
 Technology peripherals
AI
Is AI development ushering in unification in 70 years? Ma Yi, Cao Ying, Shen Xiangyang's latest AI review: exploring the basic principles and 'standard model' of intelligence generation
Technology peripherals
AI
Is AI development ushering in unification in 70 years? Ma Yi, Cao Ying, Shen Xiangyang's latest AI review: exploring the basic principles and 'standard model' of intelligence generation
Is AI development ushering in unification in 70 years? Ma Yi, Cao Ying, Shen Xiangyang's latest AI review: exploring the basic principles and 'standard model' of intelligence generation

Artificial intelligence has been developing for seventy years. Although technical indicators have been constantly refreshed, there is still no answer to what exactly "intelligence" is and how it appears and develops.
Recently, Professor Ma Yi teamed up with computer scientist Dr. Shen Xiangyang and neuroscientist Professor Cao Ying to publish a research review on the emergence and development of intelligence, hoping to theoretically put the research on intelligence into practice. Unify to improve the understanding and interpretability of artificial intelligence models.

Paper link: http://arxiv.org/abs/2207.04630
Introduced in the article Two basic principles: Parsimony and Self-consistency.
The author believes that this is the cornerstone of the rise of intelligence, artificial or natural. Although there are numerous discussions and elaborations on each of these two principles in classic literature, this article reinterprets these two principles in a completely measurable and calculable way.
Based on these two first principles, the authors derive an efficient computational framework: compressed closed-loop transcription, which unifies and explains modern deep networks and many artificial intelligence practices. evolution.
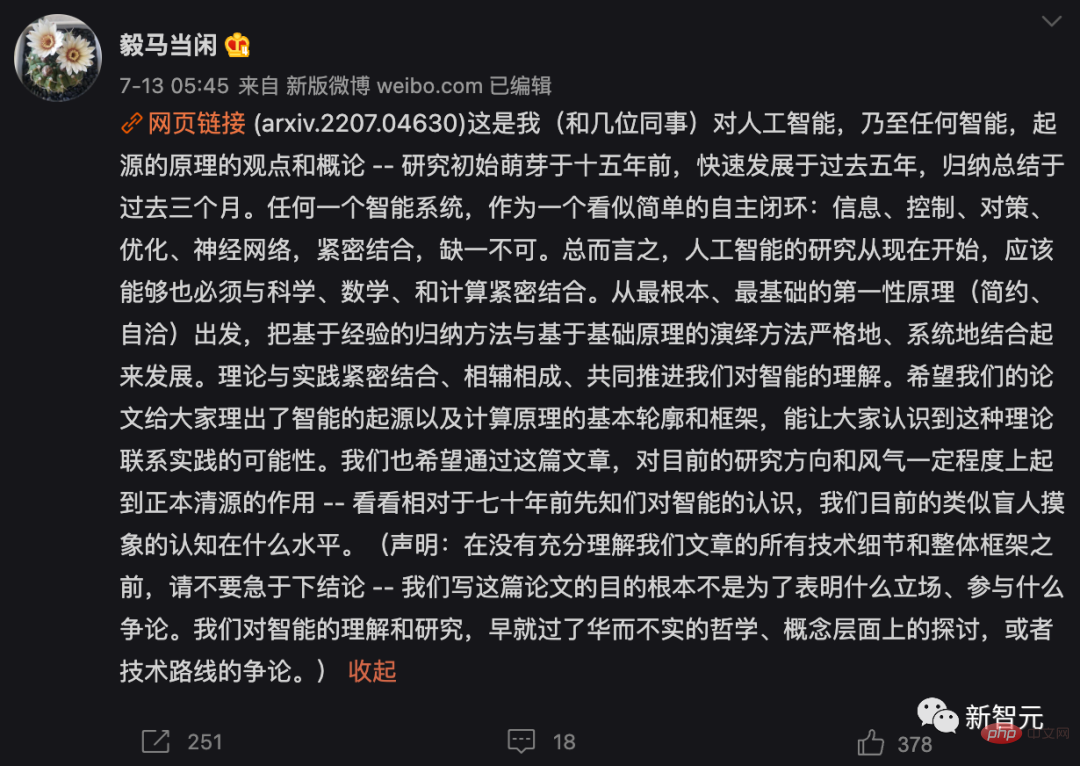
- What to learn: What to learn from data, and how to measure the quality of learning?
- How to learn: How do we achieve such a learning goal through an efficient and effective computing framework?
Regarding the first question of "what to learn", the principle of simplicity holds that:
The learning goal of an intelligent system is to learn from Find low-dimensional structures in observational data in the external world and reorganize and represent them in the most compact and structured way. This is the "Occam's razor" principle: don't add entities unless necessary.Without this principle, intelligence would not be possible! If the observation data of the external world has no low-dimensional structure, there will be nothing worth learning or remembering, and good generalization or prediction will not be possible.
Moreover, intelligent systems need to save resources as much as possible, such as energy, space, time and material. In some cases, this principle is also called the "compression principle". However, the parsimony of intelligence is not to achieve the best compression, but to obtain the most compact and structured expression of the observation data through efficient computing means.
