

TensorFlow application technology expansion—image classification

1. Scientific research platform environment deployment operation expansion
For model training in machine learning, I recommend that you learn more official TensorFlow courses or resources, such as the two courses on the Chinese University MOOC《TensorFlow Introductory Practical Course》and《TensorFlow Introductory Course - Deployment》. For distributed training of models involved in scientific research or work, a resource platform may often be very time-consuming and unable to meet individual needs in a timely manner. Here, I will make a specific expansion on the use of the Jiutian Bisheng platform mentioned in the previous article"Preliminary Understanding of TensorFlow Framework Learning"to facilitate students and users to more quickly Carry out model training. This platform can perform tasks such as data management and model training, and is a convenient and fast practice platform for scientific research tasks. The specific steps in model training are:
(1) Register and log in to the Jiutian Bisheng platform. Since subsequent training tasks require the consumption of computing power beans, the number of computing power beans for new users is limited, but they can be shared by Friends and other tasks to complete the acquisition of computing power beans. At the same time, for large-scale model training tasks, in order to obtain more model training storage space, you can contact the staff of the platform by email to upgrade the console, thereby meeting the training storage requirements required in the future. The details of storage and computing power are as follows:

(2) Enter the data management interface to deploy the data sets used by the scientific research project model, and perform the data set required for scientific research tasks. Package and upload to complete the deployment of the data sets required for model training on the platform.
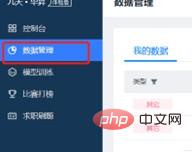
(3) Add a new project training instance in the model training window, select the previously imported data set and the required CPU resources. The created instance is a single model file that needs to be trained for scientific research. The details of the new project instance are as shown below:

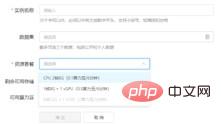
(4) Run the newly added project instance, that is, run the project training environment , after running successfully, you can choose the jupyter editor to create and edit the required code files.

(5) Subsequent code writing and model training can be performed using the jupyter editor.
2. Image classification technology expansion
Image classification, as the name suggests, is to judge the categories of different images based on the differences between images. Designing a discriminant model based on the differences between images is knowledge that needs to be mastered in machine learning. For the basic knowledge and operation process of image classification, you can refer to the "TensorFlow Introductory Practical Course" on the Chinese University MOOC to quickly understand the basic application and design ideas of TensorFlow. . https://www.php.cn/link/b977b532403e14d6681a00f78f95506e
This chapter is mainly intended to introduce students to this course by expanding image classification technology. Users gain a deeper understanding of image classification.
2.1 What is the use of convolution operation?
When it comes to processing or classifying images, one operation cannot be avoided, and this operation is convolution. Specific convolution operations can basically be understood through learning videos, but more readers may only stay at the level of how to perform convolution operations, and why convolution is performed and what is the use of convolution operations are still unclear. A little knowledge. Here is some expansion for everyone to help you better understand convolution.
The basic convolution process is shown in the figure below. Taking the image as an example, a matrix is used to represent the image. Each element of the matrix is the corresponding pixel value in the image. The convolution operation is to obtain the eigenvalues of these small areas by multiplying the convolution kernel by the corresponding matrix. The extracted features will differ due to different convolution kernels. This is why someone will perform convolution operations on different channels of the image to obtain the features of different channels of the image to better perform subsequent classification tasks.
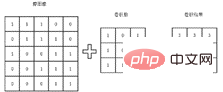
In daily model training, the specific convolution kernel does not need to be manually designed, but is automatically trained using the network by giving the real label of the image. However, this process is not conducive to people's understanding of the convolution kernel. The kernel and convolution process are not intuitive. Therefore, in order to help everyone better understand the meaning of convolution operation, here is an example of convolution operation. As shown in the matrix below, the numerical values represent the pixels of the graphic. For the convenience of calculation, only 0 and 1 are taken here. It is not difficult to see that the characteristics of this matrix graphic are that the upper half of the graphic is bright and the lower half of the graphic is black, so the image There is a very clear dividing line, that is, it has obvious horizontal characteristics.

