

How to solve Java Spring Boot distributed transaction problem

1. What is reverse compensation
First of all, let me explain a term to you. When you look at information related to distributed transactions, you will often see a term: Reverse compensation. What is reverse compensation?
Let me give you an example: Suppose we now have three microservices, A, B, and C. Now we call B and C services respectively in A service. In order to ensure that B and C succeed or fail at the same time, we Distributed transactions are required. But according to our previous understanding of local transactions, for local transactions in B and C, after the transaction in service B is completed and submitted, the transaction in service C now has an exception and needs to be rolled back. However, B has already submitted it. How to roll back?
The rollback we are talking about at this time is not in the traditional sense, the kind of rollback through the MySQL redo log. It is through an update SQL, and then the changes in the B service are data recovery.
This is what we call reverse compensation!
2. Basic concept review
There are three core concepts in Seata:
TC (Transaction Coordinator) - Transaction coordination Author: Maintain the status of global and branch transactions, and drive global transaction submission or rollback.
TM (Transaction Manager) - Transaction Manager: Define the scope of the global transaction, start the global transaction, commit or roll back the global transaction.
RM (Resource Manager) - Resource Manager: manages the resources (Resource) for branch transaction processing, talks to TC to register branch transactions and report the status of branch transactions, and drives branch transactions Commit or rollback.
Among them, TC is a separately deployed Server, and TM and RM are Clients embedded in the application.
Let’s look at the following picture:
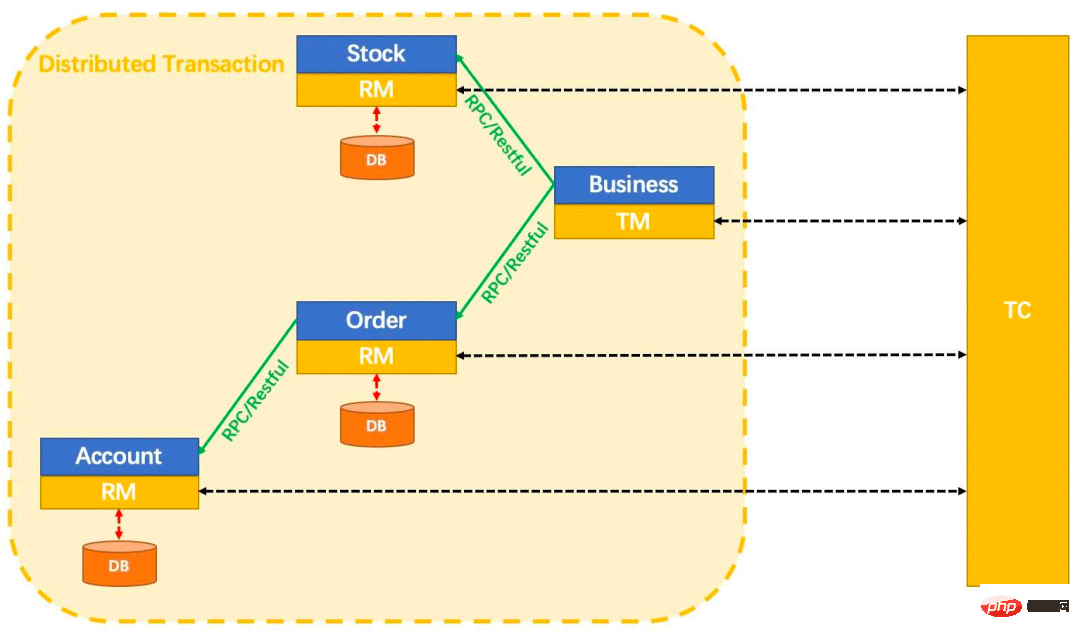
This picture basically explains these three concepts clearly.
In fact, without looking at this picture, we can probably guess the implementation principle of distributed transactions: first there must be a global transaction coordinator (TC), and each local transaction (RM) starts executing , or during the execution process, promptly report its status to the global transaction coordinator. This global transaction coordinator knows the current execution status of each branch transaction. When he (TC) finds that all local transactions have been executed successfully, , he notifies everyone to commit together; when he finds that someone fails to execute this transaction, he notifies everyone to roll back together (of course, this rollback is not necessarily a true rollback, but a reverse compensation). So when does a transaction start and end? That is, where are the boundaries of the transaction? Distributed transactions in seata are implemented through the @GlobalTransactional annotation. In other words, where should this annotation be added? The place to add this annotation is actually the transaction manager TM.
