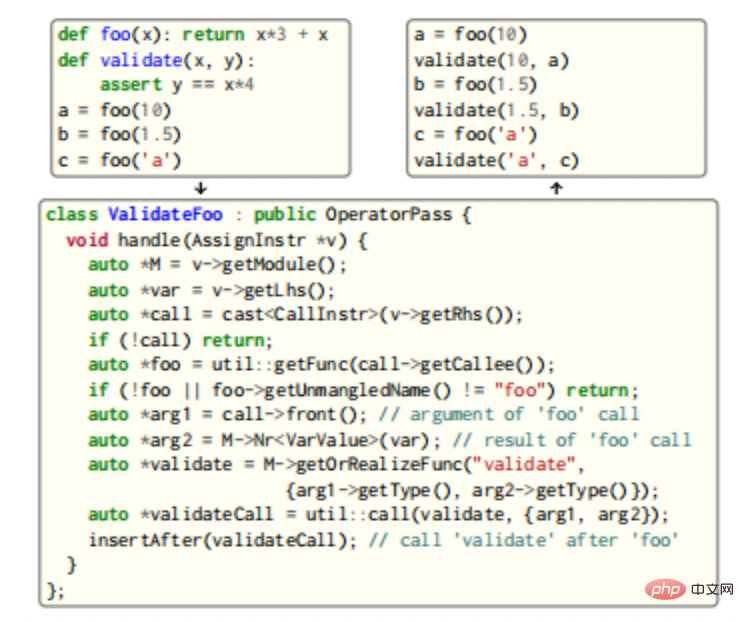
In this example, we will search for calls to function foo and insert after each call a parameter that validates foo and its output call. Since both functions are generic, the type checker is re-invoked to generate three new, unique validation instantiations. Instantiating new types and functions requires handling possible specializations and implementing additional nodes (for example, the == operator method __eq__ must be implemented in the example to implement validation), as well as caching the implementation for later use.
Codon uses LLVM to generate native code. Conversion from Codon IR to LLVM IR is usually a simple process. Most Codon types can also be intuitively converted to LLVM IR types: int becomes i64, float becomes double, bool becomes int8, and so on - these conversions also allow C/C interoperability. Tuple types are converted to struct types containing appropriate element types, which are passed by value (note, tuples are immutable in Python); this way of handling tuples allows LLVM to be fully optimized in most cases they. Reference types, such as lists, Dict, etc., are implemented as dynamically allocated objects and are passed by reference. These follow Python's variable semantic types and can be upgraded to optional types as needed to handle no values; optional types are passed Implemented as a tuple of LLVM's i1 type and the underlying type, where the former indicates whether the optional type contains a value. Options on reference types are specifically designed to use a null pointer to indicate missing values.
Generators are a popular language construct in Python; in fact, every for loop iterates over a generator. Importantly, generators in Codon carry no additional overhead and compile to equivalent standard C code whenever possible. For this purpose, Codon uses LLVM coroutines to implement generators.
Codon uses a small runtime library when executing code. In particular, the Boehm garbage collector is used to manage allocated memory. Codon provides two compilation modes: debug and release. Debug mode includes full debugging information, allowing the program to be debugged using tools such as GDB and LLDB, as well as full traceback information including file name and line number. Release mode performs more optimizations (including -O3 optimizations from GCC/Clang) and omits some security and debugging information. Therefore, users can use debug mode for fast programming and debugging cycles and release mode for high-performance deployment.
Due to the flexibility and bidirectional IR of the framework, and the overall expressiveness of Python syntax, Codon applications typically implement most of the functionality of domain-specific components in the source code itself . A modular approach can be packaged as dynamic libraries and Codon source files. This plugin can be loaded by the codon compiler at compile time.
Some frameworks, such as MLIR, allow customization. Condon IR, on the other hand, limits some types of nodes and relies on bidirectionality for further flexibility. In particular, CIR allows users to derive from "custom" types, streams, constants, and directives that interact with the rest of the framework through declarative interfaces. For example, custom nodes come from the appropriate custom base class (custom type, custom stream, etc.) and expose a "builder" to construct the corresponding LLVM IR. Implementing custom types and nodes involves defining a generator (e.g. building type) through a virtual method; the custom type class itself defines a method getBuilder to obtain an instance of this generator. This standardized construction of nodes works seamlessly with existing channels and analyses.
Many standard Python programs already work out of the box, making it easy to optimize several common patterns in Python code, such as Dictionary updates (can be optimized to use a single lookup instead of two), or consecutive string additions (can be collapsed into a single join to reduce allocation overhead).

