
 Technology peripherals
AI
The number of papers has increased sharply in the past ten years. How does deep learning slowly open the door to mathematical reasoning?
Technology peripherals
AI
The number of papers has increased sharply in the past ten years. How does deep learning slowly open the door to mathematical reasoning?
The number of papers has increased sharply in the past ten years. How does deep learning slowly open the door to mathematical reasoning?

Mathematical reasoning is a key manifestation of human intelligence, allowing us to understand and make decisions based on numerical data and language. Mathematical reasoning applies to a variety of fields, including science, engineering, finance and everyday life, and encompasses a range of abilities from basic skills such as pattern recognition and number crunching to advanced skills such as problem solving, logical reasoning and abstract thinking.
For a long time, developing AI systems that can solve mathematical problems and prove mathematical theorems has been a research focus in the fields of machine learning and natural language processing. This also dates back to the 1960s.
In the past ten years since the rise of deep learning, people’s interest in this field has grown significantly:
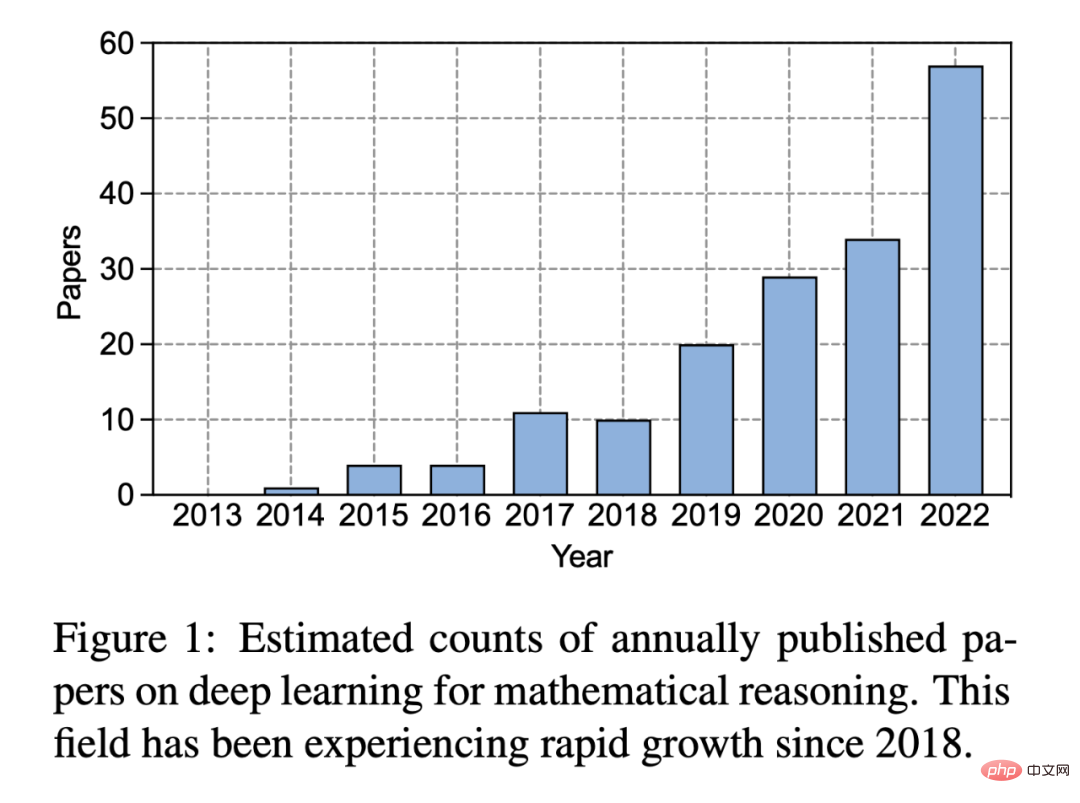
Figure 1: Estimated number of deep learning papers published each year on mathematical reasoning. Since 2018, this area has experienced rapid growth.
