

ChatGPT is the new top player in the AI circle at the end of this year. People are amazed by its powerful question and answer language capabilities and programming knowledge. But the more powerful the model, the higher the technical requirements behind it.

ChatGPT is based on the GPT 3.5 series of models and introduces "manually labeled data reinforcement learning" (RLHF) to continuously fine-tune the pre-trained language model , designed to allow large language models (LLM) to learn to understand human commands and learn to give optimal answers based on given prompts.
This technical idea is the current development trend of language models. Although this type of model has great development prospects, the cost of model training and fine-tuning is very high.
According to the information currently disclosed by OpenAI, the training process of ChatGPT is divided into three stages:
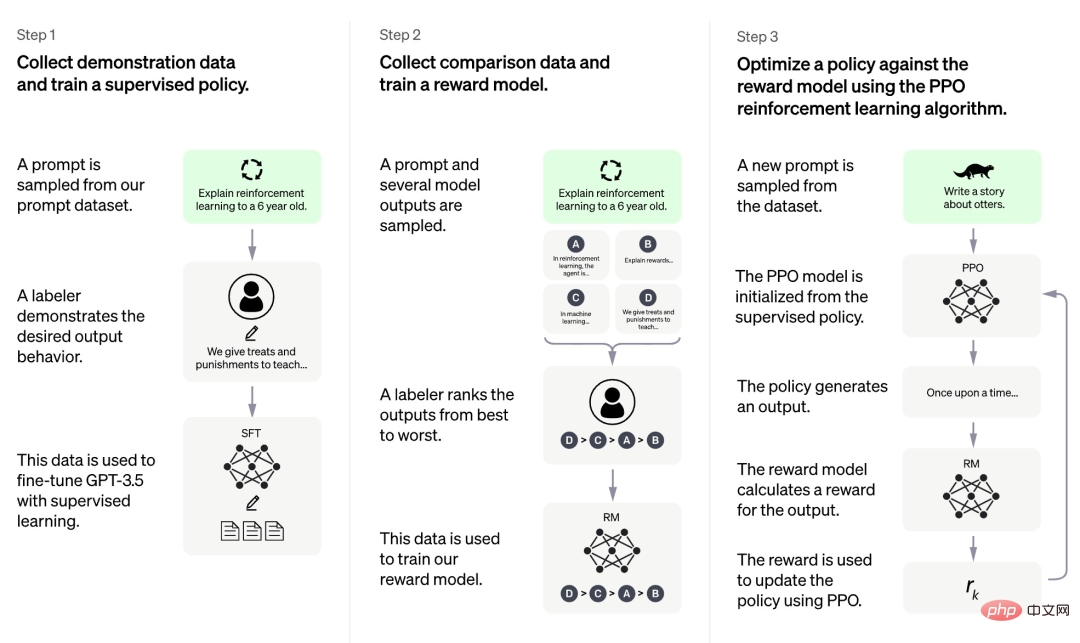
First of all, the first stage is a supervised policy model similar to GPT 3.5. This basic model is difficult to understand the intentions contained in different types of human instructions, and it is also difficult to judge the quality of the generated content. The researchers randomly selected some samples from the prompt data set, and then asked professional annotators to give high-quality answers based on the specified prompt. The prompts and their corresponding high-quality answers obtained through this manual process were used to fine-tune the initial supervised policy model to provide basic prompt understanding and initially improve the quality of the generated answers.
The second stage research team extracts multiple outputs generated by the model according to the given prompt, then asks human researchers to sort these outputs, and then uses the sorted data to train the reward model. RM). ChatGPT adopts pair-wise loss to train RM.
In the third phase, the research team uses reinforcement learning to enhance the capabilities of the pre-training model, and uses the RM model learned in the previous phase to update the parameters of the pre-training model.
We can find that among the three stages of ChatGPT training, only the third stage does not require manual annotation of data, while both the first and second stages require a large amount of manual annotation. Therefore, although models such as ChatGPT perform very well, in order to improve their ability to follow instructions, the labor cost is very high. As the scale of the model becomes larger and the scope of capabilities becomes wider and wider, this problem will become more serious and eventually become a bottleneck hindering the development of the model.
Some studies have tried to propose ways to solve this bottleneck. For example, the University of Washington and other institutions recently jointly published a paper "SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions", proposing The new framework SELF-INSTRUCT improves the instruction-following capabilities of pre-trained language models by guiding the model's own generation process.

