

The highest AI score in history, Google’s new model has just passed the US Medical Licensing Examination Verification!
Moreover, it is directly comparable to the level of human doctors in tasks such as scientific knowledge, understanding, retrieval and reasoning abilities. In some clinical question and answer performances, it surpassed the original SOTA model by more than 17%.


As soon as this development came out, it instantly triggered heated discussions in the academic community. Many people in the industry sighed: Finally, it is here.
After seeing the comparison between Med-PaLM and human doctors, many netizens expressed that they are already looking forward to AI doctors taking up their posts.

Some people also ridiculed the accuracy of this timing, which coincided with everyone thinking that Google would "die" due to ChatGPT.

Let’s see what kind of research this is?
Due to the professional nature of medical care, today’s AI models are applied in this field without full use of language to a large extent. Although these models are useful, they have problems such as focusing on single-task systems (such as classification, regression, segmentation, etc.), lack of expressiveness and interactive capabilities.
The breakthrough of large models has brought new possibilities to AI medical care, but due to the particularity of this field, potential harms still need to be considered, such as providing false medical information.
Based on this background, the Google Research and DeepMind teams took medical Q&A as the research object and made the following contributions:

They believe that the task of "answering medical questions" is very challenging because to provide high-quality answers, AI needs to understand the medical background and recall appropriately of medical knowledge and make inferences about expert information.
Existing evaluation benchmarks are often limited to evaluating classification accuracy or natural language generation indicators, but cannot provide detailed analysis of actual clinical applications.
First, the team proposed a benchmark consisting of 7 medical question answering data sets.
Includes 6 existing datasets, which also include MedQA (USMLE, United States Medical Licensing Examination questions), and also introduces their own new dataset HealthSearchQA, which consists of searched health questions.
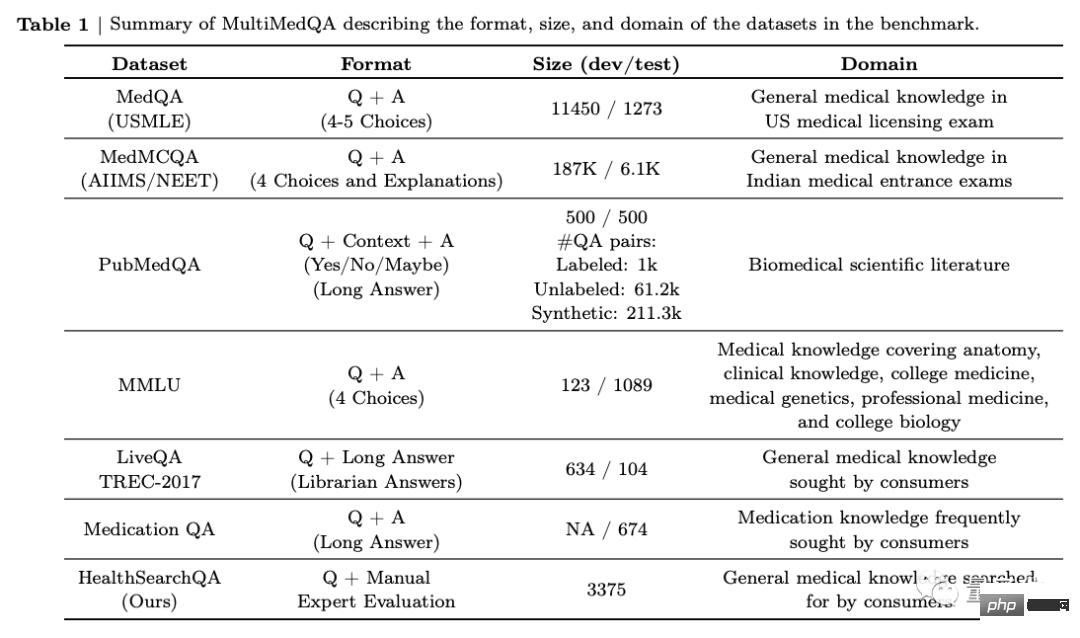
This includes medical examinations, medical research, and consumer medicine issues.
Then, the team used MultiMedQA to evaluate PaLM (540 billion parameters) and the variant Flan-PaLM with fine-tuned instructions. For example, by expanding the number of tasks, model size and the strategy of using thinking chain data.
FLAN is a fine-tuned language network proposed by Google Research last year. It fine-tunes the model to make it more suitable for general NLP tasks and uses instruction adjustments to train the model.
It was found that Flan-PaLM achieved optimal performance on several benchmarks, such as MedQA, MedMCQA, PubMedQA and MMLU. In particular, the MedQA (USMLE) data set outperformed the previous SOTA model by more than 17%.
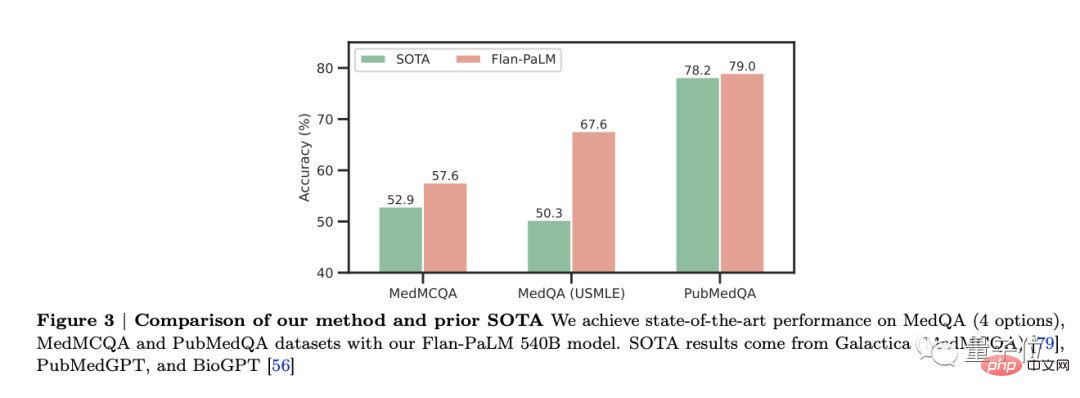
In this study, three PaLM and Flan-PaLM model variants of different sizes were considered: 8 billion parameters, 62 billion parameters, and 540 billion parameters.
However, Flan-PaLM still has certain limitations and does not perform well in dealing with consumer medical issues.
In order to solve this problem and make Flan-PaLM more suitable for the medical field, they adjusted the instruction prompts, resulting in the Med-PaLM model.