After the above introduction, friends should understand that using Seata to implement distributed transactions is not as difficult as imagined, and the principle is still very easy.
Seata involves four different modes. The four different modes introduced next are actually talking about how to roll back when a local transaction fails? These are the four different distributed transaction modes we will talk about later.
3. What is two-stage submission
First look at the following picture:

This picture involves three concepts:
AP: Needless to say, AP is the application itself.
RM: RM is the resource manager, which is the participant of the transaction. In most cases, it refers to the database. A distributed transaction often involves multiple RM.
TM: TM is the transaction manager, which creates distributed transactions and coordinates the execution and status of each sub-transaction in the distributed transaction. Sub-transactions refer to the Specific operations performed on the RM.
So what is Two-Phase Commit (2PC for short) submission?
The truth of two-stage submission is very simple. Brother Song will give you a simple example to explain the two-stage submission:
For example, the following picture:
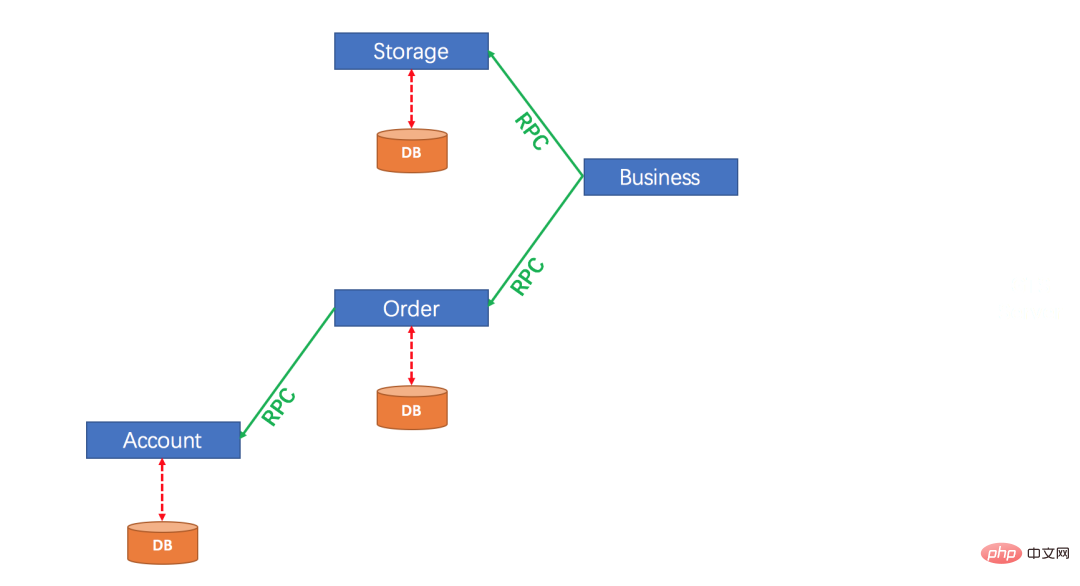
We call Storage, Order, and Account respectively in Business. The operations in these three must succeed or fail at the same time. However, since these three points are in different services, we only You can first let the operations in these three services be executed separately, and the transactions in the three services be executed separately, which is the first phase of the two phases.
After the first phase of execution is completed, do not rush to submit, because some of the three services may have failed to execute. At this time, the three services need to report the execution results of their first phase to a transaction coordinator. After the transaction coordinator receives the message, if the first phase of the three services is successfully executed, the three transactions will be notified to submit respectively. If any of the three services fails to execute, the three transactions will be notified at this time. Roll back separately.
This is the so-called two-phase commit.
To summarize: In two-phase submission, the transaction is divided into participants (such as each specific service in the figure above) and the coordinator. The participants will notify the coordinator of the success or failure of the operation, and then the coordinator will determine the success or failure of the operation based on the results of all participants. The feedback information determines whether each participant should submit the operation or abort the operation. The participant here can be understood as RM, and the coordinator can be understood as TM.
However, various distributed transaction modes in Seata are basically evolved on the basis of two-phase submission, so they are not exactly the same. This needs to be paid attention to by friends.
