
 Technology peripherals
AI
Li Feifei takes stock of the top ten AI highlights of the year: nuclear fusion, ChatGPT, and AlphaFold are on the list
Technology peripherals
AI
Li Feifei takes stock of the top ten AI highlights of the year: nuclear fusion, ChatGPT, and AlphaFold are on the list
Li Feifei takes stock of the top ten AI highlights of the year: nuclear fusion, ChatGPT, and AlphaFold are on the list

The explosion of artificial intelligence is distorting our sense of time.
Can you believe that Stable Diffusion is only 4 months old and ChatGPT has been around for less than a month?
To use a vivid metaphor, as long as you blink, you will miss a brand new industry.
In the AI field in 2022, large-scale generative models have sprung up like mushrooms after a rain, changing the landscape of the entire AI industry.
Moreover, these models are rapidly moving out of the laboratory and being applied in reality.
For example, LLM technology has inspired two emerging fields-decision-making agents (games, robots, etc.) and AI4Science.
Jim Fan, a disciple of Li Feifei, summarized the top ten AI highlight moments in 2022 for us. Let’s turn back the clock and see what amazing AI breakthroughs there will be in 2022.
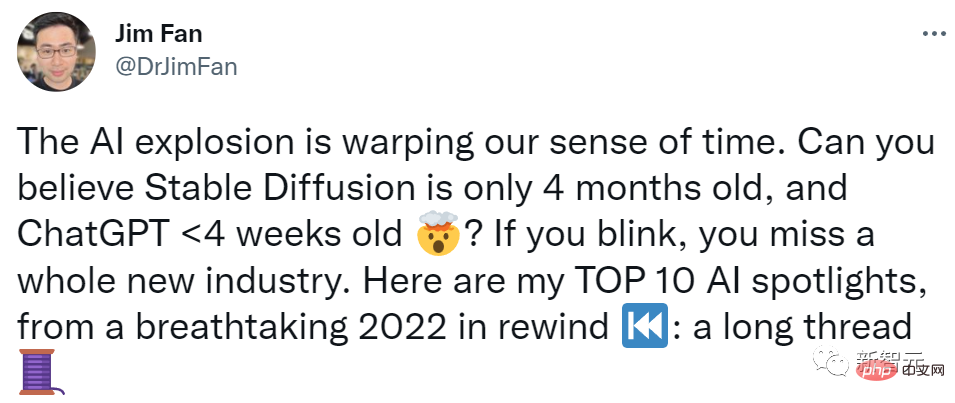
1. Text-image generation
DALLE-2 is the first to generate realistic high-resolution images from any title Large-scale diffusion models for images.
It launched an artistic revolution in AI, spawning many new applications, startups, and ways of thinking.
But DALLE-2 is protected behind the walls of OpenAI and is not open source.
After OpenAI, LMU's StabilityAI and runwayml took a heroic step and trained their own Internet-scale text2image model based on the "potential diffusion" algorithm. They call the model "stable diffusion" and open source the code and weights.

Facts have proved that the openness of Stable Diffusion has brought great changes to the game.
Now, many startups and research labs are creating new applications based on Stable Diffusion, and Stable Diffusion itself is continuously improved by the open source community.
Recently, Stable Diffusion has reached v2.1 and can run on a single GPU.
In addition, there are two image2text models from GoogleAI this year. GoogleAI has neither released the model nor the API, but from the paper, we can still see many interesting insights.
Imagen
https://imagen.research.google

Parti
https://parti.research.google. It is a Transformer model without diffusion.

