
 Technology peripherals
AI
Human beings do not have enough high-quality corpus for AI to learn, and they will be exhausted in 2026. Netizens: A large-scale human text generation project has been launched!
Technology peripherals
AI
Human beings do not have enough high-quality corpus for AI to learn, and they will be exhausted in 2026. Netizens: A large-scale human text generation project has been launched!
Human beings do not have enough high-quality corpus for AI to learn, and they will be exhausted in 2026. Netizens: A large-scale human text generation project has been launched!

AI’s appetite is too big, and human corpus data is no longer enough.
A new paper from the Epoch team shows that AI will use up all high-quality corpus in less than 5 years.

You must know that this is a predicted result taking into account the growth rate of human language data. In other words, the number of newly written papers and newly edited books by humans in recent years Even if all the codes are fed to AI, it will not be enough.
If this development continues, large language models that rely on high-quality data to improve their level will soon face a bottleneck.
Some netizens can’t sit still:
This is ridiculous. Humans can train themselves effectively without reading everything on the Internet.
We need better models, not more data.
Some netizens ridiculed that it is better to let the AI eat its own vomit:
You can generate the AI itself Text is fed to AI as low-quality data.

#Let’s take a look, how much data is left by humans?
How about "inventory" of text and image data?
The paper mainly predicts text and image data.
The first is text data.
The quality of data usually ranges from good to bad. The authors divided the available text data into low-quality and high-quality parts based on the data types used by existing large models and other data.
High-quality corpus refers to the training data sets used by large language models such as Pile, PaLM and MassiveText, including Wikipedia, news, code on GitHub, published books, etc.
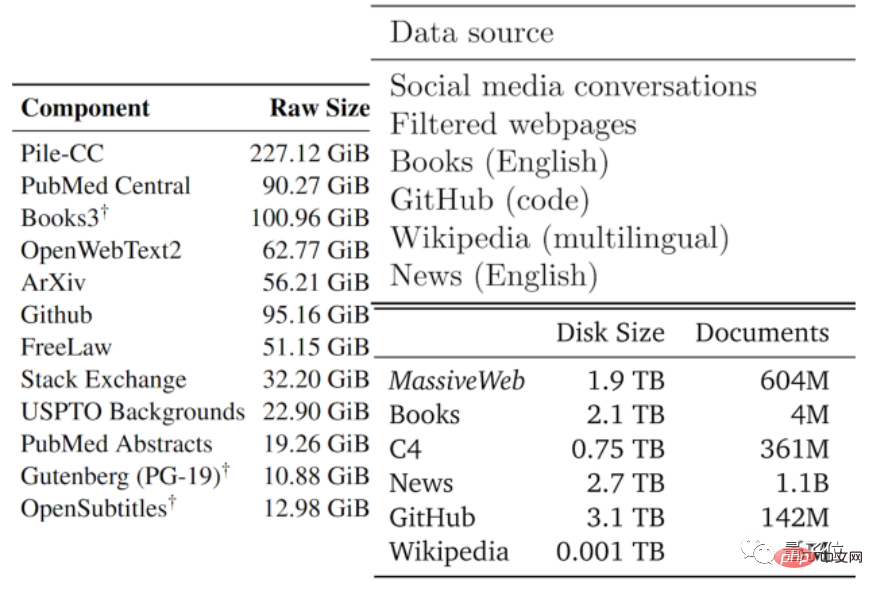
Low-quality corpus comes from tweets on social media such as Reddit, as well as unofficial fan fiction (fanfic).
According to statistics, there are only about 4.6×10^12~1.7×10^13 words left in the high-quality language data stock, which is less than an order of magnitude larger than the current largest text data set.
Combined with the growth rate, the paper predicts that high-quality text data will be exhausted by AI between 2023 and 2027, and the estimated node is around 2026.
It seems a bit fast...
