
 Technology peripherals
AI
Meta AI opens 600 million+ metagenomic protein structure maps, and 15 billion language models were completed in two weeks
Technology peripherals
AI
Meta AI opens 600 million+ metagenomic protein structure maps, and 15 billion language models were completed in two weeks
Meta AI opens 600 million+ metagenomic protein structure maps, and 15 billion language models were completed in two weeks

This year, DeepMind published the predicted structures of approximately 220 million proteins, which covers almost all proteins of known organisms in the DNA database. Now another tech giant, Meta, is filling another void, that of microbes.
Simply put, Meta uses AI technology to predict the structures of approximately 600 million proteins from bacteria and other as-yet-uncharacterized microorganisms. Team leader Alexander Rives said: "These proteins are the structures that we know the least about, and they are very mysterious proteins. I think these findings provide the potential for a deeper understanding of biology."
Typically, language models are trained on large amounts of text. Meta To apply language models to proteins, Rives and colleagues took as input known protein sequences, which are composed of 20 amino acids represented by different letters. The network then learned to automatically complete proteins while masking a certain proportion of amino acids.
Meta named this network ESMFold. Although ESMFold's prediction accuracy is not as good as AlphaFold's, it is about 60 times faster than AlphaFold in predicting structures. This speed means protein structure predictions can be scaled up to larger databases.

- Paper address: https://www.biorxiv.org/content/10.1101/2022.07.20.500902v2
- Project address: https://github.com/facebookresearch/esm
Now, As a test, Meta decided to apply their model to a database of metagenomic DNA, all sourced from the environment, including soil, seawater, the human gut, skin and other microbial habitats. Meta AI announced the launch of the ESM Metagenomic Atlas containing more than 600 million proteins, which is the first comprehensive view of the "dark matter" of the protein universe. It is also the largest database of high-resolution predicted structures, 3 times larger than any existing protein structure database, and the first to provide comprehensive, large-scale coverage of metagenomic proteins.
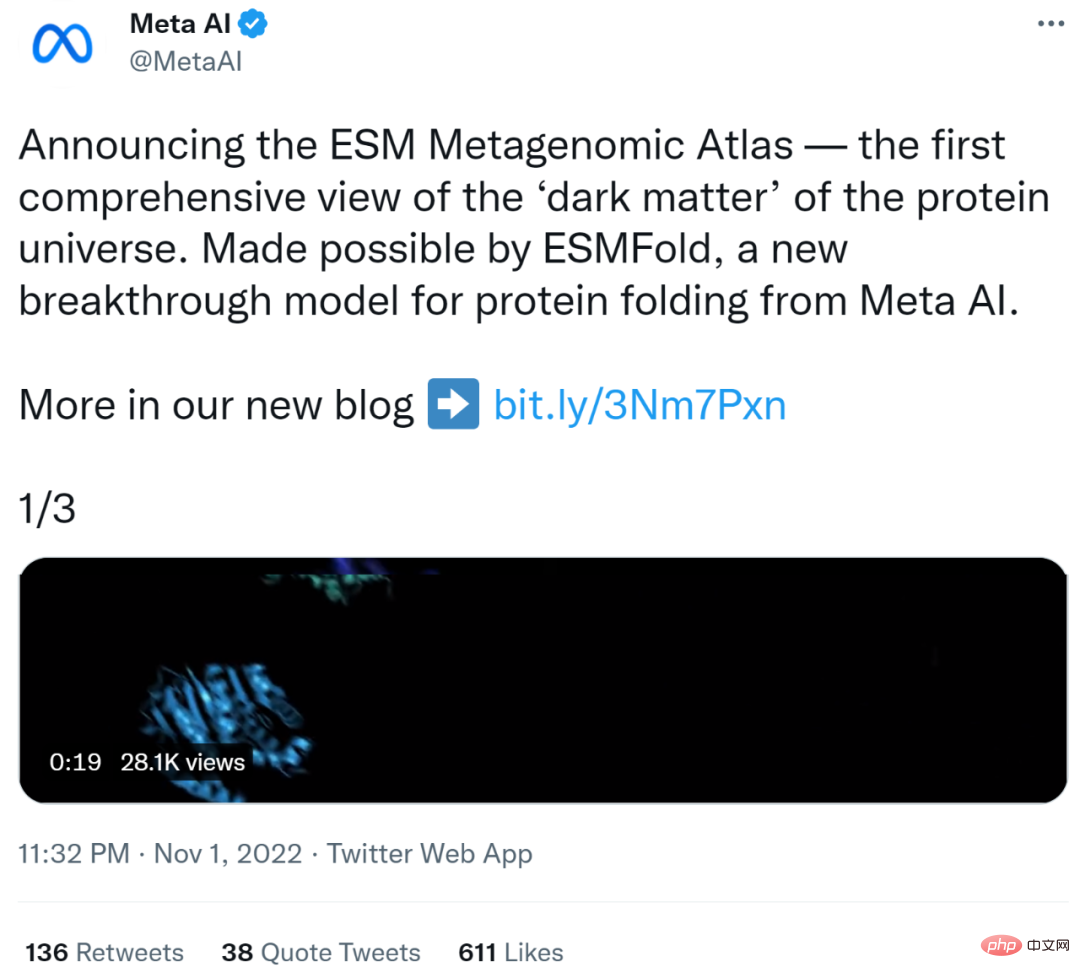
In total, the Meta team predicted more than 617 million protein structures in just two weeks. Rives said the predictions are free and available to anyone, just like the underlying code of the model.
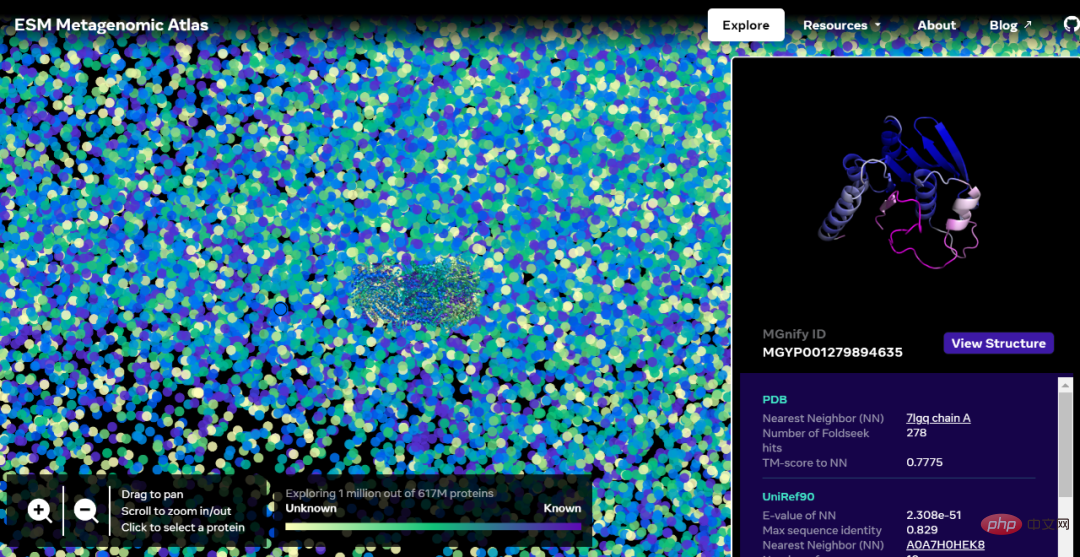
##Interactive version address: https://esmatlas.com/explore?at=1,1,21.999999344348925
For example, the picture below shows the prediction of PET enzyme by ESMFold.
