
 Technology peripherals
AI
Deep learning has a new pitfall! The University of Sydney proposes a new cross-modal task, using text to guide image cutout
Technology peripherals
AI
Deep learning has a new pitfall! The University of Sydney proposes a new cross-modal task, using text to guide image cutout
Deep learning has a new pitfall! The University of Sydney proposes a new cross-modal task, using text to guide image cutout

Image cutout refers to extracting the accurate foreground in the image. Current automatic methods tend to extract all salient objects in an image indiscriminately. In this paper, the author proposes a new task called Reference Image Matting (RIM), which refers to extracting detailed alpha matting of a specific object, which can best match a given natural language description. . However, popular visual grounding methods are limited to segmentation level, probably due to the lack of high-quality RIM datasets. To fill this gap, the authors established RefMatte, the first large-scale challenging dataset, by designing a comprehensive image synthesis and expression generation engine to generate synthetic images based on the current public high-quality matting prospects, with flexibility logic and relabeled diversified properties.
RefMatte consists of 230 object categories, 47,500 images, 118,749 expression area entities and 474,996 expressions, and can be easily expanded further in the future. In addition, the authors also constructed a real-world test set consisting of 100 natural images using artificially generated phrase annotations to further evaluate the generalization ability of the RIM model. First, RIM tasks in two contexts, prompt-based and expression-based, were defined, and then several typical image matting methods and specific model designs were tested. These results provide empirical insights into the limitations of existing methods as well as possible solutions. It is believed that the new task RIM and the new data set RefMatte will open up new research directions in this field and promote future research.

Paper title: Referring Image Matting
Paper address: https:// arxiv.org/abs/2206.0514 9
Code address : https://github.com/JizhiziLi/RI M
1. Motivation
Image matting refers to extracting soft ahpha matting of the foreground in natural images, which is beneficial to various downstream Applications such as video conferencing, advertising production and e-commerce promotion. Typical matting methods can be divided into two groups: 1) auxiliary input-based methods, such as trimap, and 2) automatic matting methods that extract the foreground without any manual intervention. However, the former is not suitable for automatic application scenarios, and the latter is generally limited to specific object categories, such as people, animals, or all significant objects. How to perform controllable image matting of arbitrary objects, that is, to extract the alpha matting of a specific object that best matches a given natural language description, is still a problem to be explored.
Language-driven tasks such as referring expression segmentation (RES), referring image segmentation (RIS), visual question answering (VQA), and referring expression comprehension (REC) have been widely explored. Great progress has been made in these areas based on many datasets such as ReferIt, Google RefExp, RefCOCO, VGPhraseCut and Cops-Ref. For example, RES methods aim to segment arbitrary objects indicated by natural language descriptions. However, the obtained masks are limited to segmentation levels without fine details due to low-resolution images and coarse mask annotations in the dataset. Therefore, they are unlikely to be used in scenes that require detailed alpha matting of foreground objects.

To fill this gap, the author proposes a new task called "Referring Image Matting (RIM)" in this paper. RIM refers to the extraction of specific foreground objects in an image that best match a given natural language description, along with detailed, high-quality alpha matting. Different from the tasks solved by the above two matting methods, RIM aims at controllable image matting of arbitrary objects in the image indicated by the linguistic description. It has practical significance in the field of industrial applications and opens up new research directions for academia.
To promote RIM research, the author established the first dataset named RefMatte, which consists of 230 object categories, 47,500 images and 118,749 expression area entities and corresponding high-quality alpha matte and 474,996 expressions.
Specifically, in order to construct this dataset, the author first revisited many popular public matting datasets, such as AM-2k, P3M-10k, AIM-500, SIM, and manually labeled them for careful inspection every object. The authors also employ multiple deep learning-based pre-trained models to generate various attributes for each entity, such as human gender, age, and clothing type. The authors then design a comprehensive composition and expression generation engine to generate composite images with reasonable absolute and relative positions, taking into account other foreground objects. Finally, the author proposes several expression logic forms that exploit rich visual attributes to generate different language descriptions. Furthermore, the authors propose a real-world test set RefMatte-RW100, which contains 100 images containing different objects and human annotated expressions, to evaluate the generalization ability of the RIM method. The image above shows some examples.
In order to perform a fair and comprehensive evaluation of the state-of-the-art methods in related tasks, the authors benchmark them on RefMatte in two different settings according to the form of language description, namely a prompt-based setting and an expression-based setting. . Since representative methods are specifically designed for segmentation tasks, there is still a gap when directly applying them to RIM tasks.