# Deep learning has shown great success in various natural language processing tasks, such as question answering and machine translation. Likewise, researchers have developed various neural network methods for mathematical reasoning, which have proven effective in handling complex tasks such as word problems, theorem proving, and geometric problem solving. For example, deep learning-based application problem solvers adopt a sequence-to-sequence framework and use an attention mechanism as an intermediate step to generate mathematical expressions. Furthermore, with large-scale corpora and Transformer models, pre-trained language models have achieved promising results on various mathematical tasks. Recently, large language models like GPT-3 have further advanced the field of mathematical reasoning by demonstrating impressive capabilities in complex reasoning and contextual learning.
In a recently released report, researchers from UCLA and other institutions systematically reviewed the progress of deep learning in mathematical reasoning.

##Paper link: https://arxiv.org/pdf/2212.10535.pdf
Project address: https://github.com/lupantech/dl4math
Specifically, this article discusses various tasks and data sets (Section 2), and examines advances in neural networks (Section 3) and pretrained language models (Section 4) in mathematics. The rapid development of contextual learning of large language models in mathematical reasoning is also explored (Section 5). The article further analyzes existing benchmarks and finds that less attention is paid to multimodal and low-resource environments (Section 6.1). Evidence-based research shows that current representations of computing capabilities are inadequate and deep learning methods are inconsistent with respect to mathematical reasoning (Section 6.2). Subsequently, the authors suggest improvements to the current work in terms of generalization and robustness, trustworthy reasoning, learning from feedback, and multimodal mathematical reasoning (Section 7).
Tasks and DatasetsThis section examines the various tasks and datasets currently available for studying mathematical reasoning using deep learning methods, see Table 2.
Math Word Problem
The Math Word Problem contains a A short narrative involving people, entities, and quantities whose mathematical relationships can be modeled by a set of equations whose solution reveals the final answer to the problem. Table 1 is a typical example. A question involves the four basic mathematical operations of addition, subtraction, multiplication, and division, with single or multiple steps. The challenge of application problems to NLP systems lies in the demand for language understanding, semantic analysis and various mathematical reasoning capabilities.

Existing word problem datasets cover elementary school-level problems that are scraped from online learning websites, collected from textbooks, or manually annotated by humans. Early word problem data sets were relatively small or limited to a small number of steps. Some recent datasets aim to increase the variety and difficulty of the problem. For example, Ape210K, the largest current public problem set, consists of 210k elementary school word problems; while problems in GSM8K can involve up to 8-step solutions. SVAMP is a benchmark that tests the robustness of deep learning models to word problems with simple variations. Some recently established datasets also involve modalities other than text. For example, IconQA provides an abstract diagram as a visual background, while TabMWP provides a tabular background for each question.
Most word problem data sets provide a justification for the annotated equation as a solution (see Table 1). To improve the performance and interpretability of learned solvers, MathQA is annotated with precise computational procedures, and MathQA-Python provides concrete Python procedures. Other datasets annotate questions with multi-step natural language solutions that are considered more suitable for human reading. Lila annotated many of the previously mentioned word problem data sets using the principles of Python programming.
Theoretical Proof
Automated theorem proving is a long-term challenge in the field of AI. The problem usually involves proving the truth of a mathematical theorem through a series of logical arguments. Theorem proving involves a variety of skills, such as choosing efficient multi-step strategies, using background knowledge, and performing symbolic operations such as arithmetic or derivations.
Recently, there has been growing interest in using language models for theorem proving in formal interactive theorem provers (ITPs). A theorem is stated in ITP's programming language and then simplified by generating "proof steps" until it is reduced to a known fact. The result is a sequence of steps that constitute a verified proof.
Informal theorem proving proposes an alternative medium for theorem proving, that is, using a mixture of natural language and "standard" mathematical notation (such as LATEX) to write statements and proofs. and checked for correctness by humans.
An emerging field of research aims to combine elements of informal and formal theorem proving. For example, Wu et al. (2022b) explore translating informal statements into formal statements, while Jiang et al. (2022b) released a new version of the miniF2F benchmark that adds informal statements and proofs, called miniF2F informal. Jiang et al. (2022b) explore converting provided (or generated) informal proofs into formal proofs.