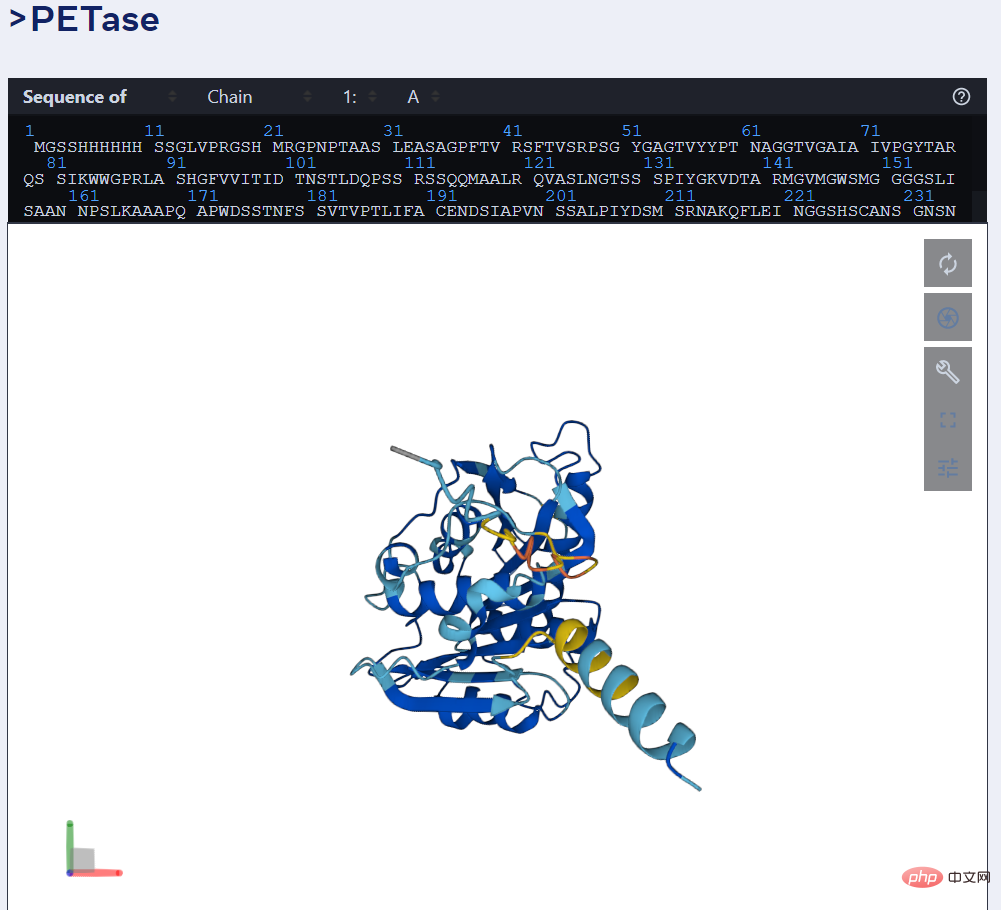
As we all know, proteins are complex and dynamic molecules encoded by genes and are mainly responsible for the basic processes of life. Proteins have amazing roles in biology. For example, the rods and cones in the human eye can sense light, so we can see the outside world; the molecular sensors that form the basis of hearing and touch; the complex molecules in plants that convert light energy into chemical energy; the molecules that drive microorganisms and The "motors" that make human muscles move; the enzymes that break down plastic; the antibodies that protect us from disease, etc. are all proteins.
In 1998, Jo Handelsman from the Department of Plant Pathology at the University of Wisconsin first proposed the concept of metagenomics. To a certain extent, it can be regarded as the idea of research and analysis of a single genome, and the English word for macro is meta-, which is also translated as meta.
Metagenomics reveals billions of protein sequences that are new to science and cataloged for the first time by NCBI, the European Bioinformatics Institute and in large databases compiled by public projects such as the Joint Genome Institute.