4. AT mode
AT mode is a fully automatic transaction rollback mode.
Overall, the AT mode is an evolution of the two-phase commit protocol:
One phase: business data and rollback log records are submitted in the same local transaction, Release local locks and connection resources.
The second phase is divided into two situations: 2.1 Submit asynchronously, which is completed very quickly. 2.2 Rollback performs reverse compensation through a one-stage rollback log.
The general logic is as above. Let’s look at how the AT mode works through a specific case:
Assume there is a business table product, as follows:
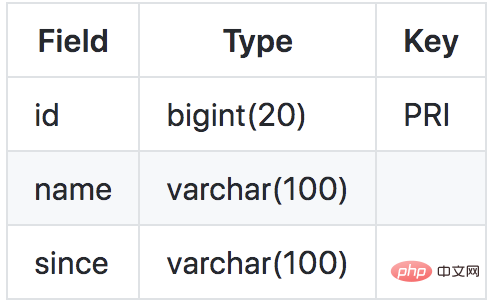
Now we want to do the following update operation:
update product set name = 'GTS' where name = 'TXC';
The steps are as follows:
First stage:
Parse SQL: get the SQL type (UPDATE), table (product), condition (where name = 'TXC') and other related information.
Pre-query image: Based on the conditional information obtained through parsing, generate a query statement and locate the data (find the data before the update).
Execute the above update SQL.
Query post-mirror: Based on the results of the pre-mirror, locate the data through primary key.
Insert rollback log: Combine the before and after mirror data and business SQL-related information into a rollback log record, and insert it into the UNDO_LOG table.
Before submitting, register the branch with TC: apply for a global lock for the record with the primary key value equal to 1 in the product table.
Local transaction submission: The update of business data is submitted together with the UNDO LOG generated in the previous step.
Report the result of local transaction submission to TC.
Second phase:
The second phase is divided into two situations, commit or rollback.
Let’s look at the rollback steps first:
First, receive the branch rollback request from TC, start a local transaction, and perform the following operations.
Find the corresponding UNDO LOG record through XID and Branch ID (this record stores the corresponding images before and after the data modification).
Data verification: Compare the post-image in the UNDO LOG with the current data. If there is a difference, it means that the data has been modified by actions other than the current global transaction. This situation needs to be handled according to the configuration policy.
Generate and execute rollback statements based on the relevant information of the previous image and business SQL in UNDO LOG:
update product set name = 'TXC' where id = 1;Commit local transaction. And report the execution result of the local transaction (that is, the result of branch transaction rollback) to TC.
Let’s look at the submission steps:
Receive the branch submission request from TC and put the request into an asynchronous task queue, and immediately returns the result of successful submission to TC.
Branch submission requests in the asynchronous task phase will delete the corresponding UNDO LOG records asynchronously and in batches.
This is roughly the same step. The idea is relatively clear. When you want to update a record, the system generates a JSON for the content before and after the update of the record. And store it in the undo log table. If you want to roll back in the future, update the data according to the records in the undo log (reverse compensation). If you don't want to roll back in the future, delete the records in the undo log.
In the entire process, developers only need to create an additional undo log table, and then add @GlobalTransactional annotations where global transactions need to be processed.
Other submissions, rollbacks and rollbacks are all fully automatic, which is easier to do. So if you choose to use seata to handle distributed transactions in your project, the probability of using AT mode is still quite high.
5. TCC mode
TCC (Try-Confirm-Cancel) mode has a bit of a manual feel. It is also two-stage, but it is different from AT. Let’s take a look. process.