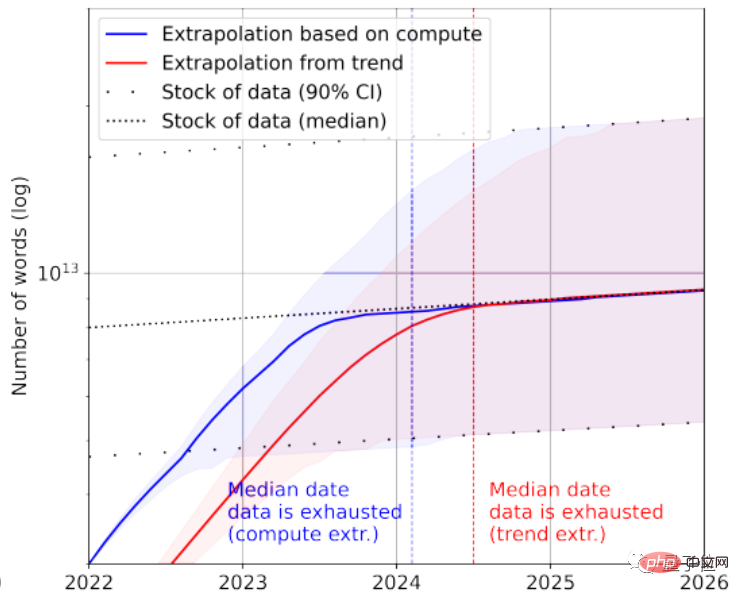
Of course, low-quality text data can be added to the rescue. According to statistics, there are currently 7×10^13~7×10^16 words left in the overall stock of text data, which is 1.5~4.5 orders of magnitude larger than the largest data set.
If the requirements for data quality are not high, then AI will use up all text data between 2030 and 2050.
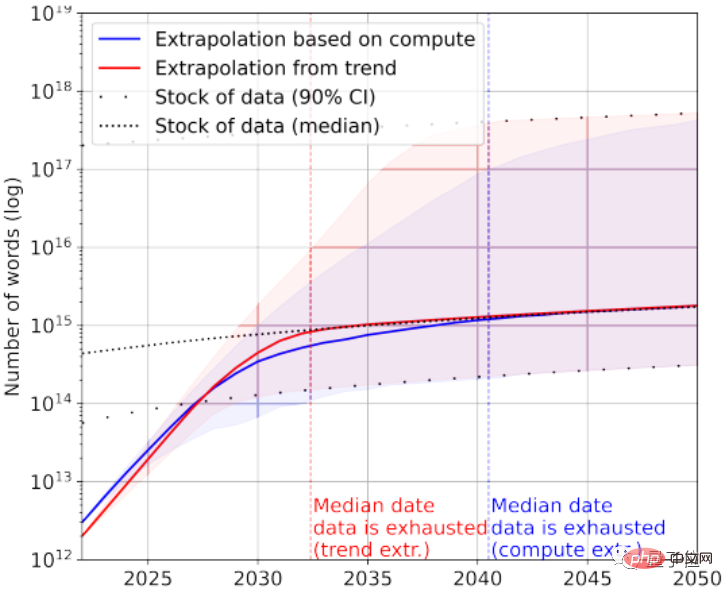
Looking at the image data again, the paper here does not differentiate between image quality.
The largest image data set currently has 3×10^9 pictures.
According to statistics, the current total number of images is about 8.11×10^12~2.3×10^13, which is 3~4 orders of magnitude larger than the largest image data set.
The paper predicts that AI will run out of these images between 2030 and 2070.
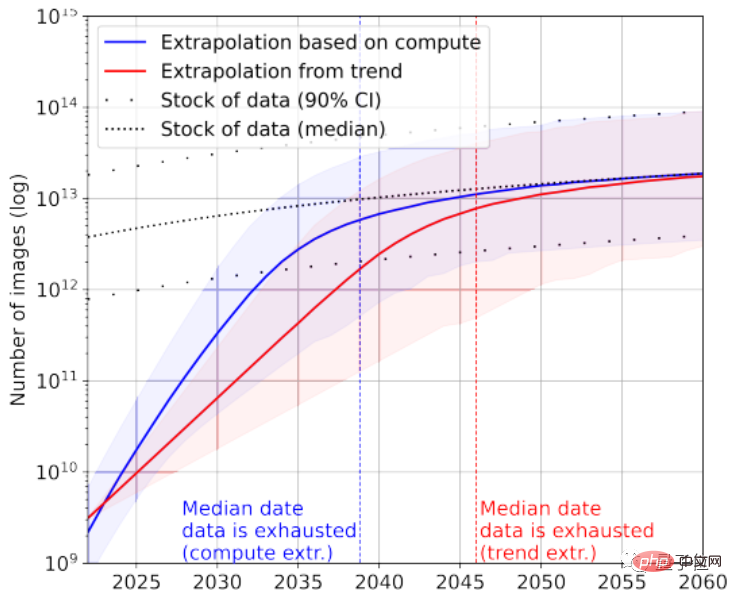
Obviously, large language models face a more serious "lack of data" situation than image models.