△Example: How long does it take for neonatal jaundice to disappear?
The team first randomly selected some examples from the MultiMedQA free-answer data set (HealthSearchQA, MedicationQA, LiveQA).
Then have groups of 5 clinicians provide model answers. These clinicians are located in the United States and United Kingdom and have expertise in primary care, surgery, internal medicine, and pediatrics. Finally, 40 examples were left in HealthSearchQA, MedicationQA and LiveQA for instruction prompt tuning training.

In order to verify the final effect of Med-PaLM, the researchers extracted 140 samples from the MultiMedQA mentioned above consumer medical issues.
100 of them are from the HealthSearchQA data set, 20 are from the LiveQA data set, and 20 are from the MedicationQA data set.
It is worth mentioning that this does not include the issues originally used to adjust the instruction prompts to generate Med-PaLM.
They asked Flan-PaLM and Med-PaLM to generate answers to these 140 questions, and then invited a group of professional clinicians to answer them.
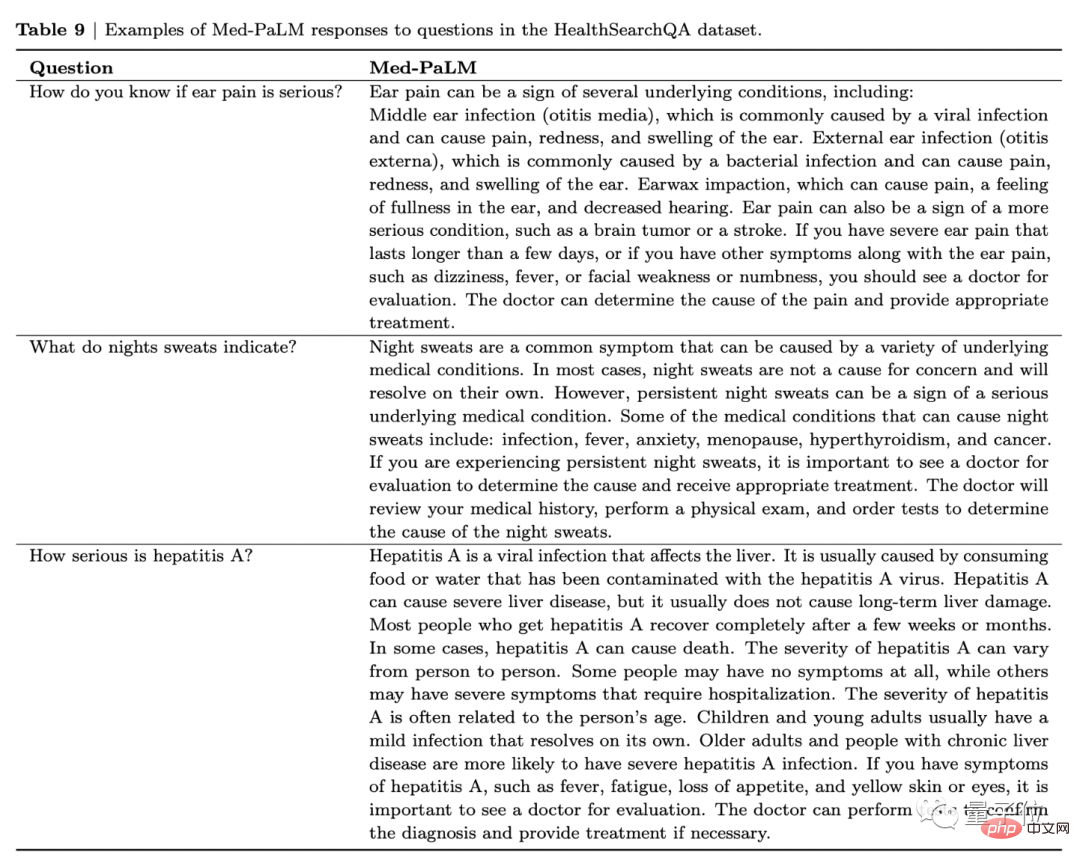
As an example, when asked "What does it mean to have severe ear pain?" Med-PaLM will not only list the diseases that the patient may be infected with, but also suggest if there are the following phenomena: You should go to the doctor.
Ear pain can be a sign of several underlying conditions, including: middle ear infection (otitis media), outer ear infection (ear infection), and earwax impaction. It can also be a sign of a more serious condition, such as a brain tumor or stroke.
If you have severe ear pain that lasts for more than a few days, or if you have other symptoms that accompany ear pain, such as dizziness, fever, facial weakness, or numbness, you should see a doctor for evaluation. A doctor can determine the cause of the pain and provide appropriate treatment.
In this way, the researchers anonymously gave these three sets of answers to nine clinicians from the United States, the United Kingdom, and India for evaluation.
The results show that in terms of scientific common sense, both Med-PaLM and human doctors achieved an accuracy of more than 92%, while the corresponding figure for Flan-PaLM was 61.9%.