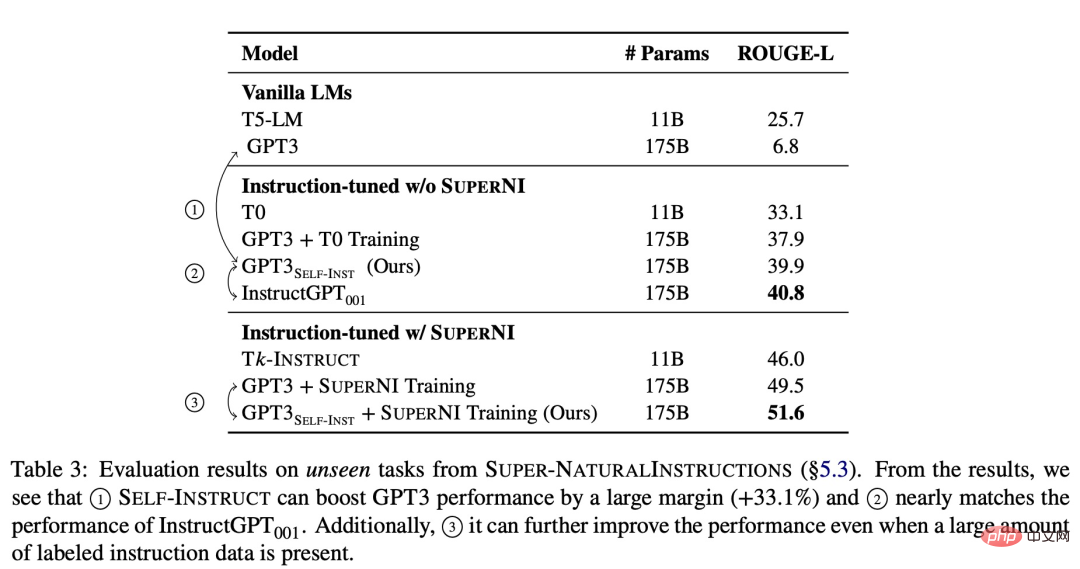
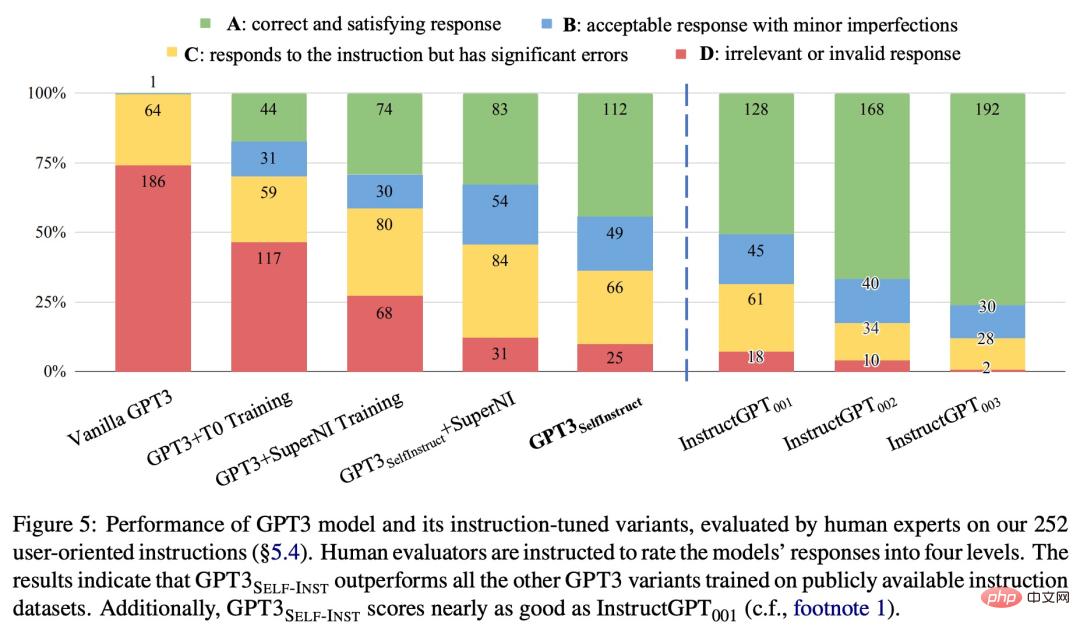
The above is the detailed content of No manual annotation required, the self-generated instruction framework breaks the cost bottleneck of LLMs such as ChatGPT. For more information, please follow other related articles on the PHP Chinese website!
 ChatGPT registration
ChatGPT registration
 Domestic free ChatGPT encyclopedia
Domestic free ChatGPT encyclopedia
 How to install chatgpt on mobile phone
How to install chatgpt on mobile phone
 Can chatgpt be used in China?
Can chatgpt be used in China?
 How to insert page numbers in ppt
How to insert page numbers in ppt
 How to distinguish whether two addresses are on the same site?
How to distinguish whether two addresses are on the same site?
 What is the customer service phone number of Meituan Food Delivery?
What is the customer service phone number of Meituan Food Delivery?
 The difference between large function and max function
The difference between large function and max function
 What is the function of frequency divider
What is the function of frequency divider








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