2. Text-text generation
As everyone knows, I am talking about ChatGPT!
This is the only app in history to gain 1 million users in 5 days.
ChatGPT has also greatly inspired our human creativity.
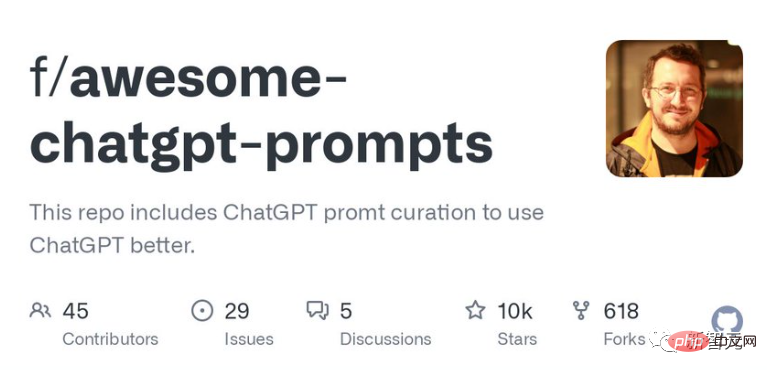
In this list, you can see all useful and imaginative ideas about ChatGPT: https://github.com/f/awesome-chat
Both ChatGPT and GPT-3.5 use a new technology called RLHF ("Reinforcement Learning from Human Feedback").
This also means that the prompt project may disappear soon.

The popularity of ChatGPT has spawned a wave of new startups and competitors, such as Jasper Chat, YouChat, Replit’s Ghostwriter chat, and perplexity_ai.
These competitors provide such intuitive search methods that even Google executives are starting to sweat!

3. Text-Robot Model
How to give GPT arms and legs so they can clean your messy kitchen?
Unlike NLP, robot models need to interact with the physical world.
This year, the large pre-trained Transformer finally began to solve the most difficult problems in the field of robotics!
VIMA
In October, my colleagues and I Created a "robot GPT" - a transformer named VIMA.
It can receive any mixed text, images and videos as prompts and output the control of the robot arm.
Our model is called VIMA ("VisuoMotor Attention") and is completely open source.
Now, a single agent can solve visual targets, one-time imitation of videos, new concept foundations, visual constraints, etc., with strong scalability of model capacity and data.
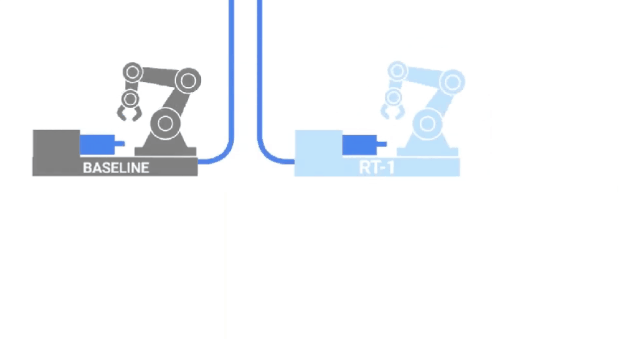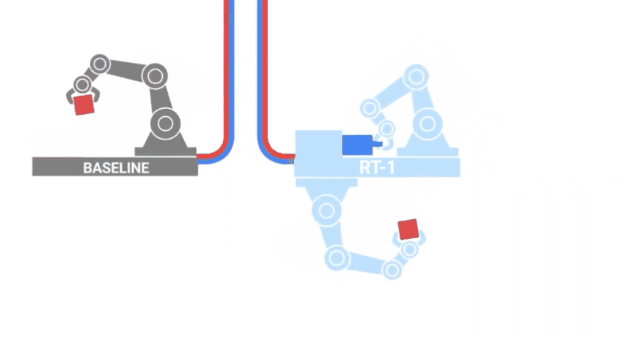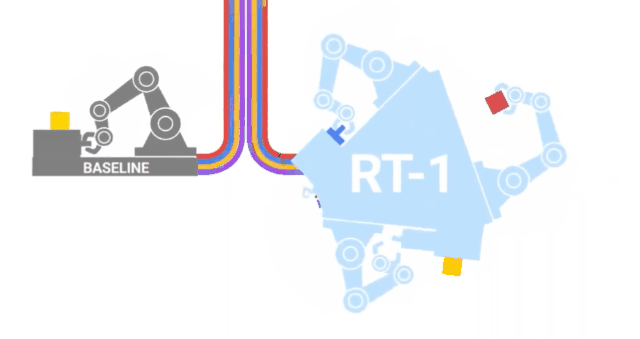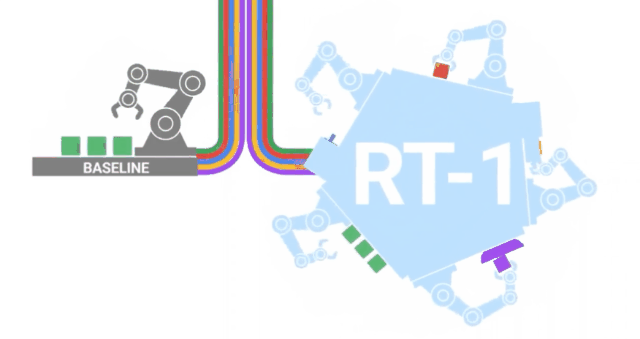
RT-1
Following a similar path to VIMA, researchers from GoogleAI released RT-1, a Robot transformer trained on 700 tasks and 130K human demonstrations.
This data was collected over 17 months by 13 robots, a literal army of steel!
4. Text-Video
Essentially, a video is a series of images tied together over time, giving us Creates the illusion of movement.
If we can do text2image, why not add a timeline to it for some extra fun?
Currently, there are three major works in the text-to-video field, but none of them are open source.
Make-A-Video
The first is Meta AI’s Make-A-Video: No need for paired text-video data, you can get text-video of generation.
You can sign up for trial access here: https://makeavevideo.studio