Novel protein folding method developed by Meta AI that leverages large language models to create the first comprehensive view of protein structure in metagenomic databases (with hundreds of millions of proteins). Meta found that language models can predict the atomic-level three-dimensional structure of proteins 60 times faster than existing SOTA protein structure prediction methods. This advance will help accelerate a new era of protein structure understanding, making it possible for the first time to understand the structures of the billions of proteins being cataloged by genetic sequencing technology.
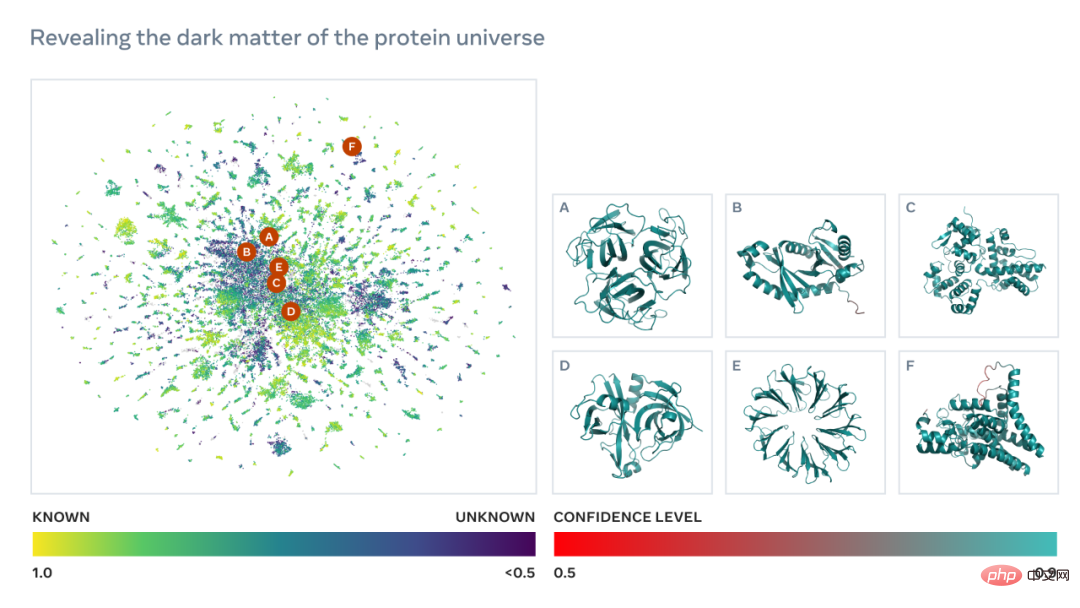
Unlocking the hidden world of nature: the first comprehensive view of metagenomic structural space
We know that advances in genetic sequencing have enabled the analysis of billions of metagenomic protein sequences Cataloging becomes possible. But experimentally determining the 3D structure of billions of proteins goes well beyond the scope of time-intensive laboratory techniques such as X-ray crystallography, which can take weeks or even years to detect a single protein. Computational approaches can provide insights into metagenomics proteins that are not possible using experimental techniques.
ESM Metagenomic Maps will enable scientists to search and analyze the structure of metagenomic proteins on a scale of hundreds of millions of proteins. This can help identify previously uncharacterized structures, search for distant evolutionary relationships, and discover new proteins that could be used in medicine and other applications.
Below is a map containing tens of thousands of high-confidence predictions, showing similarities to proteins with currently known structures. And, for the first time, the image shows a much larger region of protein structure space that was completely unknown.
Learn to read biological language
As shown in the figure below, the ESM-2 language model has been trained to predict the evolution process Amino acids masked by sequence. Meta AI found that, as a result of training, information about protein structure emerged in the model’s internal state. This is really surprising since the model was only trained on sequences.