Geometric Problems
Automated Solving of Geometric Problems (GPS) is also a long-standing artificial intelligence in mathematical reasoning research mission and has attracted widespread attention in recent years. Unlike word problems, geometry problems consist of natural language textual descriptions and geometric figures. As shown in Figure 2, multimodal input describes entities, properties, and relationships of geometric elements, while the goal is to find numerical solutions to unknown variables. GPS is a challenging task for deep learning methods due to the complex skills required. It involves the ability to parse multimodal information, engage in symbolic abstraction, utilize theorem knowledge, and engage in quantitative reasoning.
Early data sets promoted research in this field, however these data sets were relatively small or not publicly available, which limited the development of deep learning methods. To address this limitation, Lu et al. created the Geometry3K dataset, which consists of 3002 multiple-choice geometry questions annotated in a unified logical form for multimodal inputs. Recently, larger scale datasets such as GeoQA, GeoQA, and UniGeo have been introduced and annotated with programs that can be learned and executed by neural solvers to obtain final answers.
MATHEMATICS Q&A
Recent research shows that SOTA mathematical reasoning systems may be "brittle" in reasoning, that is, the model relies on false signals from specific data sets and plug-and-play calculations to achieve "satisfactory" performance. In order to solve this problem, new benchmarks have been proposed from various aspects. The Mathematics (Saxton et al., 2020) dataset includes many different types of mathematical problems, spanning arithmetic, algebra, probability, and calculus. This dataset can measure the algebraic generalization ability of the model. Similarly, MATH (Hendrycks et al., 2021) consists of challenging competition mathematics to measure a model's problem-solving ability in complex situations.
Some work added table background to question input. For example, FinQA, TAT-QA, and MultiHiertt collect questions that require table understanding and numerical reasoning to answer. Some studies have proposed unified benchmarks for large-scale numerical reasoning. NumGLUE (Mishra et al., 2022b) is a multi-task benchmark that aims to evaluate model performance on eight different tasks. Mishra et al. 2022a further pushed this direction by proposing Lila, which consists of 23 numerical reasoning tasks spanning a wide range of mathematical topics, language complexity, question formats, and background knowledge requirements.
AI has also made achievements in other types of quantitative problems. Numbers, charts, and drawings, for example, are essential media for conveying large amounts of information in a concise manner. FigureQA, DVQA, MNS, PGDP5K, and GeoRE were all introduced to study the ability of models to reason about quantitative relationships between graph-based entities. NumerSense investigates whether and to what extent existing pre-trained language models are able to sense numerical common sense knowledge. EQUATE formalizes various aspects of quantitative reasoning in a natural language reasoning framework. Quantitative reasoning also appears frequently in specific fields such as finance, science, and programming. For example, ConvFinQA performs numerical reasoning on financial reports in the form of conversational question and answer; ScienceQA involves numerical reasoning in the scientific field; and P3 studies the functional reasoning ability of deep learning models to find a valid input for a given program to return True.
Neural Networks for Mathematical Reasoning
The author of this article also summarizes several common neural networks used for mathematical reasoning.
Seq2Seq Network
Seq2Seq neural network has been successfully applied to mathematical reasoning tasks such as application problems and theorem proving , geometry questions and math question answers. Seq2Seq models use an encoder-decoder architecture that typically formalizes mathematical reasoning as a sequence generation task. The basic idea of this method is to map input sequences (such as mathematical problems) to output sequences (such as equations, programs, and proofs). Common encoders and decoders include long short-term memory network (LSTM) and gated recurrent unit (GRU). Extensive work has shown that Seq2Seq models have performance advantages over previous statistical learning methods, including their bidirectional variants BiLSTM and BiGRU. DNS is the first work to use the Seq2Seq model to convert sentences from word problems into mathematical equations.
Graph-based networks
The Seq2Seq method has the advantage of generating mathematical expressions and not relying on hand-crafted features. Mathematical expressions can be transformed into tree-based structures, such as abstract syntax trees (AST) and graph-based structures, which describe the structured information in the expression. However, this important information is not explicitly modeled by the Seq2Seq approach. To solve this problem, researchers developed graph-based neural networks to explicitly model the structure in expressions.
Sequence-to-tree (Seq2Tree) models explicitly model tree structures when encoding output sequences. For example, Liu et al. designed a Seq2Tree model to better utilize the AST information of equations. In contrast, Seq2DAG applies a sequence graph (Seq2Graph) framework when generating equations because the graph decoder is able to extract complex relationships between multiple variables. Graph-based information can also be embedded when encoding input mathematical sequences. For example, ASTactic applies TreeLSTM on AST to represent the input goals and premises of theorem proofs.
