

Explain in simple terms the working principle behind ChatGPT

ChatGPT is the latest language model released by OpenAI, a significant improvement over its predecessor GPT-3. Similar to many large-scale language models, ChatGPT can generate text in different styles and for different purposes, with better performance in accuracy, narrative detail, and contextual coherence. It represents the latest generation of large language models from OpenAI and is designed with a strong focus on interactivity.
OpenAI uses a combination of supervised and reinforcement learning to tune ChatGPT, with the reinforcement learning component making ChatGPT unique. OpenAI uses a "Reinforcement Learning with Human Feedback" (RLHF) training method, which uses human feedback in training to minimize unhelpful, distorted, or biased output.
This article will analyze the limitations of GPT-3 and the reasons why it arises from the training process. It will also explain the principle of RLHF and understand how ChatGPT uses RLHF to overcome the existing problems of GPT-3. questions, and finally the limitations of this approach will be explored.
Capability vs. Consistency in Large Language Models
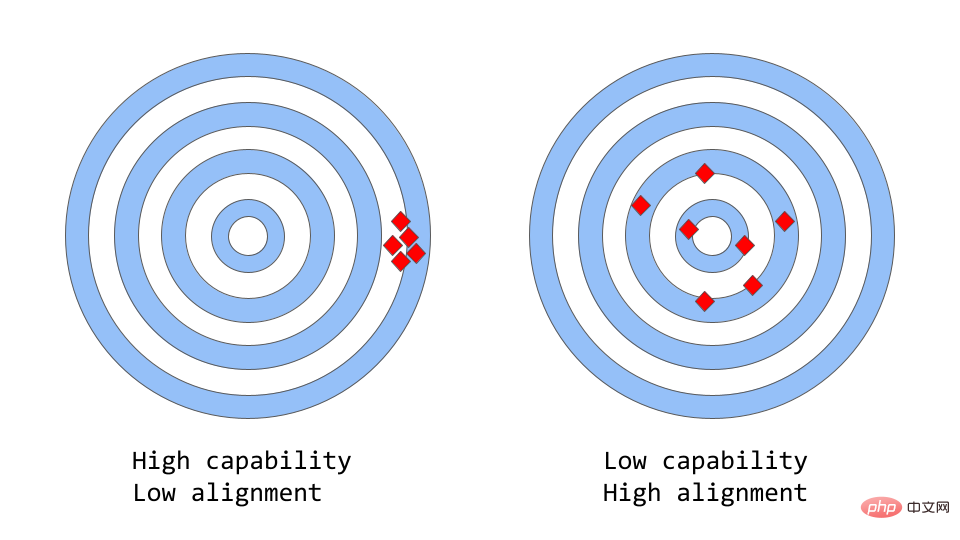
"Consistency vs. Capability" can be Think of it as a more abstract analogy of "accuracy vs precision".
#In machine learning, the ability of a model refers to the model's ability to perform a specific task or set of tasks. The capability of a model is usually assessed by the extent to which it is able to optimize its objective function. For example, a model used to predict market prices might have an objective function that measures the accuracy of the model's predictions. A model is considered to have a high ability to perform if it can accurately predict changes in fares over time.
Consistency focuses on what you actually want the model to do, not what it was trained to do. The question it raises is "whether the objective function meets expectations", based on the extent to which the model goals and behaviors meet human expectations. Suppose you want to train a bird classifier to classify birds as "sparrows" or "robins", using logarithmic loss as the training objective, and the ultimate goal is very high classification accuracy. The model may have a low log loss, i.e. the model is more capable but less accurate on the test set. This is an example of inconsistency, where the model is able to optimize the training goal but is inconsistent with the final goal.
The original GPT-3 is a non-consistent model. Large language models like GPT-3 are trained on large amounts of text data from the Internet and are capable of generating human-like text, but they may not always produce output that matches human expectations. In fact, their objective function is a probability distribution over a sequence of words, used to predict what the next word in the sequence will be.
But in real applications, the purpose of these models is to perform some form of valuable cognitive work, and there is a gap between how these models are trained and how they are expected to be used Significant differences. Although mathematically speaking, machines computing statistical distributions of word sequences may be an efficient choice for modeling language, humans generate language by selecting the text sequences that best fit a given situation, using known background knowledge and common sense. assist in this process. This can be a problem when language models are used in applications that require a high degree of trust or reliability, such as conversational systems or intelligent personal assistants.