There is a flow chart of TCC on the official website. Let’s take a look:
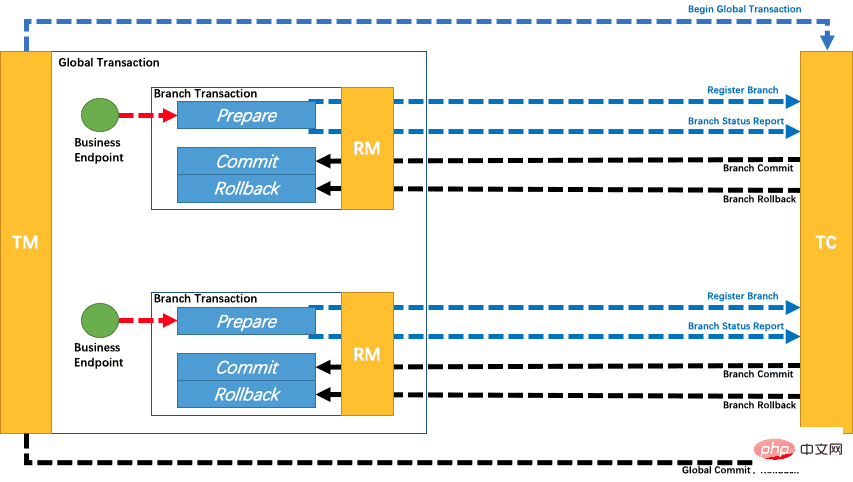
As you can see, TCC is also divided into two stage:
The first stage is prepare. At this stage, it mainly does the detection and reservation of resources, such as bank transfers. At this stage, we first check whether the user's money is enough. If it is not enough, we just throw it away. If it's abnormal, freeze it first if it's enough.
The second stage is commit or rollback. This is mainly to wait for the first stage of each branch transaction to be completed. After all executions are completed, each will report its own situation to TC, and TC will make statistics. If TC finds that there are no exceptions in each branch transaction, it will notify everyone to submit it together; if TC finds that a branch transaction is abnormal, it will notify everyone to roll back.
Then your friends may also have discovered that the above process involves a total of three methods, prepare, commit and rollback. These three methods are completely user-defined methods. , we need to implement it ourselves, so I said from the beginning that TCC is a manual mode.
Compared with AT, everyone found that the TCC mode actually does not depend on the transaction support of the underlying database. In other words, it does not matter even if your underlying database does not support transactions. Anyway, prepare, commit and rollback are three All methods are written by the developers themselves. We can just smooth out the processes corresponding to these three methods.
6.
XA specification is a distributed transaction processing (DTP, Distributed Transaction Processing) standard defined by the X/Open organization.
The XA specification describes the interface between the global transaction manager and the local resource manager. The purpose of the XA specification is to allow multiple resources (such as databases, application servers, message queues, etc.) to be accessed in the same transaction, so that
ACIDproperties remain valid across applications. The XA specification uses two-phase commit to guarantee that all resources commit or rollback any particular transaction at the same time.
The XA specification was proposed in the early 1990s. Currently, almost all mainstream databases provide support for the XA specification.
XA transactions are based on the two-phase commit protocol. A transaction coordinator is needed to ensure that all transaction participants have completed the preparation work (first phase). If the coordinator receives a message that all participants are ready for, it will notify that all transactions can be committed (phase 2). MySQL plays the role of a participant in this XA transaction, not the coordinator (transaction manager).
MySQL's XA transactions are divided into internal XA and external XA. External XA can participate in external distributed transactions and requires the application layer to intervene as a coordinator; internal XA transactions are used for cross-engine transactions under the same instance, with Binlog as the coordinator. For example, when a storage engine commits, the commit needs to be Information is written to the binary log, which is a distributed internal XA transaction, except that the participant in the binary log is MySQL itself. MySQL plays the role of a participant in XA transactions, not a coordinator.
In other words, MySQL can naturally implement distributed transactions through the XA specification, but it only needs the support of some external applications. Let’s take a look at the XA mode usage process in Seata.