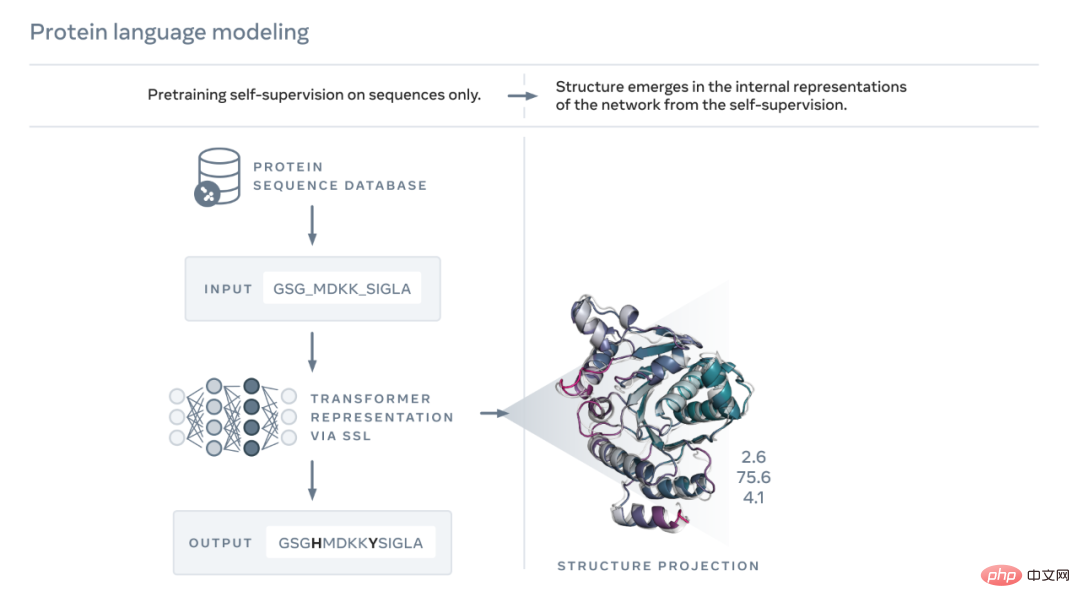
Just like the text of a paper or letter, proteins can be written as sequences of characters. Each character corresponds to one of 20 standard chemical elements (amino acids), each with different properties and which are the building blocks of proteins. These building blocks can be put together in astronomically different ways, for example for a protein consisting of 200 amino acids, there are 20^200 possible sequences, which is more than the number of atoms in the visible universe. Each sequence folds into a 3D shape (but not all sequences fold into a coherent structure, many fold into a disordered form), and it is this shape that largely determines the biological function of the protein.
Learning to read the biological language brings great challenges. While both protein sequences and text passages can be written as characters, there are deep and fundamental differences between them. A protein sequence describes the chemical structure of a molecule that folds into complex 3D shapes according to the laws of physics.
Protein sequences contain statistical patterns that convey information about protein folding structure. For example, if two positions in a protein co-evolve, or in other words, if a certain amino acid occurs at one position that usually pairs with a certain amino acid at the other position, this may mean that the two positions are in the folded structure interaction. This is similar to two pieces of a jigsaw puzzle, where evolution must choose the amino acids that fit together in a folded structure. This in turn means that we can often infer the structure of a protein by observing patterns in its sequence.
ESM uses AI to learn to read these patterns. In 2019, Meta AI provided evidence that language models learned the properties of proteins, such as their structure and function. Through a form of self-supervised learning called masked language modeling, Meta AI trained a language model on the sequences of millions of natural proteins. Using this method, the model must correctly fill in the blanks in the text paragraph, such as "To _ or not to , that is the _____".
After that, Meta AI trained a language model to fill in the gaps in the protein sequence. They found that information about protein structure and function emerged during this training. In 2020, Meta released a SOTA protein language model, ESM1b, for a variety of applications, including helping scientists predict the evolution of COVID-19 and discover the genetic causes of the disease.