While these large models, trained on massive amounts of data, have become extremely powerful over the past few years, they often fail to live up to their potential when used in practice to help make people's lives easier. Consistency problems in large language models often manifest themselves as:
- #Providing ineffective help: failing to follow explicit instructions from the user.
- The content is made up: a model that makes up non-existent or wrong facts.
- Lack of explainability: It is difficult for people to understand how the model arrived at a specific decision or prediction.
- Content Bias Harmful: A language model trained on biased, harmful data may exhibit this behavior in its output, even if it is not explicitly instructed to do so.
But specifically, where does the consistency problem come from? Is the way the language model is trained itself prone to inconsistencies?
How do language model training strategies create inconsistencies?
Next-token-prediction and masked-language-modeling are core technologies for training language models. In the first approach, the model is given a sequence of words as input and asked to predict the next word in the sequence. If you provide the model with the input sentence:
"The cat sat on the"
it might predict the next word as "mat", "chair" or " floor" because these words appear with high probability in the previous context; the language model is actually able to evaluate the likelihood of each possible word given the previous sequence.
The masked-language-modeling method is a variation of Next-token-prediction, where some words in the input sentence are replaced with special tokens, such as [MASK]. The model is then asked to predict the correct word that should be inserted into the mask position. If you give the model a sentence:
"The [MASK] sat on the "
it may predict that the words that should be filled in the MASK position are "cat" and "dog" ”.
One of the advantages of these objective functions is that it allows the model to learn the statistical structure of the language, such as common word sequences and word usage patterns. This often helps the model generate more natural and fluent text, and is an important step in the pre-training phase of every language model.
However, these objective functions can also cause problems, mainly because the model cannot distinguish important errors from unimportant errors. A very simple example is if you feed the model the sentence:
"The Roman Empire [MASK] with the reign of Augustus."
it may predict MASK The position should be filled in with "began" or "ended" because the probability of occurrence of these two words is very high.
In general, these training strategies may lead to inconsistent performance of language models on some more complex tasks, as a model that is only trained to predict the next word in a sequence of text Some higher-level representations of their meaning may not necessarily be learned. Therefore, the model is difficult to generalize to tasks that require a deeper understanding of language.
Researchers are studying various methods to solve the consistency problem in large language models. ChatGPT is based on the original GPT-3 model, but it was further trained using human feedback to guide the learning process to address inconsistencies in the model. The specific technology used is the aforementioned RLHF. ChatGPT is the first model to use this technology in real-world scenarios.
So how does ChatGPT use human feedback to solve the consistency problem?
Reinforcement Learning from Human Feedback
The method generally consists of three different steps:
- Yes Supervised tuning: A pre-trained language model is tuned on a small amount of labeled data to learn a supervised policy (i.e., SFT model) that generates output from a given list of prompts;
- Simulating human preferences: Annotators vote on a relatively large number of SFT model outputs, creating a new dataset of comparative data. A new model is trained on this data set, called the training reward model (RM);
- Proximal Policy Optimization (PPO): the RM model is used for further tuning and By improving the SFT model, the output result of PPO is the strategy model.
Step 1 is only performed once, while steps 2 and 3 can be repeated continuously: collect more comparison data on the current best policy model for training new RM model, and then train a new policy. Next, the details of each step will be detailed.
Step 1: Supervised Tuning Model
## The first step is to collect data to train a supervised policy Model.
- Data collection: Select a prompt list, and the annotator writes down the expected output as required. For ChatGPT, two different sources of prompts are used: some are prepared directly using annotators or researchers, and others are obtained from OpenAI's API requests (i.e., from GPT-3 users). While the entire process is slow and expensive, the end result is a relatively small, high-quality dataset (probably 12-15k data points) that can be used to tune a pre-trained language model.
- Model Selection: ChatGPT’s developers chose pre-trained models from the GPT-3.5 series rather than tuning the original GPT-3 model. The baseline model used is the latest version of text-davinci-003 (a GPT-3 model tuned by tuning the program code).