Attention-based network
The attention mechanism has been successfully applied to natural language processing and computer vision problems, taking the input hidden vector into account during the decoding process. Researchers have been exploring its role in mathematical reasoning tasks because it can be used to identify the most important relationships between mathematical concepts. For example, MATH-EN is a word problem solver that benefits from long-range dependency information learned through self-attention. Attention-based methods have also been applied to other mathematical reasoning tasks, such as geometry problems and theorem proving. In order to extract better representations, various attention mechanisms have been studied, such as Group-ATT, which uses different multi-head attention to extract various types of MWP features, and graph attention, which is applied to extract knowledge-aware information.
Other Neural Networks
Deep learning methods for mathematical reasoning tasks can also make use of other neural networks, such as convolutions Neural networks and multimodal networks. Some works use convolutional neural network architectures to encode input text, giving the model the ability to capture long-term relationships between symbols in the input. For example, Irving et al. proposed the first application of deep neural networks in theorem proving, which relied on convolutional networks for premise selection in large theories.
Multimodal mathematical reasoning tasks, such as geometric problem solving and graph-based mathematical reasoning, are formalized as visual question answering (VQA) questions. In this domain, visual inputs are encoded using ResNet or Faster-RCNN, while textual representations are obtained through GRU or LTSM. Subsequently, joint representations are learned using multimodal fusion models such as BAN, FiLM, and DAFA.
Other deep neural network structures can also be used for mathematical reasoning. Zhang et al. exploited the success of graph neural networks (GNN) in spatial reasoning and applied it to geometric problems. WaveNet is applied to theorem proving due to its ability to solve longitudinal time series data. Furthermore, Transformer was found to outperform GRU in generating mathematical equations in DDT. And, MathDQN is the first work exploring reinforcement learning for solving mathematical word problems, primarily leveraging its powerful search capabilities.
Pre-trained language model for mathematical reasoning
Pre-trained language model has shown significant performance improvements on a wide range of NLP tasks, also applied to mathematics Related issues, previous work has shown that pre-trained language models perform well in solving word problems, assisting with theorem proving and other mathematical tasks. However, using it for mathematical reasoning presents several challenges.
First of all, the pre-trained language model is not specifically trained on mathematical data. This may result in their lower proficiency in math-related tasks than in natural language tasks. There is also less mathematical or scientific data available for large-scale pre-training compared to text data.
Second, the size of pre-trained models continues to grow, making it expensive to train an entire model from scratch for a specific downstream task.
Additionally, downstream tasks may handle different input formats or modalities, such as structured tables or charts. To address these challenges, researchers must fine-tune pretrained models or adjust neural architectures on downstream tasks.
Finally, although pre-trained language models can encode a large amount of language information, looking at the goal of language modeling alone, it may be difficult for the model to learn numerical representation or high-level reasoning skills. With this in mind, recent research has investigated the infusion of mathematics-related skills in courses that begin with the basics.
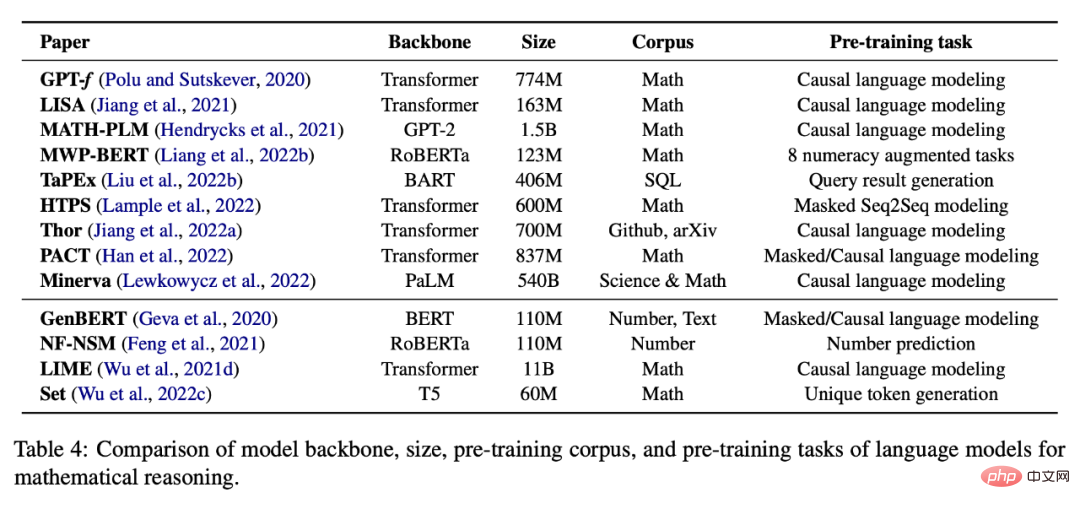
Self-supervised learning of mathematics
Table 4 below provides a pre-trained self-supervised task for mathematical reasoning A list of language models.