So how is this conclusion drawn?
Calculate the average daily number of posts posted by netizens and get the result
The paper analyzes the text image data generation efficiency and the growth of the training data set from two perspectives.
It is worth noting that the statistics in the paper are not all labeled data. Considering that unsupervised learning is relatively popular, unlabeled data is also included.
Take text data as an example. Most of the data will be generated from social platforms, blogs and forums.
To estimate text data generation speed, there are three factors to consider, namely the total population, Internet penetration rate, and the average amount of data generated by Internet users.
For example, this is the estimated future population and Internet user growth trend based on historical population data and the number of Internet users:
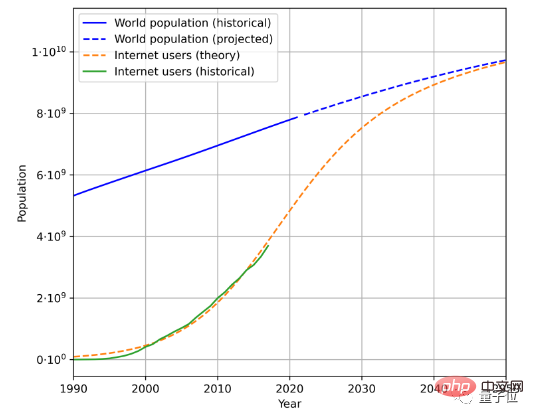
combined with user-generated By averaging the amount of data, the rate at which data is generated can be calculated. (Due to complex geographical and time changes, the paper simplifies the calculation method of the average amount of data generated by users)
According to this method, the growth rate of language data is calculated to be around 7%. However, this growth rate will increase with Gradually decreases over time.
It is expected that by 2100, the growth rate of our language data will drop to 1%.
A similar method is used to analyze image data. The current growth rate is about 8%. However, by 2100, the growth rate of image data will also slow down to about 1%.
The paper believes that if the data growth rate does not increase significantly, or new data sources emerge, whether it is an image or a large text model trained with high-quality data, it may usher in a bottleneck period at a certain stage.
Some netizens ridiculed that something like a sci-fi storyline might happen in the future:
In order to train AI, humans have started large-scale text generation projects, and everyone is writing hard for AI.
He calls it an “education for AI”:
We send 140,000 to 2.6 million words to AI every year Amounts of text data, sounds cooler than using humans as batteries?
What do you think?