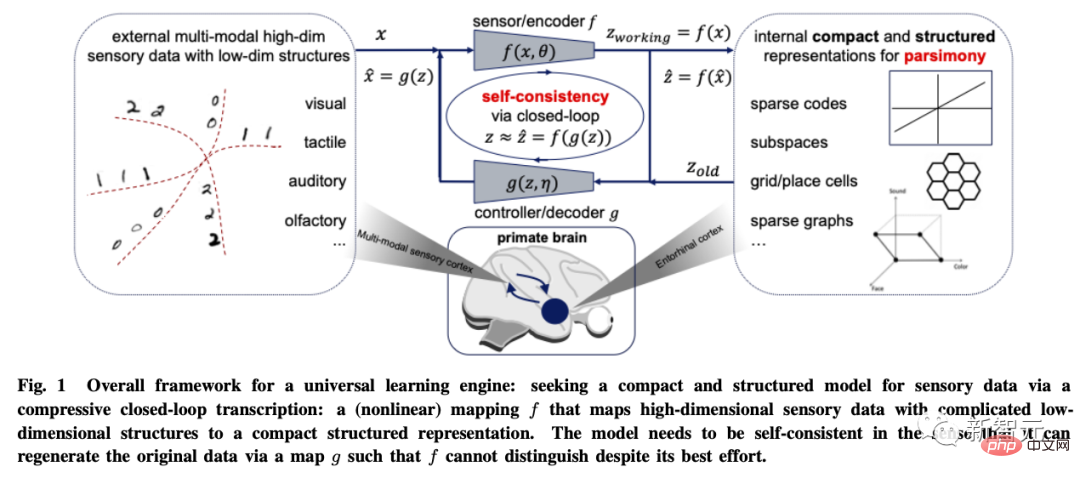
So how to measure simplicity?
For general high-dimensional models, the computational cost of many commonly used mathematical or statistical "measures" is exponential, or for data distributions with low-dimensional structures. Said, even undefined, such as maximum likelihood, KL divergence, mutual information, Jensen-Shannon and Wasserstein distance, etc.
The author believes that the purpose of learning is actually to establish a mapping (usually nonlinear) to obtain a low-dimensional representation from the original high-dimensional input.
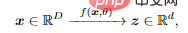
In this way, the distribution of the obtained feature z should be more compact and structured; compactness means more economical storage; Structure means more efficient access and use: linear structures, in particular, are ideal for interpolation or extrapolation.
For this purpose, the author introduces Linear Discriminant Representation (LDR) to achieve three sub-goals:
- Compression: Map high-dimensional sensory data x to low-dimensional representation z;
- Linearization: Map each type of object distributed in the nonlinear subsurface to a linear subspace;
- Sparsification: mapping different categories into mutually independent or least relevant subspaces.
These goals can be achieved through maximum coding rate reduction (rate reduction) to ensure that all The learned LDR model has optimal parsimony performance.
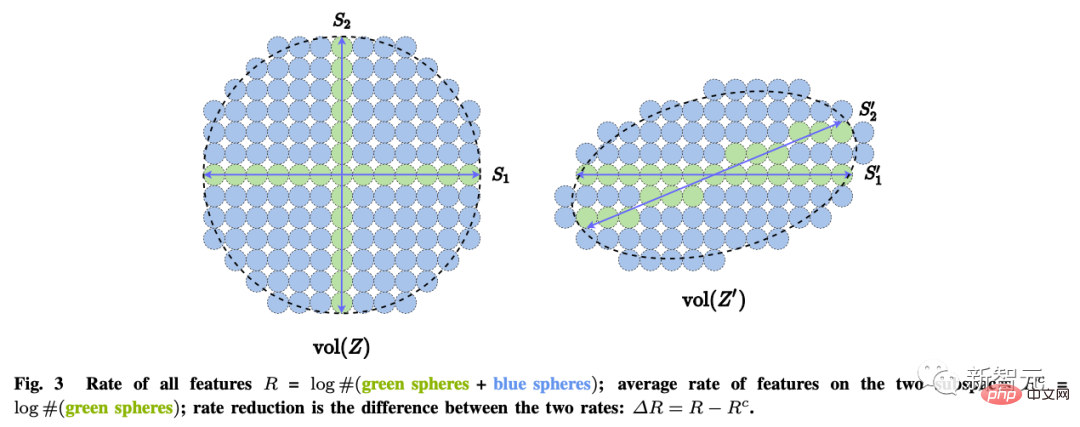
Regarding the second question of "how to learn", the self-consistency principle holds that:
An autonomous intelligent system seeks the most self-consistent model for observations of the external world by minimizing the differences in internal representations of observed data and regenerated data.
The principle of parsimony alone does not ensure that the learned model captures all important information about the data about the external world. For example, mapping each category to a one-dimensional one-hot vector by minimizing cross-entropy can be seen as a form of parsimony.
It may learn a good classifier, but the learned features may also collapse into a singleton, also known as neural collapse. Such learned features will no longer contain enough information to regenerate the original data.
Even if we consider the more general LDR model, maximizing the coding rate difference alone cannot automatically determine the correct dimensions of the environment feature space.