To create a universal chatbot like ChatGPT, developers tune on a "code model" rather than a plain text model.
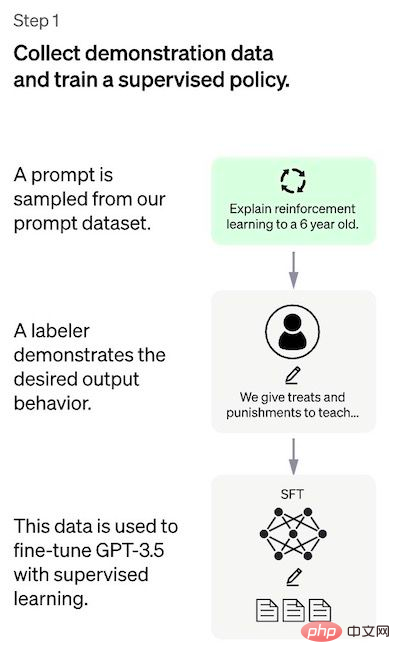
Due to the limited amount of data in this step, the SFT model obtained by this process may output text that is still not of user concern, and will often suffer from inconsistencies question. The problem here is that the supervised learning step has a high scalability cost.
To overcome this problem, the strategy used is to have the human annotator sort the different outputs of the SFT model to create the RM model, rather than having the human annotator create a larger refined model. Select a data set.
Step 2: Training the return model
The goal of this step is to learn the objective function directly from the data. The purpose of this function is to score SFT model outputs, which represents how desirable these outputs are to humans. This strongly reflects the specific preferences of the selected human annotators and the common guidelines they agree to follow. Ultimately, this process will result in a system that mimics human preferences from the data.
How it works is:
- Select a list of prompts and the SFT model generates multiple outputs for each prompt (4 to Any value between 9);
- The annotator sorts the output from best to worst. The result is a new labeled dataset that is approximately 10 times the size of the exact dataset used for the SFT model;
- This new data is used to train the RM model. The model takes as input SFT model outputs and sorts them in priority order.
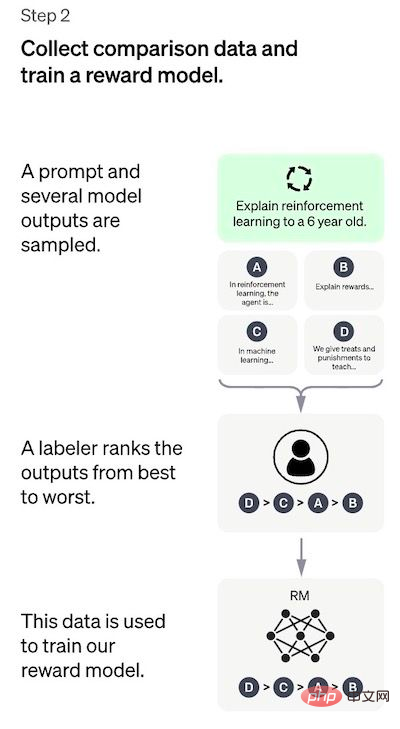
It is much easier for the annotator to sort the output than to tag from scratch, and the process can be more efficient to expand. In practice, the number of selected prompts is around 30-40k and includes different combinations of sorted output.
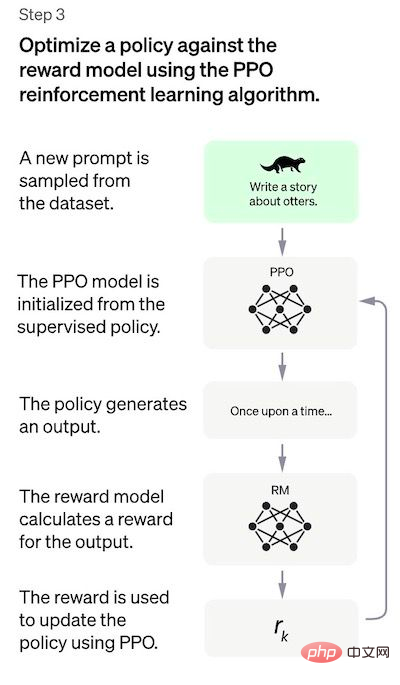
Step 3: Fine-tune the SFT model using the PPO model
In this step reinforcement learning is applied by optimizing the RM model to tune the SFT model. The specific algorithm used is called proximal policy optimization (PPO), and the tuning model is called proximal policy optimization model.