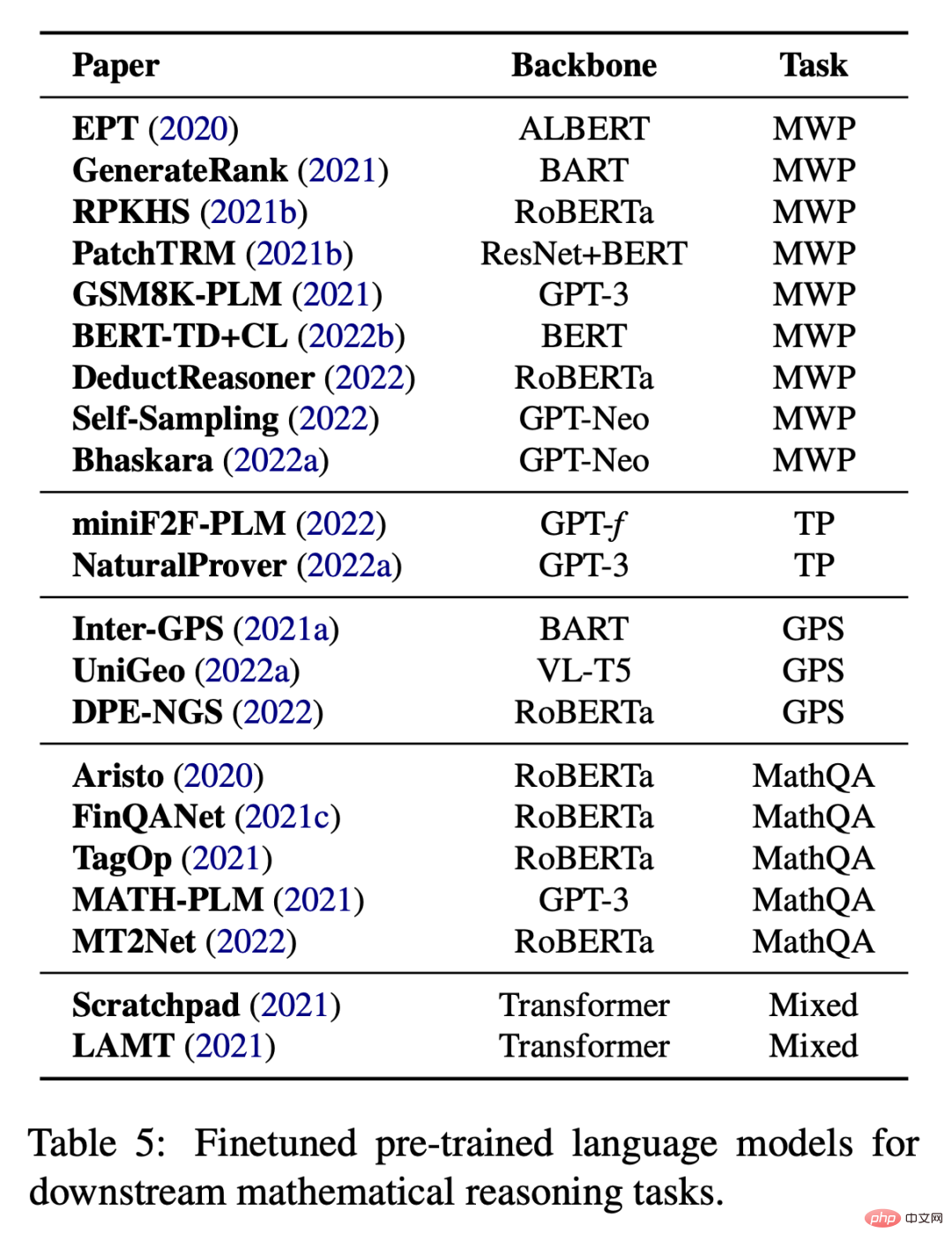
Task-specific mathematical fine-tuning
When there is not enough data to Task-specific fine-tuning is also a common practice when training large models from scratch. As shown in Table 5, existing work attempts to fine-tune pre-trained language models on various downstream tasks.