Paper address: https://arxiv.org/abs/2211.04325
Reference link: https://twitter.com/emollick/status/1605756428941246466
The above is the detailed content of Human beings do not have enough high-quality corpus for AI to learn, and they will be exhausted in 2026. Netizens: A large-scale human text generation project has been launched!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Share an easy way to package PyCharm projects
Dec 30, 2023 am 09:34 AM
Share an easy way to package PyCharm projects
Dec 30, 2023 am 09:34 AM
Share the simple and easy-to-understand PyCharm project packaging method. With the popularity of Python, more and more developers use PyCharm as the main tool for Python development. PyCharm is a powerful integrated development environment that provides many convenient functions to help us improve development efficiency. One of the important functions is project packaging. This article will introduce how to package projects in PyCharm in a simple and easy-to-understand way, and provide specific code examples. Why package projects? Developed in Python
 Can AI conquer Fermat's last theorem? Mathematician gave up 5 years of his career to turn 100 pages of proof into code
Apr 09, 2024 pm 03:20 PM
Can AI conquer Fermat's last theorem? Mathematician gave up 5 years of his career to turn 100 pages of proof into code
Apr 09, 2024 pm 03:20 PM
Fermat's last theorem, about to be conquered by AI? And the most meaningful part of the whole thing is that Fermat’s Last Theorem, which AI is about to solve, is precisely to prove that AI is useless. Once upon a time, mathematics belonged to the realm of pure human intelligence; now, this territory is being deciphered and trampled by advanced algorithms. Image Fermat's Last Theorem is a "notorious" puzzle that has puzzled mathematicians for centuries. It was proven in 1993, and now mathematicians have a big plan: to recreate the proof using computers. They hope that any logical errors in this version of the proof can be checked by a computer. Project address: https://github.com/riccardobrasca/flt
 Quantile regression for time series probabilistic forecasting
May 07, 2024 pm 05:04 PM
Quantile regression for time series probabilistic forecasting
May 07, 2024 pm 05:04 PM
Do not change the meaning of the original content, fine-tune the content, rewrite the content, and do not continue. "Quantile regression meets this need, providing prediction intervals with quantified chances. It is a statistical technique used to model the relationship between a predictor variable and a response variable, especially when the conditional distribution of the response variable is of interest When. Unlike traditional regression methods, quantile regression focuses on estimating the conditional magnitude of the response variable rather than the conditional mean. "Figure (A): Quantile regression Quantile regression is an estimate. A modeling method for the linear relationship between a set of regressors X and the quantiles of the explained variables Y. The existing regression model is actually a method to study the relationship between the explained variable and the explanatory variable. They focus on the relationship between explanatory variables and explained variables
 A closer look at PyCharm: a quick way to delete projects
Feb 26, 2024 pm 04:21 PM
A closer look at PyCharm: a quick way to delete projects
Feb 26, 2024 pm 04:21 PM
Title: Learn more about PyCharm: An efficient way to delete projects. In recent years, Python, as a powerful and flexible programming language, has been favored by more and more developers. In the development of Python projects, it is crucial to choose an efficient integrated development environment. As a powerful integrated development environment, PyCharm provides Python developers with many convenient functions and tools, including deleting project directories quickly and efficiently. The following will focus on how to use delete in PyCharm
 PyCharm Practical Tips: Convert Project to Executable EXE File
Feb 23, 2024 am 09:33 AM
PyCharm Practical Tips: Convert Project to Executable EXE File
Feb 23, 2024 am 09:33 AM
PyCharm is a powerful Python integrated development environment that provides a wealth of development tools and environment configurations, allowing developers to write and debug code more efficiently. In the process of using PyCharm for Python project development, sometimes we need to package the project into an executable EXE file to run on a computer that does not have a Python environment installed. This article will introduce how to use PyCharm to convert a project into an executable EXE file, and give specific code examples. head
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 How to Make a Shopping List in the iOS 17 Reminders App on iPhone
Sep 21, 2023 pm 06:41 PM
How to Make a Shopping List in the iOS 17 Reminders App on iPhone
Sep 21, 2023 pm 06:41 PM
How to Make a GroceryList on iPhone in iOS17 Creating a GroceryList in the Reminders app is very simple. You just add a list and populate it with your items. The app automatically sorts your items into categories, and you can even work with your partner or flat partner to make a list of what you need to buy from the store. Here are the full steps to do this: Step 1: Turn on iCloud Reminders As strange as it sounds, Apple says you need to enable reminders from iCloud to create a GroceryList on iOS17. Here are the steps for it: Go to the Settings app on your iPhone and tap [your name]. Next, select i
 How to use MySQL database for forecasting and predictive analytics?
Jul 12, 2023 pm 08:43 PM
How to use MySQL database for forecasting and predictive analytics?
Jul 12, 2023 pm 08:43 PM
How to use MySQL database for forecasting and predictive analytics? Overview: Forecasting and predictive analytics play an important role in data analysis. MySQL, a widely used relational database management system, can also be used for prediction and predictive analysis tasks. This article will introduce how to use MySQL for prediction and predictive analysis, and provide relevant code examples. Data preparation: First, we need to prepare relevant data. Suppose we want to do sales forecasting, we need a table with sales data. In MySQL we can use