What is a PPO? The main features of this algorithm are as follows:
- PPO is an algorithm used to train agents in reinforcement learning. It is called an “on-policy” algorithm because it directly learns and updates the current policy, rather than learning from past experience like DQN’s “off-policy” algorithm. PPO continuously adjusts the strategy based on the actions taken by the agent and the rewards obtained; strategy to ensure stability. This is in sharp contrast to other strategies using gradient methods, which sometimes destabilize the policy by making large-scale updates to the policy;
- PPO uses a value function to estimate a given state or the expected return of an action. The value function is used to calculate the advantage function, which represents the difference between expected returns and current returns. The advantage function is then used to update the policy by comparing the actions taken by the current policy with the actions that the previous policy would have taken. This allows the PPO to make more informed updates to the strategy based on the estimated value of the actions taken.
- In this step, the PPO model is initialized by the SFT model and the value function is initialized by the RM model. This environment is a "bandit environment" that generates random prompts and expects responses to the prompts. For a given prompt and response, it generates a corresponding reward (determined by the RM model). The SFT model adds a KL penalty factor to each token to try to avoid over-optimization of the RM model.
Performance Evaluation
The model is evaluated based on three criteria:
Helpfulness: Judge the model's ability to follow user instructions and extrapolate instructions.
- Authenticity: Judgment models have a tendency to produce fictitious facts in closed-domain tasks.
- Harmlessness: The annotator evaluates whether the model’s output is appropriate and contains discriminatory content.
- The model was also evaluated on its performance with zero-shot learning on traditional NLP tasks such as question answering, reading comprehension, and summarization, some of which the developers found to be The model's performance is somewhat worse than that of GPT-3, an example of an "alignment tax" in which consistency procedures based on human feedback reinforcement learning come at the expense of performance on certain tasks.
Performance regression on these datasets can be greatly reduced by a trick called pre-training mixing: during training of the PPO model by gradient descent, the gradients of the SFT model and the PPO model are computed by mixing Gradient update.
Disadvantages of the method
A very obvious limitation of this method is that in the process of aligning the language model with human intention, it is used for fine-tuning The data of the model will be affected by various complex subjective factors, mainly including:The preference of the manual annotator who generated the demo data;
- Researchers who design studies and write label descriptions;
- Select prompts made by developers or provided by OpenAI customers;
- Annotator bias is included in both RM model training and model evaluation.
- The authors of ChatGPT also acknowledge the obvious fact that the annotators and researchers involved in the training process may not fully represent all potential end-users of language models.
In addition to this obvious "endogenous" limitation, this method also has some other shortcomings and problems that need to be solved:
- Lack of controlled studies: The reported results benchmark the performance of the final PPO model against the SFT model. This can be misleading: how do you know these improvements are due to RLHF? Controlled studies are therefore necessary, including investing the exact same number of annotation man-hours used to train the RM model, to create a larger curated supervised-tuned dataset with high-quality data. This allows an objective measurement of the performance improvements of RLHF methods compared to supervised methods. Simply put, the lack of such controlled studies leaves a fundamental question completely open: does RLHF really do a good job of consistent language modeling?
- Comparative data lacks ground truth: annotators often disagree on the ranking of model outputs. Technically, the risk is that a large amount of variance is added to the comparative data without any underlying truth.
- Human preferences are not homogeneous: The RLHF approach treats human preferences as homogeneous and static. It is obviously inaccurate to assume that all people have the same values. Although there are a large number of public values, humans still have many different perceptions on many matters.
- RM model prompt stability test: There are no experiments showing the sensitivity of the RM model to changes in the input prompt. If two prompts are syntactically different but semantically equivalent, can the RM model show a significant difference in the ranking of the model output? That is, how important is the quality of the prompt to RM?
- Other issues: In RL approaches, models can sometimes learn to control their own RM models to achieve desired results, leading to "over-optimized strategies." This may cause the model to recreate some patterns that, for some unknown reason, gave the RM model a higher score. ChatGPT patches this by using the KL penalty in the RM function.