In order to solve this problem, the author proposed two strategies to customize them for RIM, namely 1) carefully designed a lightweight cutout header named CLIPmat on top of CLIPSeg to generate high-quality alpha matting results while maintaining its end-to-end trainable pipeline; 2) Several separate coarse image-based matting methods are provided as post-refiners to further improve segmentation/matting results. Extensive experimental results 1) demonstrate the value of the proposed RefMatte dataset for RIM task research, 2) identify the important role of the form of language description; 3) validate the effectiveness of the proposed customization strategy.
The main contributions of this study are threefold. 1) Define a new task called RIM, which aims to identify and extract alpha mattes of specific foreground objects that best match a given natural language description; 2) Establish the first large-scale dataset RefMatte, consisting of 47,500 images Image and 118,749 expression region entities, with high-quality alpha matting and rich expression; 3) Representative state-of-the-art methods were benchmarked in two different settings using two RIM-tailored strategies for RefMatte Tested and gained some useful insights.
2. Method

In this section, the pipeline to build RefMatte (Section 3.1 and Section 3.2) and the task settings (Section 3.3 section) and the statistics of the dataset (section 3.5). The image above shows some examples of RefMatte. Additionally, the authors construct a real-world test set consisting of 100 natural images annotated with manually labeled rich language descriptions (Section 3.4).
2.1 Preparation of matting entities
In order to prepare enough high-quality matting entities to help build the RefMatte dataset, the author revisited the currently available matting datasets to filter out those that meet the requirements prospect. All candidate entities are then manually labeled with their categories and their attributes are annotated using multiple deep learning-based pre-trained models.
Pre-processing and filtering
Due to the nature of the image matting task, all candidate entities should be high-resolution and have clarity in alpha matting and fine details. Additionally, data should be publicly available through open licenses and without privacy concerns to facilitate future research. For these requirements, the authors used all foreground images from AM-2k, P3M-10k and AIM-500. Specifically, for P3M-10k, the authors filter out images with more than two sticky foreground instances to ensure that each entity is associated with only one foreground instance. For other available datasets, such as SIM, DIM, and HATT, the authors filter out those foreground images with identifiable faces among human instances. The authors also filter out those foreground images that are low resolution or have low-quality alpha matting. The final total number of entities was 13,187. For background images used in subsequent synthesis steps, the authors selected all images in BG-20k.
Annotate the category names of entities
Since previous automatic cutout methods tended to extract all salient foreground objects from the image, they did not Entities provide specific (category) names. However, for RIM tasks, the entity name is required to describe it. The authors labeled each entity with an entry-level category name, which represents the most common name people use for a specific entity. Here, a semi-automatic strategy is used. Specifically, the authors use a Mask RCNN detector with a ResNet-50-FPN backbone to automatically detect and label the class name of each foreground instance, and then manually inspect and correct them. RefMatte has a total of 230 categories. In addition, the authors employ WordNet to generate synonyms for each category name to enhance diversity. The authors manually checked synonyms and replaced some of them with more reasonable synonyms.
Annotate the attributes of entities
In order to ensure that all entities have rich visual attributes to support the formation of rich expressions, the author annotated all entities with colors, human entities attributes such as gender, age, and clothing type. The authors also employ a semi-automatic strategy to generate such properties. To generate colors, the authors cluster all pixel values of the foreground image, find the most common values, and match them to specific colors in webcolors. For gender and age, the authors use pre-trained models. Use common sense to define age groups based on predicted age. For clothing types, the author uses a pre-trained model. Furthermore, inspired by foreground classification, the authors add salient or insignificant and transparent or opaque attributes to all entities, since these attributes are also important in image matting tasks. Ultimately, every entity has at least 3 attributes, and human entities have at least 6 attributes.
2.2 Image composition and expression generation
Based on the matting entities collected in the previous section, the author proposed an image synthesis engine and expression generation engine to build the RefMatte data set. How to arrange different entities to form reasonable synthetic images, and at the same time generate semantically clear, grammatically correct, rich, and fancy expressions to describe the entities in these synthetic images, is the key to building RefMatte, and it is also challenging. To this end, the authors define six positional relationships for arranging different entities in synthetic images and utilize different logical forms to produce appropriate expressions.