The above graph shows the runtime performance of Codon, as well as the performance of CPython (v3.10) and PyPy (v7.3), on the benchmark test, the limit is one Set of "core" benchmarks, with no dependencies on external libraries. Compared to CPython and PyPy, Codon is always faster, sometimes by an order of magnitude. While benchmarks are a good indicator of performance, they are not without drawbacks and often don't tell the whole story. Codon allows users to write simple Python code for a variety of domains while delivering high performance on real-world applications and data sets.
Because Codon is built independently of the existing Python runtime, it is not affected by the CPython global interpreter lock and therefore can Take full advantage of multithreading. To support parallel programming, an extension to Codon allows end users to use OpenMP.
For OpenMP, the body of the parallel loop is outlined as a new function, which is then called by multiple threads by the OpenMP runtime. For example, the body of the loop in the figure below would be outlined as a function f that takes as parameters the variables a, b, c and the loop variable i.
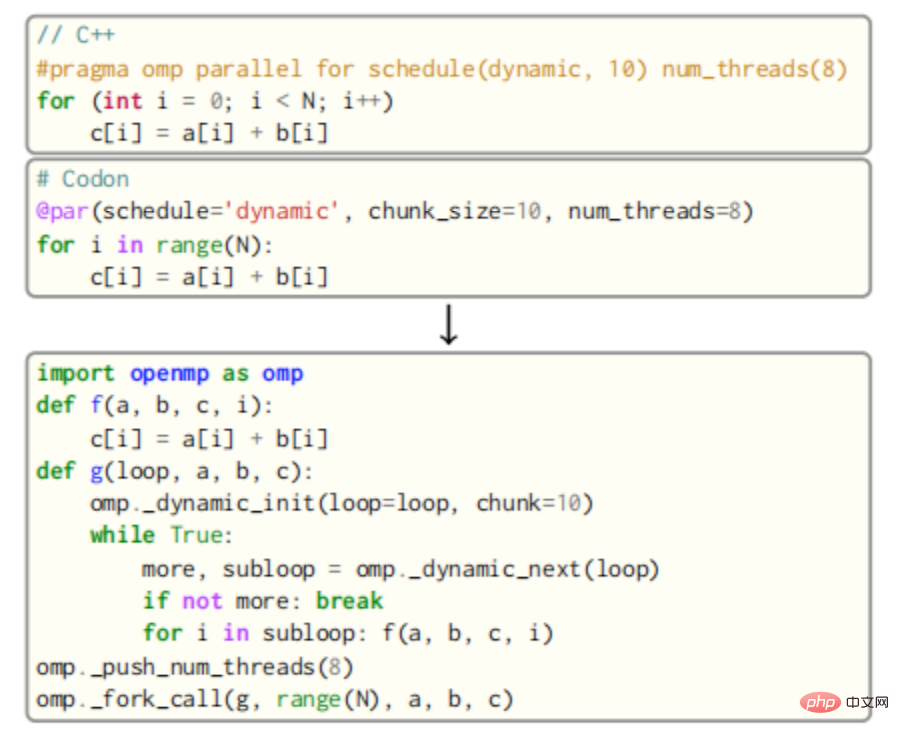
The call to f will then be inserted into a new function g that calls OpenMP’s dynamic round-robin scheduling routine with a block size of 10. Finally, all threads in the queue will call g through OpenMP's fork_call function. The result is shown in the correct code snippet in the image above, with special attention being paid to handling private variables as well as shared variables. Reduction of variables also requires additional code generation for atomic operations (or using locks), and an additional layer of OpenMP API calls.
Codon's bidirectional compilation is a key component of the OpenMP pass. The "templates" for various loops are implemented in the Codon source code. After code analysis, these "templates" are passed around and specialized by filling in loop bodies, block sizes and schedules, rewriting expressions that depend on shared variables, etc. This design greatly simplifies the implementation of the pass and adds a degree of versatility.
Unlike Clang or GCC, Codon's OpenMP channel can deduce which variables are shared and which are private, as well as the code of any reduction that is taking place. Custom reductions can be made simply by providing an appropriate atomic magic method (e.g. .aborom_add) on the reduction type. Codon iterates through the generator (the default behavior of Python loops) to an "imperative loop", i.e. a C-style loop with start, stop and step values. If the @par tag is present, the forced loop will be converted into an OpenMP parallel loop. Non-forced parallel loops are parallelized by spawning a new OpenMP task for each loop iteration and placing a synchronization point after the loop. This scheme allows all Python for-loops to be parallelized.