Related reading:
- Related papers on the RLHF method for ChatGPT: Training language models to follow instructions with human feedback (https://arxiv.org/pdf/2203.02155.pdf), which actually describes in detail a model called InstructionGPT, which OpenAI calls the "sibling model" of ChatGPT.
- Learning to summarize from Human Feedback (https://arxiv.org/pdf/2009.01325.pdf) describes RLHF in the context of text summarization.
- PPO (https://arxiv.org/pdf/1707.06347.pdf): PPO algorithm paper.
- Deep reinforcement learning from human preferences (https://arxiv.org/abs/1706.03741)
- DeepMind proposed OpenAI in Sparrow Alternatives to RLHF (https://arxiv.org/pdf/2209.14375.pdf) and GopherCite (https://arxiv.org/abs/2203.11147) documents.
The above is the detailed content of Explain in simple terms the working principle behind ChatGPT. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 The perfect combination of ChatGPT and Python: creating an intelligent customer service chatbot
Oct 27, 2023 pm 06:00 PM
The perfect combination of ChatGPT and Python: creating an intelligent customer service chatbot
Oct 27, 2023 pm 06:00 PM
The perfect combination of ChatGPT and Python: Creating an Intelligent Customer Service Chatbot Introduction: In today’s information age, intelligent customer service systems have become an important communication tool between enterprises and customers. In order to provide a better customer service experience, many companies have begun to turn to chatbots to complete tasks such as customer consultation and question answering. In this article, we will introduce how to use OpenAI’s powerful model ChatGPT and Python language to create an intelligent customer service chatbot to improve
 How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
Installation steps: 1. Download the ChatGTP software from the ChatGTP official website or mobile store; 2. After opening it, in the settings interface, select the language as Chinese; 3. In the game interface, select human-machine game and set the Chinese spectrum; 4 . After starting, enter commands in the chat window to interact with the software.
 How to develop an intelligent chatbot using ChatGPT and Java
Oct 28, 2023 am 08:54 AM
How to develop an intelligent chatbot using ChatGPT and Java
Oct 28, 2023 am 08:54 AM
In this article, we will introduce how to develop intelligent chatbots using ChatGPT and Java, and provide some specific code examples. ChatGPT is the latest version of the Generative Pre-training Transformer developed by OpenAI, a neural network-based artificial intelligence technology that can understand natural language and generate human-like text. Using ChatGPT we can easily create adaptive chats
 Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
chatgpt can be used in China, but cannot be registered, nor in Hong Kong and Macao. If users want to register, they can use a foreign mobile phone number to register. Note that during the registration process, the network environment must be switched to a foreign IP.
 How to use ChatGPT and Python to implement user intent recognition function
Oct 27, 2023 am 09:04 AM
How to use ChatGPT and Python to implement user intent recognition function
Oct 27, 2023 am 09:04 AM
How to use ChatGPT and Python to implement user intent recognition function Introduction: In today's digital era, artificial intelligence technology has gradually become an indispensable part in various fields. Among them, the development of natural language processing (Natural Language Processing, NLP) technology enables machines to understand and process human language. ChatGPT (Chat-GeneratingPretrainedTransformer) is a kind of
 How to build an intelligent customer service robot using ChatGPT PHP
Oct 28, 2023 am 09:34 AM
How to build an intelligent customer service robot using ChatGPT PHP
Oct 28, 2023 am 09:34 AM
How to use ChatGPTPHP to build an intelligent customer service robot Introduction: With the development of artificial intelligence technology, robots are increasingly used in the field of customer service. Using ChatGPTPHP to build an intelligent customer service robot can help companies provide more efficient and personalized customer services. This article will introduce how to use ChatGPTPHP to build an intelligent customer service robot and provide specific code examples. 1. Install ChatGPTPHP and use ChatGPTPHP to build an intelligent customer service robot.
 SearchGPT: Open AI takes on Google with its own AI search engine
Jul 30, 2024 am 09:58 AM
SearchGPT: Open AI takes on Google with its own AI search engine
Jul 30, 2024 am 09:58 AM
Open AI is finally making its foray into search. The San Francisco company has recently announced a new AI tool with search capabilities. First reported by The Information in February this year, the new tool is aptly called SearchGPT and features a c