Image composition engine
In order to maintain the high resolution of entities while arranging them in a reasonable positional relationship, the author uses two or three for each composite image entity. The author defines six positional relationships: left, right, up, down, front, and back. For each relationship, foreground images were first generated and composited via alpha blending with the background image from the BG-20k. Specifically, for the left, right, up, and down relationships, the authors ensure that there are no occlusions in the foreground instances to preserve their details. For before-and-after relationships, occlusion between foreground instances is simulated by adjusting their relative positions. The authors prepare a bag of candidate words to represent each relationship.
Expression generation engine
In order to provide rich expression methods for entities in synthetic images, the author defines three types of expressions for each entity from the perspective of different logical forms defined. Expressions, where 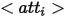 represents attributes,
represents attributes, 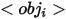 represents category names,
represents category names, 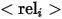 represents the relationship between reference entities and related entities, specific examples of the three expressions are as shown in the figure above (a), (b) and (c) ) shown.
represents the relationship between reference entities and related entities, specific examples of the three expressions are as shown in the figure above (a), (b) and (c) ) shown.
2.3 Dataset split and task settings
Dataset split
The data set has a total of 13,187 matting entities, of which 11,799 are used to build the training set ,1,388 for the test set. However, the categories of the training and test sets are not balanced because most entities belong to the human or animal category. Specifically, among the 11,799 entities in the training set, there are 9,186 humans, 1,800 animals, and 813 objects. In the test set of 1,388 entities, there are 977 humans, 200 animals, and 211 objects. To balance the categories, the authors replicated entities to achieve a 5:1:1 ratio of human:animal:object. Therefore, there are 10,550 humans, 2,110 animals, and 2,110 objects in the training set, and 1,055 humans, 211 animals, and 211 objects in the test set.
To generate images for RefMatte, the authors pick a set of 5 humans, 1 animal, and 1 object from a training or test split and feed them into an image synthesis engine. For each group in the training or test split, the authors generated 20 images to form the training set and 10 images to form the test set. The ratio of the left/right:top/bottom:front/back relationship is set to 7:2:1. The number of entities in each image is set to 2 or 3. For context, the authors always choose 2 entities to maintain high resolution for each entity. After this process, there are 42,200 training images and 2,110 test images. To further enhance the diversity of entity combinations, we randomly select entities and relationships from all candidates to form another 2800 training images and 390 testing images. Finally, there are 45,000 synthetic images in the training set and 2,500 images in the test set.
Task setting
To benchmark RIM methods given different forms of language description, the authors set up two settings in RefMatte:
Prompt-based settin: The text description in this setting is a prompt, which is the entry-level category name of the entity. For example, the prompts in the picture above are flower, human, and alpaca;
Expression-based setting: The text description in this setting is the expression generated in the previous section, selected from basic expressions, absolute position expressions and relative position expressions. Some examples can also be seen in the image above.
2.4 Real-world test set

#Since RefMatte is built on synthetic images, there may be domain gaps between them and real-world images. In order to study the generalization ability of the RIM model trained on it to real-world images, the author further established a real-world test set named RefMatte-RW100, which consists of 100 real-world high-resolution images. Each image There are 2 to 3 entities in . The authors then annotate their expressions following the same three settings in Section 3.2. Additionally, the author added a free expression in the annotation. For high-quality alpha cutout tags, the author generates them using image editing software such as Adobe Photoshop and GIMP. Some examples of RefMatte-RW100 are shown above.
2.5 Statistics of the RefMatte dataset and RefMatte-RW100 test set
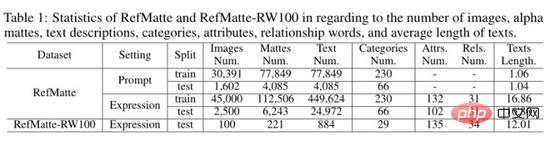
The author calculated the statistics of the RefMatte dataset and RefMatte-RW100 test set as shown in the table above. For the prompt-based setting, since the text descriptions are entry-level category names, the authors remove images with multiple entities belonging to the same category to avoid ambiguous inferences. Therefore, in this setting, there are 30,391 images in the training set and 1,602 images in the test set. The number, text description, categories, attributes and relationships of alpha cutouts are shown in the table above respectively. In the prompt-based setting, the average text length is about 1, since there is usually only one word per category, while in the expression-based setting it is much larger, i.e. about 16.8 in RefMatte and about 16.8 in RefMatte-RW100 is 12.

