
 Technology peripherals
AI
From BERT to ChatGPT, a comprehensive review of nine top research institutions including Beihang University: the 'pre-training basic model' that we have pursued together over the years
Technology peripherals
AI
From BERT to ChatGPT, a comprehensive review of nine top research institutions including Beihang University: the 'pre-training basic model' that we have pursued together over the years
From BERT to ChatGPT, a comprehensive review of nine top research institutions including Beihang University: the 'pre-training basic model' that we have pursued together over the years

ChatGPT’s amazing performance in few-shot and zero-shot scenarios has made researchers more determined that “pre-training” is the right route.
Pretrained Foundation Models (PFM) are considered to be the basis for various downstream tasks under different data modes, that is, based on large-scale data, BERT, GPT-3, Pre-trained basic models such as MAE, DALLE-E and ChatGPT are trained to provide reasonable parameter initialization for downstream applications.
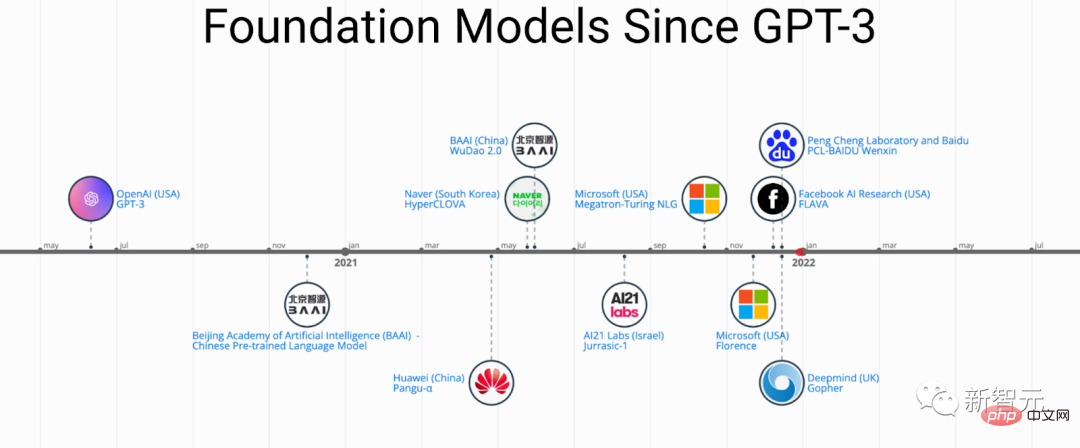
The pre-training idea behind PFM plays an important role in the application of large models. It is different from the previous use of convolution and The recursive module uses different methods for feature extraction. The generative pre-training (GPT) method uses Transformer as a feature extractor to perform autoregressive training on large data sets.
As PFM has achieved great success in various fields, a large number of methods, data sets and evaluation indicators have been proposed in papers published in recent years. The industry needs a paper starting from BERT. A comprehensive review tracking the development process of ChatGPT.
Recently, researchers from Beihang University, Michigan State University, Lehigh University, Nanyang Institute of Technology, Duke and many other well-known domestic and foreign universities and companies jointly wrote an article on pre-prediction This review of training basic models provides recent research progress in the fields of text, images, and graphs, as well as current and future challenges and opportunities.

Paper link: https://arxiv.org/pdf/2302.09419.pdf
Research We first review the basic components and existing pre-training of natural language processing, computer vision, and graph learning; then discuss other advanced PFM for other data models and unified PFM considering data quality and quantity; and the basic principles of PFM. Related research, including model efficiency and compression, security and privacy; finally, the article lists several key conclusions, including future research directions, challenges and open issues.
From BERT to ChatGPT
Pre-trained basic models (PFMs) are an important part of building artificial intelligence systems in the big data era. The three major artificial intelligence fields of natural language processing (NLP), computer vision (CV) and graph learning (GL) have been widely researched and applied.
PFMs are general models that are effective within various fields or in cross-domain tasks, showing great potential in learning feature representations in various learning tasks, such as text classification, Text generation, image classification, object detection and graph classification, etc.
PFMs show excellent performance in training multiple tasks with large-scale corpora and fine-tuning similar small-scale tasks, making it possible to initiate rapid data processing.
PFMs and pre-training
PFMs are based on pre-training technology, which aims to use a large amount of data and tasks to train a general model , which can be easily fine-tuned in different downstream applications.
The idea of pre-training originated from transfer learning in CV tasks. After realizing the effectiveness of pre-training in the CV field, people began to use pre-training techniques to improve models in other fields. performance. When pre-training techniques are applied to the NLP field, well-trained language models (LMs) can capture rich knowledge that is beneficial to downstream tasks, such as long-term dependencies, hierarchical relationships, etc.