In addition to fine-tuning model parameters, many works also use pre-trained language models as encoders and combine them with other modules to complete downstream tasks. For example, IconQA proposes to use ResNet and BERT for graph recognition and BERT respectively. Text comprehension.
Contextual Learning in Mathematical Reasoning
A sample of context usually contains an input-output pair and some prompt words, for example, please select the largest number from the list .
Input: [2, 4, 1, 5, 8]
Output: 8.
Few-shot learning will give multiple samples, and then the model will predict the output on the last input sample. However, this standard few-shot prompting, which provides large language models with contextual samples of input-output pairs before test-time samples, has not been proven to be sufficient to achieve good performance on challenging tasks such as mathematical reasoning.
Chain-of-thought prompting (CoT) uses the intermediate natural language explanation as a prompt, allowing a large language model to first generate a reasoning chain and then predict the answer to an input question. For example, a CoT prompt for solving a word problem could be "Let's think step by step!" prompt will make large language models good zero-shot inferencers. Apart from this, most recent work has focused on how to improve thought chain reasoning in the setting of zero-shot inference. This type of work is mainly divided into two parts: (i) selecting better contextual samples and (ii) creating better inference chains.

Early thought chain work was to select context samples randomly or heuristically. Recent research has shown that this type of few-shot learning can be very unstable under different selections of contextual examples. Therefore, which contextual reasoning samples can make the most efficient prompts is still an unknown issue in academic circles. To address this limitation, some recent works have investigated various methods to optimize the context sample selection process. For example, Rubin et al. (2022) attempted to solve this problem by retrieving semantically similar samples. However, this approach does not work well on mathematical reasoning problems, and it is difficult to measure similarity if structured information (such as tables) is included. In addition, Fu et al. (2022) proposed a complexity-based prompt, selecting samples with complex reasoning chains (i.e., chains with more reasoning steps) as prompts. Lu et al. (2022b) proposed a method to select contextual samples through reinforcement learning. Specifically, the agent learns to find the best contextual sample from a pool of candidates, with the goal of maximizing the predicted reward for a given training sample when interacting with the GPT-3 environment. Furthermore, Zhang et al. (2022b) found that diversification of example problems can also improve model performance. They proposed a two-step approach to construct example problems in context: first, divide the problems of a given dataset into several groups; second, select a representative problem from each group and use A simple heuristic's zero-shot thinking chain generates its reasoning chain.
High quality reasoning chain
Early thought chain work mainly relied on a single human annotated reasoning chain as prompt . However, manually creating reasoning chains has two disadvantages: first, as tasks become more and more complex, current models may not be sufficient to learn to perform all necessary reasoning steps and cannot be easily generalized to different tasks; second, a single The decoding process is easily affected by faulty reasoning steps, leading to incorrect predictions in the final answer. To address this limitation, recent research has mainly focused on two aspects: (i) hand-crafting more complex examples, known as process-based methods; (ii) utilizing ensemble-like methods, known as outcome-based methods. After evaluating existing benchmarks and methods, the authors also discuss future research directions in this area. For more research details, please refer to the original paper.