Therefore, in order to well extract the horizontal features of the above matrix, the designed convolution kernel should also have the attributes of horizontal feature extraction. The convolution kernel that uses vertical feature extraction attributes is relatively insufficient in the obviousness of feature extraction. As shown below, the convolution kernel that extracts horizontal features is used for convolution:
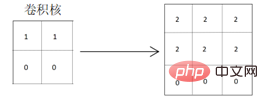
It can be seen from the obtained convolution result matrix that the horizontal features of the original graphics are well extracted. out, and the dividing lines of the graphics will be more obvious, because the pixel values of the colored parts of the graphics are deepened, which can well extract and highlight the horizontal features of the graphics. When convolution is performed using a convolution kernel that extracts vertical features:
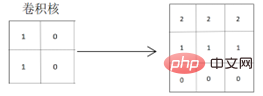
# It can be seen from the obtained convolution result matrix that the horizontal features of the original graphics can also be extracted, but Two dividing lines will be generated. The graphics change from extremely bright to bright and then to black. The situation reflected on the real graphics will also change from light to dark to black, which is different from the horizontal characteristics of the real original graphics. .
It is easy to know from the above examples that different convolution kernels will affect the quality of the final extracted graphic features. At the same time, the characteristics reflected by different graphics are also different. How to use different graphic feature attributes to It is also particularly critical to design network models to better learn and design convolution kernels. In actual map classification projects, it is necessary to select and extract appropriate features based on differences in images, and often there are trade-offs to consider.
2.2 How to consider convolution for better image classification?
As you can see from the role of convolution operations in the previous section, it is particularly important to design a network model to better learn the convolution kernel that adapts to the image. However, in practical applications, automatic learning and training are performed by converting the real labels of the given image categories into vector data that the machine can understand. Of course, it is not completely impossible to improve through manual settings. Although the labels of the data set are fixed, we can choose different network models based on the image types of the data set. Considering the advantages and disadvantages of different network models will often have good training results.
At the same time, when extracting image features, you can also consider using the multi-task learning method. In the existing image data, use the image data once again to extract some additional image features (such as the channel features of the image) and spatial features, etc.), and then supplement or fill in the previously extracted features to improve the final extracted image features. Of course, sometimes this operation will cause the extracted features to be redundant, and the classification effect obtained is often counterproductive. Therefore, it needs to be considered based on the actual training classification results.
2.3 Some suggestions for network model selection
The field of image classification has been developing for a long time, from the original classic AlexNet network model to the popular ResNet network model in recent years. etc., image classification technology has developed relatively well, and the classification accuracy for some commonly used image data sets has tended to be 100%. At present, in this field, most people use the latest network models, and in most image classification tasks, using the latest network models can indeed bring obvious classification effects. Therefore, many people use the latest network models in this field. People often ignore previous network models and go directly to learn the latest and popular network models.
Here, I still recommend that readers get familiar with some classic network models in the field of graph classification, because technology updates and iterations are very fast, and even the latest network models will be used in the future. It may be eliminated, but the operating principles of the basic network models are roughly the same. By mastering the classic network models, you can not only master the basic principles, but also understand the differences between different network models and the advantages of processing different tasks. Inferiority. For example, when your image data set is relatively small, training with the latest network model may be very complex and time-consuming, but the improvement effect is minimal, so sacrificing your own training time cost for a negligible effect is not worth the gain. Therefore, to master the image classification network model, you need to know what it is and why it is so that you can truly be targeted when choosing an image classification model in the future.
Author introduction:
Rice, 51CTO community editor, once worked in the big data technology department of an e-commerce artificial intelligence research and development center, doing recommendation algorithms. Currently engaged in research in the direction of natural language processing. His main areas of expertise include recommendation algorithms, NLP, and CV. The coding languages used include Java, Python, and Scala. Published one ICCC conference paper.
The above is the detailed content of TensorFlow application technology expansion—image classification. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 How to Undo Delete from Home Screen in iPhone
Apr 17, 2024 pm 07:37 PM
How to Undo Delete from Home Screen in iPhone
Apr 17, 2024 pm 07:37 PM
Deleted something important from your home screen and trying to get it back? You can put app icons back on the screen in a variety of ways. We have discussed all the methods you can follow and put the app icon back on the home screen. How to Undo Remove from Home Screen in iPhone As we mentioned before, there are several ways to restore this change on iPhone. Method 1 – Replace App Icon in App Library You can place an app icon on your home screen directly from the App Library. Step 1 – Swipe sideways to find all apps in the app library. Step 2 – Find the app icon you deleted earlier. Step 3 – Simply drag the app icon from the main library to the correct location on the home screen. This is the application diagram