If the dimensionality of the feature space is too low, the learned model will not match the data; if it is too high, the model may over-match.
More generally, we argue that perceptual learning is distinct from learning specific tasks. The goal of perception is to learn everything predictable about what is being perceived.
As Einstein once said: "Things should be kept simple, but not too simple."
Universal Learning Engine
Based on these two principles, the article uses visual image data modeling as an example to derive the compressive closed-loop transcription framework.
It performs compressed closed-loop transcription of nonlinear data sub-flow patterns internally to achieve LDR by comparing and minimizing the differences in internal representations.
The chase-and-flight game between the encoder/sensor and the decoder/controller allows the distribution of data generated by the decoded representation to chase and match the observed real data distribution.
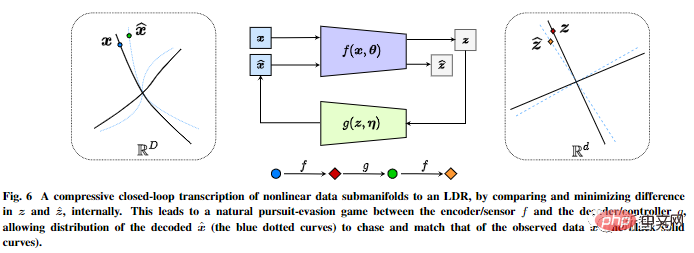
In addition, the author pointed out that compressed closed-loop transcription can effectively perform incremental learning.
An LDR model for a new data class can be learned through a constrained game between the encoder and the decoder: the memory of past learned classes can be naturally It is retained as a constraint in the game, that is, as a "fixed point" for closed-loop transcription.
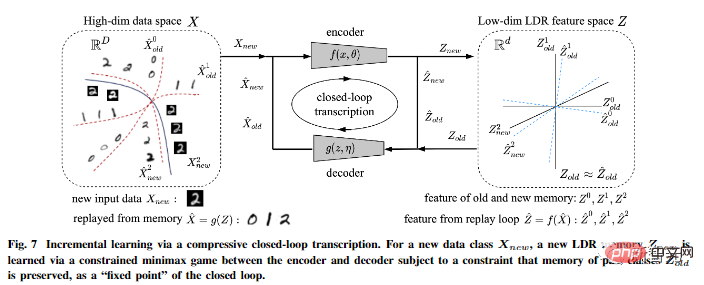
The article also puts forward more speculative ideas about the universality of this framework and extends it to three dimensions. Vision and reinforcement learning, and predicting its impact on neuroscience, mathematics, and advanced intelligence.
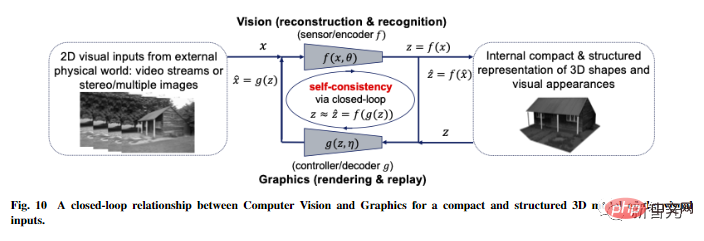
Through this framework derived from first principles: information encoding theory, closed-loop feedback control, optimization/depth The concepts of network and game theory are organically integrated and become an essential part of a complete, autonomous intelligent system.

It is worth mentioning that compressed closed-loop architecture is ubiquitous in all intelligent creatures in nature and at different scales : From the brain (compressed sensory information), to spinal circuits (compressed muscle movements), to DNA (compressed protein functional information) and so on.
So the author believes that compressive closed-loop transcription should be the "universal learning engine" behind all intelligent behaviors. It enables natural or artificial intelligence systems to discover and refine low-dimensional structures from seemingly complex sensory data, converting them into concise and regular internal expressions to facilitate correct judgment and prediction of the external world in the future.
This is the calculation basis and mechanism for the occurrence and development of all intelligence.
Reference: http://arxiv.org/abs/2207.04630
The above is the detailed content of Is AI development ushering in unification in 70 years? Ma Yi, Cao Ying, Shen Xiangyang's latest AI review: exploring the basic principles and 'standard model' of intelligence generation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 o1 vs GPT-4o: Is OpenAI's New Model Better Than GPT-4o?
Mar 16, 2025 am 11:47 AM
o1 vs GPT-4o: Is OpenAI's New Model Better Than GPT-4o?
Mar 16, 2025 am 11:47 AM
OpenAI's o1: A 12-Day Gift Spree Begins with Their Most Powerful Model Yet December's arrival brings a global slowdown, snowflakes in some parts of the world, but OpenAI is just getting started. Sam Altman and his team are launching a 12-day gift ex
 Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google DeepMind's GenCast: A Revolutionary AI for Weather Forecasting Weather forecasting has undergone a dramatic transformation, moving from rudimentary observations to sophisticated AI-powered predictions. Google DeepMind's GenCast, a groundbreak
 Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
The article discusses AI models surpassing ChatGPT, like LaMDA, LLaMA, and Grok, highlighting their advantages in accuracy, understanding, and industry impact.(159 characters)