Let’s first look at an official picture:
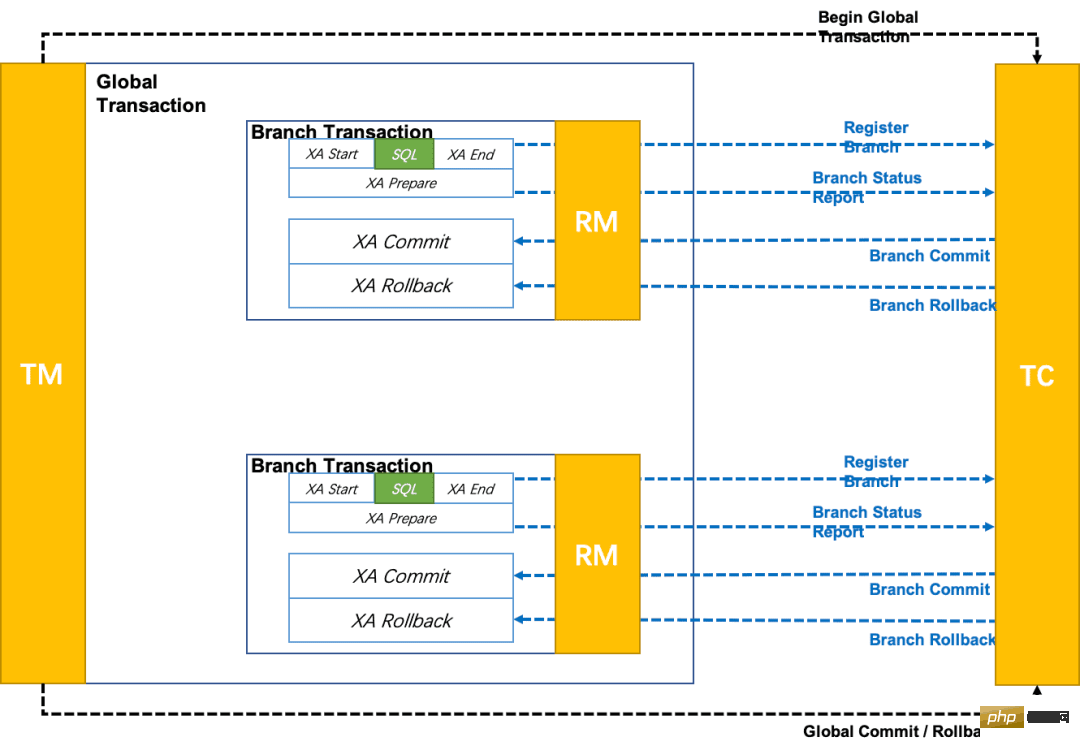
- Phase one: Business SQL operations are performed in the XA branch. After the XA branch is completed, XA prepare is executed, and persistence is guaranteed by RM's support for the XA protocol ( That is, any subsequent accidents will not cause rollback to be impossible).
- The second phase is divided into two situations: commit or rollback:
- Branch submission: execute the commit of the XA branch
- The difference between the previous two modes is that the rollback in the XA mode is a serious rollback , is a rollback as we understand it in the traditional sense, rather than a reverse compensation.
7. Saga mode
Finally, let’s take a look at the saga mode. This mode is rarely used, so everyone can understand it.
The saga mode is a long transaction solution provided by seata. However, long transactions are what we should avoid in development because they are inefficient and can easily cause deadlocks.
This saga mode is a bit like a process engine. The developer first draws a process engine by himself and includes all the methods involved in the entire transaction. When each method returns something, it is normal, and whatever it returns is If it is abnormal, if it is normal, continue on. If it is abnormal, another set of processes will be executed. That is to say, we need to prepare two sets of methods in advance. The first set is the execution process for various normal situations, and the second set is for exceptions. The subsequent execution process is similar to the following:
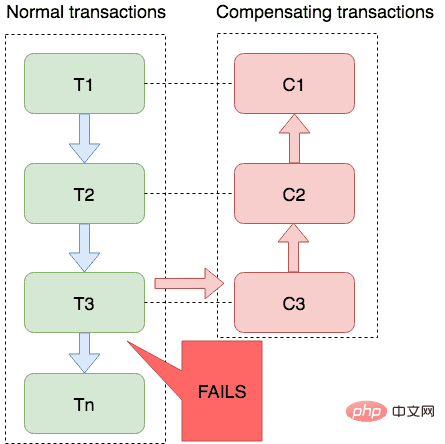 The green ones are normal processes, and the red ones are the processes that are rolled back after an exception occurs. Rollback is also a kind of reverse compensation.
The green ones are normal processes, and the red ones are the processes that are rolled back after an exception occurs. Rollback is also a kind of reverse compensation.
The above is the detailed content of How to solve Java Spring Boot distributed transaction problem. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Guide to TimeStamp to Date in Java. Here we also discuss the introduction and how to convert timestamp to date in java along with examples.
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Java is a popular programming language that can be learned by both beginners and experienced developers. This tutorial starts with basic concepts and progresses through advanced topics. After installing the Java Development Kit, you can practice programming by creating a simple "Hello, World!" program. After you understand the code, use the command prompt to compile and run the program, and "Hello, World!" will be output on the console. Learning Java starts your programming journey, and as your mastery deepens, you can create more complex applications.