#The author also generated a word cloud of prompts, properties, and relationships in RefMatte in the image above. As can be seen, the dataset has a large portion of humans and animals since they are very common in image matting tasks. The most common attributes in RefMatte are masculine, gray, transparent, and salient, while relational words are more balanced.
3. Experiment
Due to the task differences between RIM and RIS/RES, the results of directly applying the RIS/RES method to RIM are not optimistic. To solve this problem, the author proposes two strategies to customize them for RIM:
1) Adding matting heads: Design lightweight matting heads on top of existing models to generate high-quality alpha matting , while maintaining an end-to-end trainable pipeline. Specifically, the author designed a lightweight matting decoder on top of CLIPSeg, called CLIPMat;
2) Using matting refiner: The author uses a separate matting method based on coarse images as the backend refiner to further improve the segmentation/matting results of the above methods. Specifically, the authors train GFM and P3M, inputting images and coarse images as cutout refiners.
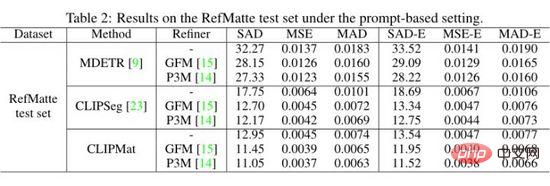
The authors evaluate MDETR, CLIPSeg, and CLIPMat on a hint-based setting on the RefMatte test set and present the quantitative results in the table above. It can be seen that compared with MDETR and CLIPSeg, CLIPMat performs best regardless of whether the cutout refiner is used or not. Verify the effectiveness of adding a cutout header to customize CLIPSeg for RIM tasks. Furthermore, using either of the two cutout refiners can further improve the performance of the three methods.
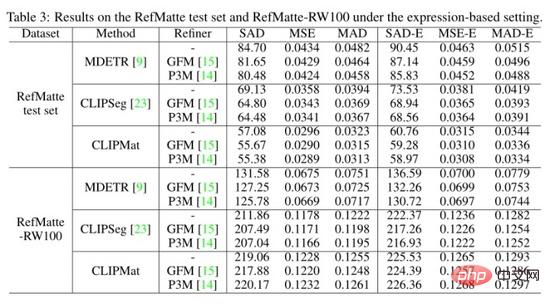
The authors also evaluated the three methods under expression-based settings on the RefMatte test set and RefMatte-RW100 and show the quantitative results in the table above. CLIPMat again shows good ability to preserve more details on the RefMatte test set. Single-stage methods like CLIPSeg and CLIPMat lag behind the two-stage method, namely MDETR, when tested on RefMatte-RW100, possibly due to the better ability of MDETR's detectors to understand cross-modal semantics.
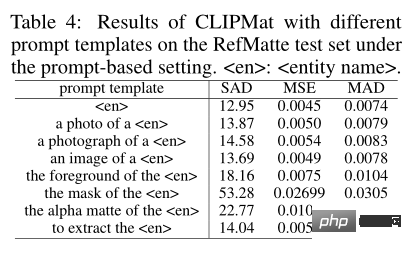
#To investigate the impact of prompt input form, the authors evaluated the performance of different prompt templates. In addition to the traditional templates used, the author has also added more templates specifically designed for image matting tasks, such as the foreground/mask/alpha matte of
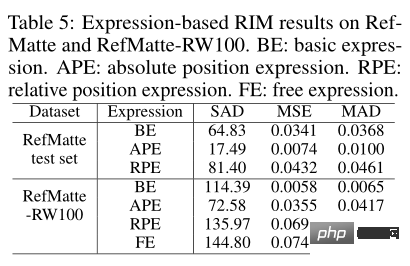
Since this article introduces different types of expressions in the task, you can see the impact of each type on matting performance. As shown in the table above, the best performing model CLIPMat was tested on the RefMatte test set and the model MDETR was tested on RefMatte-RW100.
4. Summary
In this paper, we propose a new task called Reference Image Matting (RIM) and build a large-scale dataset RefMatte. The authors tailor existing representative methods on relevant tasks of RIM and measure their performance through extensive experiments on RefMatte. The experimental results of this paper provide useful insights into model design, the impact of text descriptions, and the domain gap between synthetic and real images. RIM research can benefit many practical applications such as interactive image editing and human-computer interaction. RefMatte can facilitate research in this area. However, the synthetic-to-real domain gap may result in limited generalization to real-world images.
The above is the detailed content of Deep learning has a new pitfall! The University of Sydney proposes a new cross-modal task, using text to guide image cutout. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