In addition, the significant advantage of pre-training in the field of NLP is that the training data can come from any unlabeled text corpus, that is to say, there is an unlimited amount of training in the pre-training process data.
Early pre-training was a static method, such as NNLM and Word2vec, which was difficult to adapt to different semantic environments; later researchers proposed dynamic pre-training technologies, such as BERT and XLNet wait.

The history and evolution of PFMs in the fields of NLP, CV and GL
Based on pre-training technology PFMs use large corpora to learn general semantic representations. With the introduction of these pioneering works, various PFMs have emerged and been applied to downstream tasks and applications.
An obvious PFM application case is the recently popular ChatGPT.
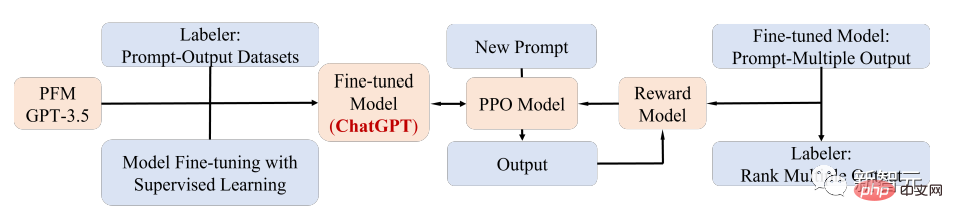
ChatGPT is a generative pre-trained Transformer, that is, GPT-3.5 after training on a mixed corpus of text and code. Obtained by fine-tuning; ChatGPT uses reinforcement learning from human feedback (RLHF) technology, which is currently the most promising method for matching large LM with human intentions.
The superior performance of ChatGPT may lead to a critical point in the transformation of the training paradigm of each type of PFMs, that is, the application of instruction aligning technology, including reinforcement learning (RL), prompt tuning and chain-of-thought, and ultimately toward general artificial intelligence.
In this article, researchers mainly review PFM related to text, images and graphs, which is also a relatively mature research classification method.
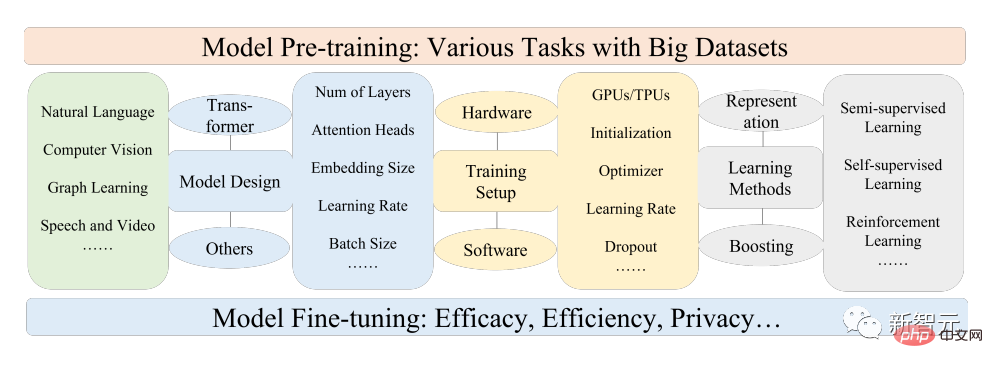
For text, language models can achieve a variety of tasks by predicting the next word or character, for example, PFMs can be used for machine translation, question answering systems, topic modeling, sentiment analysis, etc.
For images, similar to PFMs in text, large-scale datasets are used to train a large model suitable for multiple CV tasks.
For graphs, similar pre-training ideas are also used to obtain PFMs, which can be used for many downstream tasks.
In addition to PFMs for specific data domains, this article also reviews and explains some other advanced PFMs, such as PFMs for voice, video, and cross-domain data, and multi-modal PFMs.
In addition, a large fusion trend of PFMs that can handle multi-modality is emerging, which is the so-called unified PFMs; researchers first defined the concept of unified PFMs, and then The most advanced unified PFMs in recent research are reviewed, including OFA, UNIFIED-IO, FLAVA, BEiT-3, etc.
Based on the characteristics of existing PFMs in these three fields, the researchers concluded that PFMs have the following two major advantages:
1 . Only minimal fine-tuning is required to improve the model's performance on downstream tasks;
2. PFMs have passed the test in terms of quality.
Rather than building a model from scratch to solve a similar problem, a better option is to apply PFMs to a task-relevant dataset.