The above is the detailed content of The number of papers has increased sharply in the past ten years. How does deep learning slowly open the door to mathematical reasoning?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Methods and steps for using BERT for sentiment analysis in Python
Jan 22, 2024 pm 04:24 PM
Methods and steps for using BERT for sentiment analysis in Python
Jan 22, 2024 pm 04:24 PM
BERT is a pre-trained deep learning language model proposed by Google in 2018. The full name is BidirectionalEncoderRepresentationsfromTransformers, which is based on the Transformer architecture and has the characteristics of bidirectional encoding. Compared with traditional one-way coding models, BERT can consider contextual information at the same time when processing text, so it performs well in natural language processing tasks. Its bidirectionality enables BERT to better understand the semantic relationships in sentences, thereby improving the expressive ability of the model. Through pre-training and fine-tuning methods, BERT can be used for various natural language processing tasks, such as sentiment analysis, naming
 Analysis of commonly used AI activation functions: deep learning practice of Sigmoid, Tanh, ReLU and Softmax
Dec 28, 2023 pm 11:35 PM
Analysis of commonly used AI activation functions: deep learning practice of Sigmoid, Tanh, ReLU and Softmax
Dec 28, 2023 pm 11:35 PM
Activation functions play a crucial role in deep learning. They can introduce nonlinear characteristics into neural networks, allowing the network to better learn and simulate complex input-output relationships. The correct selection and use of activation functions has an important impact on the performance and training results of neural networks. This article will introduce four commonly used activation functions: Sigmoid, Tanh, ReLU and Softmax, starting from the introduction, usage scenarios, advantages, disadvantages and optimization solutions. Dimensions are discussed to provide you with a comprehensive understanding of activation functions. 1. Sigmoid function Introduction to SIgmoid function formula: The Sigmoid function is a commonly used nonlinear function that can map any real number to between 0 and 1. It is usually used to unify the
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Latent space embedding: explanation and demonstration
Jan 22, 2024 pm 05:30 PM
Latent space embedding: explanation and demonstration
Jan 22, 2024 pm 05:30 PM
Latent Space Embedding (LatentSpaceEmbedding) is the process of mapping high-dimensional data to low-dimensional space. In the field of machine learning and deep learning, latent space embedding is usually a neural network model that maps high-dimensional input data into a set of low-dimensional vector representations. This set of vectors is often called "latent vectors" or "latent encodings". The purpose of latent space embedding is to capture important features in the data and represent them into a more concise and understandable form. Through latent space embedding, we can perform operations such as visualizing, classifying, and clustering data in low-dimensional space to better understand and utilize the data. Latent space embedding has wide applications in many fields, such as image generation, feature extraction, dimensionality reduction, etc. Latent space embedding is the main
 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
In today's wave of rapid technological changes, Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL) are like bright stars, leading the new wave of information technology. These three words frequently appear in various cutting-edge discussions and practical applications, but for many explorers who are new to this field, their specific meanings and their internal connections may still be shrouded in mystery. So let's take a look at this picture first. It can be seen that there is a close correlation and progressive relationship between deep learning, machine learning and artificial intelligence. Deep learning is a specific field of machine learning, and machine learning
 Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Almost 20 years have passed since the concept of deep learning was proposed in 2006. Deep learning, as a revolution in the field of artificial intelligence, has spawned many influential algorithms. So, what do you think are the top 10 algorithms for deep learning? The following are the top algorithms for deep learning in my opinion. They all occupy an important position in terms of innovation, application value and influence. 1. Deep neural network (DNN) background: Deep neural network (DNN), also called multi-layer perceptron, is the most common deep learning algorithm. When it was first invented, it was questioned due to the computing power bottleneck. Until recent years, computing power, The breakthrough came with the explosion of data. DNN is a neural network model that contains multiple hidden layers. In this model, each layer passes input to the next layer and
 NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
Nov 14, 2023 pm 03:09 PM
NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
Nov 14, 2023 pm 03:09 PM
Since Neural Radiance Fields was proposed in 2020, the number of related papers has increased exponentially. It has not only become an important branch of three-dimensional reconstruction, but has also gradually become active at the research frontier as an important tool for autonomous driving. NeRF has suddenly emerged in the past two years, mainly because it skips the feature point extraction and matching, epipolar geometry and triangulation, PnP plus Bundle Adjustment and other steps of the traditional CV reconstruction pipeline, and even skips mesh reconstruction, mapping and light tracing, directly from 2D The input image is used to learn a radiation field, and then a rendered image that approximates a real photo is output from the radiation field. In other words, let an implicit three-dimensional model based on a neural network fit the specified perspective