 The role and practical application of arrow symbols in PHP
Mar 22, 2024 am 11:30 AM
The role and practical application of arrow symbols in PHP
Mar 22, 2024 am 11:30 AM
The role and practical application of arrow symbols in PHP In PHP, the arrow symbol (->) is usually used to access the properties and methods of objects. Objects are one of the basic concepts of object-oriented programming (OOP) in PHP. In actual development, arrow symbols play an important role in operating objects. This article will introduce the role and practical application of arrow symbols, and provide specific code examples to help readers better understand. 1. The role of the arrow symbol to access the properties of an object. The arrow symbol can be used to access the properties of an object. When we instantiate a pair
 DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
This paper explores the problem of accurately detecting objects from different viewing angles (such as perspective and bird's-eye view) in autonomous driving, especially how to effectively transform features from perspective (PV) to bird's-eye view (BEV) space. Transformation is implemented via the Visual Transformation (VT) module. Existing methods are broadly divided into two strategies: 2D to 3D and 3D to 2D conversion. 2D-to-3D methods improve dense 2D features by predicting depth probabilities, but the inherent uncertainty of depth predictions, especially in distant regions, may introduce inaccuracies. While 3D to 2D methods usually use 3D queries to sample 2D features and learn the attention weights of the correspondence between 3D and 2D features through a Transformer, which increases the computational and deployment time.
 From beginner to proficient: Explore various application scenarios of Linux tee command
Mar 20, 2024 am 10:00 AM
From beginner to proficient: Explore various application scenarios of Linux tee command
Mar 20, 2024 am 10:00 AM
The Linuxtee command is a very useful command line tool that can write output to a file or send output to another command without affecting existing output. In this article, we will explore in depth the various application scenarios of the Linuxtee command, from entry to proficiency. 1. Basic usage First, let’s take a look at the basic usage of the tee command. The syntax of tee command is as follows: tee[OPTION]...[FILE]...This command will read data from standard input and save the data to
 Explore the advantages and application scenarios of Go language
Mar 27, 2024 pm 03:48 PM
Explore the advantages and application scenarios of Go language
Mar 27, 2024 pm 03:48 PM
The Go language is an open source programming language developed by Google and first released in 2007. It is designed to be a simple, easy-to-learn, efficient, and highly concurrency language, and is favored by more and more developers. This article will explore the advantages of Go language, introduce some application scenarios suitable for Go language, and give specific code examples. Advantages: Strong concurrency: Go language has built-in support for lightweight threads-goroutine, which can easily implement concurrent programming. Goroutin can be started by using the go keyword
 Review! Deep model fusion (LLM/basic model/federated learning/fine-tuning, etc.)
Apr 18, 2024 pm 09:43 PM
Review! Deep model fusion (LLM/basic model/federated learning/fine-tuning, etc.)
Apr 18, 2024 pm 09:43 PM
In September 23, the paper "DeepModelFusion:ASurvey" was published by the National University of Defense Technology, JD.com and Beijing Institute of Technology. Deep model fusion/merging is an emerging technology that combines the parameters or predictions of multiple deep learning models into a single model. It combines the capabilities of different models to compensate for the biases and errors of individual models for better performance. Deep model fusion on large-scale deep learning models (such as LLM and basic models) faces some challenges, including high computational cost, high-dimensional parameter space, interference between different heterogeneous models, etc. This article divides existing deep model fusion methods into four categories: (1) "Pattern connection", which connects solutions in the weight space through a loss-reducing path to obtain a better initial model fusion
 More than just 3D Gaussian! Latest overview of state-of-the-art 3D reconstruction techniques
Jun 02, 2024 pm 06:57 PM
More than just 3D Gaussian! Latest overview of state-of-the-art 3D reconstruction techniques
Jun 02, 2024 pm 06:57 PM
Written above & The author’s personal understanding is that image-based 3D reconstruction is a challenging task that involves inferring the 3D shape of an object or scene from a set of input images. Learning-based methods have attracted attention for their ability to directly estimate 3D shapes. This review paper focuses on state-of-the-art 3D reconstruction techniques, including generating novel, unseen views. An overview of recent developments in Gaussian splash methods is provided, including input types, model structures, output representations, and training strategies. Unresolved challenges and future directions are also discussed. Given the rapid progress in this field and the numerous opportunities to enhance 3D reconstruction methods, a thorough examination of the algorithm seems crucial. Therefore, this study provides a comprehensive overview of recent advances in Gaussian scattering. (Swipe your thumb up
 Revolutionary GPT-4o: Reshaping the human-computer interaction experience
Jun 07, 2024 pm 09:02 PM
Revolutionary GPT-4o: Reshaping the human-computer interaction experience
Jun 07, 2024 pm 09:02 PM
The GPT-4o model released by OpenAI is undoubtedly a huge breakthrough, especially in its ability to process multiple input media (text, audio, images) and generate corresponding output. This ability makes human-computer interaction more natural and intuitive, greatly improving the practicality and usability of AI. Several key highlights of GPT-4o include: high scalability, multimedia input and output, further improvements in natural language understanding capabilities, etc. 1. Cross-media input/output: GPT-4o+ can accept any combination of text, audio, and images as input and directly generate output from these media. This breaks the limitation of traditional AI models that only process a single input type, making human-computer interaction more flexible and diverse. This innovation helps power smart assistants