Paper link: https://arxiv.org/abs /2209.14792


Phenaki
Phenaki from Google AI: Generating variable-length videos from open-domain text descriptions. Demo: https://phenaki.video
DreamFusion
The first to appear is DreamFusion jointly developed by the Google AI research team and UC Berkeley.

Magic3D
The second result is two projects of the NVIDIA AI team, named GET3D and Magic3D.


Point-E
After the DALL-E 2 launched at the beginning of the year surprised everyone with its genius brush, OpenAI released its latest image generation model "POINT-E" on Tuesday , which can generate 3D models directly from text.
So, can AI use its imagination as much as humans can?

Jim Fan and colleagues collaborated to develop the first AI to play "Minecraft", "MineDojo", which can solve many tasks under natural language prompts.

Paper link: https://arxiv.org/pdf/2206.08853.pdf
Fan’s ultimate goal is to build an “embodied ChatGPT” . Currently, the MineDojo platform is completely open source.
At the same time, Jeff Clune’s team announced a model called Video Pre-Training (VPT), which can directly output keyboard and mouse movements.

Paper link: https://arxiv.org/pdf/2206.11795.pdf
VPT has a broader perspective, But it is not restricted by language conditions. At this point, MineDojo and VPT complement each other.





References:
https://twitter.com/drjimfan/status/1607746957753057280?s=46&t=OVM_4zdRW2rQwqLohMdPpw
The above is the detailed content of Li Feifei takes stock of the top ten AI highlights of the year: nuclear fusion, ChatGPT, and AlphaFold are on the list. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
The steps to draw a Bitcoin structure analysis chart include: 1. Determine the purpose and audience of the drawing, 2. Select the right tool, 3. Design the framework and fill in the core components, 4. Refer to the existing template. Complete steps ensure that the chart is accurate and easy to understand.
 What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
Suggestions for choosing a cryptocurrency exchange: 1. For liquidity requirements, priority is Binance, Gate.io or OKX, because of its order depth and strong volatility resistance. 2. Compliance and security, Coinbase, Kraken and Gemini have strict regulatory endorsement. 3. Innovative functions, KuCoin's soft staking and Bybit's derivative design are suitable for advanced users.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