The huge prospects of PFMs have inspired a lot of related work to focus on issues such as model efficiency, security and compression.
The characteristics of this review are:
- Researchers tracked the latest research results on PFM in NLP, CV and Developments in GL are solidly summarized, discussed and provided with reflections on common PFM design and pre-training methods in these three main application areas.
- summarizes the development of PFMs in other multimedia fields, such as voice and video, and further discusses deeper topics about PFMs, including unified PFMs, Model efficiency and compression, as well as security and privacy.
- Through a review of PFMs for different tasks in various modalities, the main challenges and opportunities for future research on very large models in the era of big data are discussed, It will guide the development of a new generation of collaborative and interactive intelligence based on PFMs.
Reference: https://arxiv.org/abs/2302.09419
The above is the detailed content of From BERT to ChatGPT, a comprehensive review of nine top research institutions including Beihang University: the 'pre-training basic model' that we have pursued together over the years. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 The perfect combination of ChatGPT and Python: creating an intelligent customer service chatbot
Oct 27, 2023 pm 06:00 PM
The perfect combination of ChatGPT and Python: creating an intelligent customer service chatbot
Oct 27, 2023 pm 06:00 PM
The perfect combination of ChatGPT and Python: Creating an Intelligent Customer Service Chatbot Introduction: In today’s information age, intelligent customer service systems have become an important communication tool between enterprises and customers. In order to provide a better customer service experience, many companies have begun to turn to chatbots to complete tasks such as customer consultation and question answering. In this article, we will introduce how to use OpenAI’s powerful model ChatGPT and Python language to create an intelligent customer service chatbot to improve
 How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
Installation steps: 1. Download the ChatGTP software from the ChatGTP official website or mobile store; 2. After opening it, in the settings interface, select the language as Chinese; 3. In the game interface, select human-machine game and set the Chinese spectrum; 4 . After starting, enter commands in the chat window to interact with the software.
 How to develop an intelligent chatbot using ChatGPT and Java
Oct 28, 2023 am 08:54 AM
How to develop an intelligent chatbot using ChatGPT and Java
Oct 28, 2023 am 08:54 AM
In this article, we will introduce how to develop intelligent chatbots using ChatGPT and Java, and provide some specific code examples. ChatGPT is the latest version of the Generative Pre-training Transformer developed by OpenAI, a neural network-based artificial intelligence technology that can understand natural language and generate human-like text. Using ChatGPT we can easily create adaptive chats
 Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
chatgpt can be used in China, but cannot be registered, nor in Hong Kong and Macao. If users want to register, they can use a foreign mobile phone number to register. Note that during the registration process, the network environment must be switched to a foreign IP.
 How to use ChatGPT and Python to implement user intent recognition function
Oct 27, 2023 am 09:04 AM
How to use ChatGPT and Python to implement user intent recognition function
Oct 27, 2023 am 09:04 AM
How to use ChatGPT and Python to implement user intent recognition function Introduction: In today's digital era, artificial intelligence technology has gradually become an indispensable part in various fields. Among them, the development of natural language processing (Natural Language Processing, NLP) technology enables machines to understand and process human language. ChatGPT (Chat-GeneratingPretrainedTransformer) is a kind of
 How to build an intelligent customer service robot using ChatGPT PHP
Oct 28, 2023 am 09:34 AM
How to build an intelligent customer service robot using ChatGPT PHP
Oct 28, 2023 am 09:34 AM
How to use ChatGPTPHP to build an intelligent customer service robot Introduction: With the development of artificial intelligence technology, robots are increasingly used in the field of customer service. Using ChatGPTPHP to build an intelligent customer service robot can help companies provide more efficient and personalized customer services. This article will introduce how to use ChatGPTPHP to build an intelligent customer service robot and provide specific code examples. 1. Install ChatGPTPHP and use ChatGPTPHP to build an intelligent customer service robot.
 The perfect combination of ChatGPT and Python: building a real-time chatbot
Oct 28, 2023 am 08:37 AM
The perfect combination of ChatGPT and Python: building a real-time chatbot
Oct 28, 2023 am 08:37 AM
The perfect combination of ChatGPT and Python: Building a real-time chatbot Introduction: With the rapid development of artificial intelligence technology, chatbots play an increasingly important role in various fields. Chatbots can help users provide immediate and personalized assistance while also providing businesses with efficient customer service. This article will introduce how to use OpenAI's ChatGPT model and Python language to create a real-time chat robot, and provide specific code examples. 1. ChatGPT