OpenMP transformations are implemented as a set of CIRs matched with for loops marked with the @par attribute, and these loops are transformed into the appropriate OpenMP constructs in the CIR. Almost all OpenMP structures are implemented as higher-order functions of Condon itself.
CoLa is a Codon-based DSL primarily targeted at block-based data compression, which is currently used by many common images and videos The core of the compression algorithm. These types of compression rely heavily on dividing an area of pixels into a series of smaller and smaller blocks, forming a multidimensional data hierarchy where each block needs to know its position relative to other blocks. For example, H.264 video compression divides the input frame into a series of 16x16 pixel blocks, each pixel into an 8x8 pixel block, and then divides these pixels into 4x4 pixel blocks. Tracking the position between these individual patches of pixels requires a large amount of information data, which quickly obscures the underlying algorithms in existing implementations.
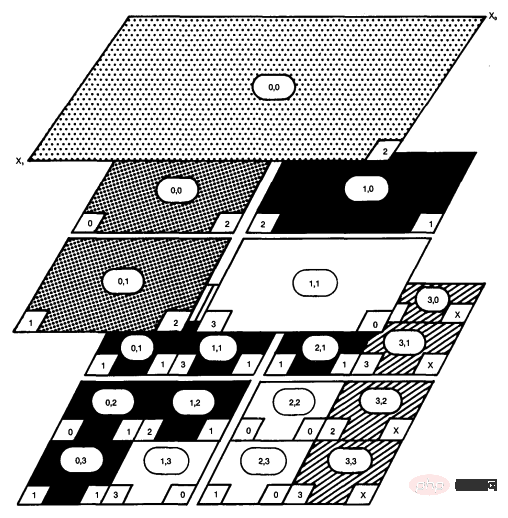
#CoLa introduces the Hierarchical Multidimensional Array (HMDA) abstraction, which simplifies the expression and use of hierarchical data. HMDA represents a multidimensional array with a notion of position, which tracks the origin of any given HMDA relative to some global coordinate system. HMDA can also track their size and stride length. With these three pieces of data, any HMDA can determine its position relative to any other HMDA at any point in the program. CoLa abstracts HMDA in Codon as a library centered around two new data types: blocks and views. The block creates and owns an underlying multidimensional array, and the view points to a specific area of the block. CoLa exposes two main hierarchies - construction operations, positional copying and partitioning, which create blocks and views respectively. CoLa supports standard indexing using integer and slice indexes, but also introduces two unique indexing schemes that emulate how compression standards describe data access. "Out-of-bounds" indexes allow users to access data surrounding a view, while "managed" indexes allow users to index one HMDA using another HMDA.
While the combination of Codon's physical properties and CoLa's abstractions provides users with the advantages of high-level language and compression-specific abstractions, the HMDA abstraction introduces significant runtime overhead due to the additional indexing operations required. For compression, many HMDA accesses occur at the innermost level of computation, so any additional computation on top of accessing the original array proves to be detrimental to the runtime. CoLa leverages the Codon framework to implement hierarchies, reducing the number of intermediate views created, and propagation attempts to infer the position of any given HMDA. This reduces the overall size of the hierarchy and simplifies the actual index calculations. Without these optimizations, CoLa is on average 48.8×, 6.7×, and 20.5× slower than the reference C code for JPEG and H.264]. After optimization, the performance has been greatly improved, with average running times of 1.06×, 0.67× and 0.91× respectively compared to the same reference code.
CoLa is implemented as a Codon plugin and, as such, comes with a library of compression primitives, as well as a set of CIR and LLVM channels that optimize creation and access routines. CoLa also simplifies common indexing and reduction operations using custom data structure access syntax and operators provided by Codon.
Essentially, codon is a domain-configurable framework for designing and quickly implementing DSL. By applying a specialized type checking algorithm and a new bidirectional IR algorithm, dynamic code in various areas can be made easy to optimize. Compared to using Python directly, Codon can match C/C++ performance without sacrificing high-level simplicity.
Currently, Codon has several Python features that are not supported, mainly including runtime polymorphism, runtime reflection and type operations (for example, dynamic method table modification, dynamic addition of class members, metaclasses and class decorators), there are also gaps in standard Python library coverage. Although Codon compiled Python can exist as a restrictive solution, it is worth paying attention to.
[Reference materials and related reading]
The above is the detailed content of Python performance optimization from a compiler perspective. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