Now, Meta AI has extended this approach to create the next generation protein language model ESM-2, which at 15 billion parameters is the largest protein language model to date. They found that when the model parameters were scaled up from 8 million to 15 billion, information emerged in the internal representation, enabling 3D structure predictions at atomic resolution.
Achieve orders of magnitude acceleration in protein folding
In the figure below, as the model is enlarged, a high-resolution protein structure appears. At the same time, as the model is scaled, new details appear in atomic-resolution images of the protein structure.

Using current SOTA computational tools, predicting the structure of hundreds of millions of protein sequences in a realistic time frame would take years, even using major research institutions The same goes for resources. Therefore, to make predictions at the metagenomic scale, a breakthrough in prediction speed is crucial.
Meta AI finds that using language models of protein sequences significantly speeds up structure predictions, by up to 60 times. This is sufficient to make predictions on an entire metagenomic database in just a few weeks and can be scaled to much larger databases than our currently published ones. In fact, this new structure prediction capability was able to predict the sequences of more than 600 million metagenome proteins in just two weeks on a cluster of approximately 2,000 GPUs.
Additionally, current SOTA structure prediction methods require searching large protein databases to identify relevant sequences. These methods require essentially a whole set of evolutionarily related sequences as input so that they can extract structure-related patterns. Meta AI's ESM-2 language model learns these evolutionary patterns during its training on protein sequences, enabling high-resolution predictions of 3D structures directly from protein sequences.
The figure below shows protein folding using the ESM-2 language model. The arrows from left to right show the flow of information in the network from the language model to the folding trunk to the structural module, and finally outputs 3D coordinates and confidence.
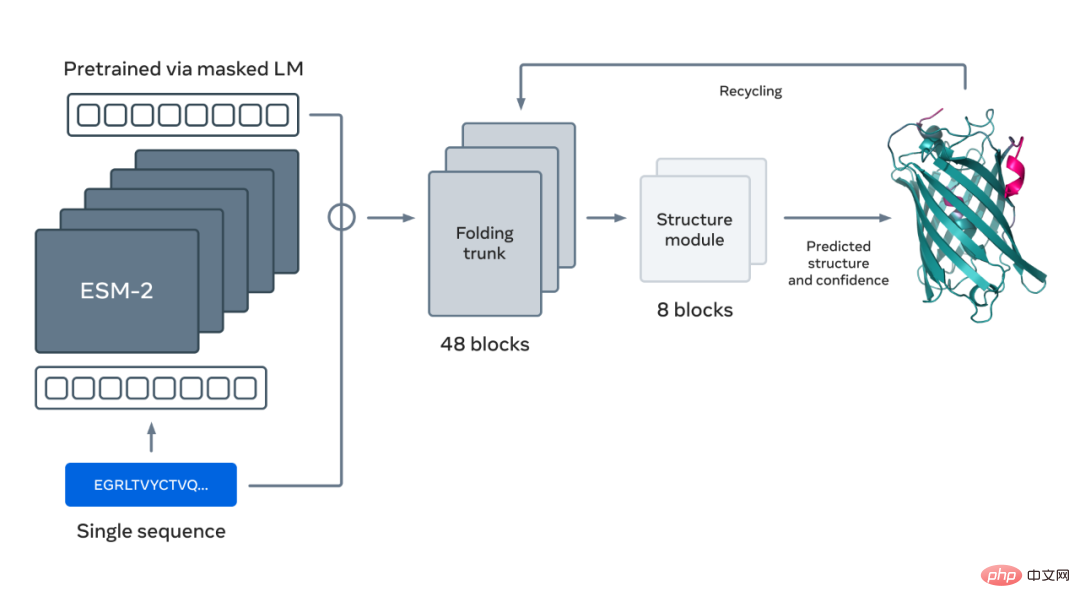
Please refer to the original article for more details.
Blog link: https://ai.facebook.com/blog/protein-folding-esmfold-metagenomics/
The above is the detailed content of Meta AI opens 600 million+ metagenomic protein structure maps, and 15 billion language models were completed in two weeks. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
Creating an Oracle database is not easy, you need to understand the underlying mechanism. 1. You need to understand the concepts of database and Oracle DBMS; 2. Master the core concepts such as SID, CDB (container database), PDB (pluggable database); 3. Use SQL*Plus to create CDB, and then create PDB, you need to specify parameters such as size, number of data files, and paths; 4. Advanced applications need to adjust the character set, memory and other parameters, and perform performance tuning; 5. Pay attention to disk space, permissions and parameter settings, and continuously monitor and optimize database performance. Only by mastering it skillfully requires continuous practice can you truly understand the creation and management of Oracle databases.
 How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
To create an Oracle database, the common method is to use the dbca graphical tool. The steps are as follows: 1. Use the dbca tool to set the dbName to specify the database name; 2. Set sysPassword and systemPassword to strong passwords; 3. Set characterSet and nationalCharacterSet to AL32UTF8; 4. Set memorySize and tablespaceSize to adjust according to actual needs; 5. Specify the logFile path. Advanced methods are created manually using SQL commands, but are more complex and prone to errors. Pay attention to password strength, character set selection, tablespace size and memory
 How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
The core of Oracle SQL statements is SELECT, INSERT, UPDATE and DELETE, as well as the flexible application of various clauses. It is crucial to understand the execution mechanism behind the statement, such as index optimization. Advanced usages include subqueries, connection queries, analysis functions, and PL/SQL. Common errors include syntax errors, performance issues, and data consistency issues. Performance optimization best practices involve using appropriate indexes, avoiding SELECT *, optimizing WHERE clauses, and using bound variables. Mastering Oracle SQL requires practice, including code writing, debugging, thinking and understanding the underlying mechanisms.
 How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
Field operation guide in MySQL: Add, modify, and delete fields. Add field: ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY] [AUTO_INCREMENT] Modify field: ALTER TABLE table_name MODIFY column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY]
 What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
The integrity constraints of Oracle databases can ensure data accuracy, including: NOT NULL: null values are prohibited; UNIQUE: guarantee uniqueness, allowing a single NULL value; PRIMARY KEY: primary key constraint, strengthen UNIQUE, and prohibit NULL values; FOREIGN KEY: maintain relationships between tables, foreign keys refer to primary table primary keys; CHECK: limit column values according to conditions.
 Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Nested queries are a way to include another query in one query. They are mainly used to retrieve data that meets complex conditions, associate multiple tables, and calculate summary values or statistical information. Examples include finding employees above average wages, finding orders for a specific category, and calculating the total order volume for each product. When writing nested queries, you need to follow: write subqueries, write their results to outer queries (referenced with alias or AS clauses), and optimize query performance (using indexes).
 How to configure Debian Apache log format
Apr 12, 2025 pm 11:30 PM
How to configure Debian Apache log format
Apr 12, 2025 pm 11:30 PM
This article describes how to customize Apache's log format on Debian systems. The following steps will guide you through the configuration process: Step 1: Access the Apache configuration file The main Apache configuration file of the Debian system is usually located in /etc/apache2/apache2.conf or /etc/apache2/httpd.conf. Open the configuration file with root permissions using the following command: sudonano/etc/apache2/apache2.conf or sudonano/etc/apache2/httpd.conf Step 2: Define custom log formats to find or
 What does oracle do
Apr 11, 2025 pm 06:06 PM
What does oracle do
Apr 11, 2025 pm 06:06 PM
Oracle is the world's largest database management system (DBMS) software company. Its main products include the following functions: relational database management system (Oracle database) development tools (Oracle APEX, Oracle Visual Builder) middleware (Oracle WebLogic Server, Oracle SOA Suite) cloud service (Oracle Cloud Infrastructure) analysis and business intelligence (Oracle Analytics Cloud, Oracle Essbase) blockchain (Oracle Blockchain Pla