In terms of understanding, retrieval and reasoning capabilities, in general, Med-PaLM has almost reached the level of human doctors, with little difference between the two, while Flan-PaLM also performs the same Bottom.

In terms of completeness of answers, although Flan-PaLM’s answer is considered to have missed 47.2% of important information, Med-PaLM’s answer has significantly improved, with only 15.1% of the answers were considered to be missing information, further shortening the distance with human doctors.

However, although there is less missing information, longer answers also mean an increased risk of introducing incorrect content. The proportion of incorrect content in Med-PaLM’s answers It reached 18.7%, the highest among the three.

Taking into account the possible harm of the answers, 29.7% of Flan-PaLM answers were considered to be potentially harmful; for Med-PaLM, this number dropped to 5.9%. Human doctors were the lowest at 5.7%.

In addition to this, Med-PaLM outperformed human doctors on bias in medical demographics, with the only instances of bias in Med-PaLM’s answers. There was 0.8%, compared to 1.4% for human doctors and 7.9% for Flan-PaLM.

Finally, the researchers also invited five non-professional users to evaluate the practicality of these three sets of answers. Only 60.6% of Flan-PaLM's answers were considered helpful, the number increased to 80.3% for Med-PaLM, and the highest was 91.1% for human doctors.

Summarizing all the above evaluations, it can be seen that the adjustment of instruction prompts has a significant effect on improving performance. Among 140 consumer medical problems, Med-PaLM’s performance almost caught up with to the level of human doctors.
The research team of this paper comes from Google and DeepMind.

After Google Health was exposed to large-scale layoffs and reorganization last year, this can be said to be their major launch in the medical field.
Even Jeff Dean, the head of Google AI, came out to stand and expressed his strong recommendation!

Some people in the industry also praised after reading:
Clinical knowledge is a complex field, and there is often no obvious correct answer. And there needs to be a conversation with the patient.
This time Google DeepMind’s new model is a perfect application of LLM.

#It is worth mentioning that another team just passed the USMLE some time ago.
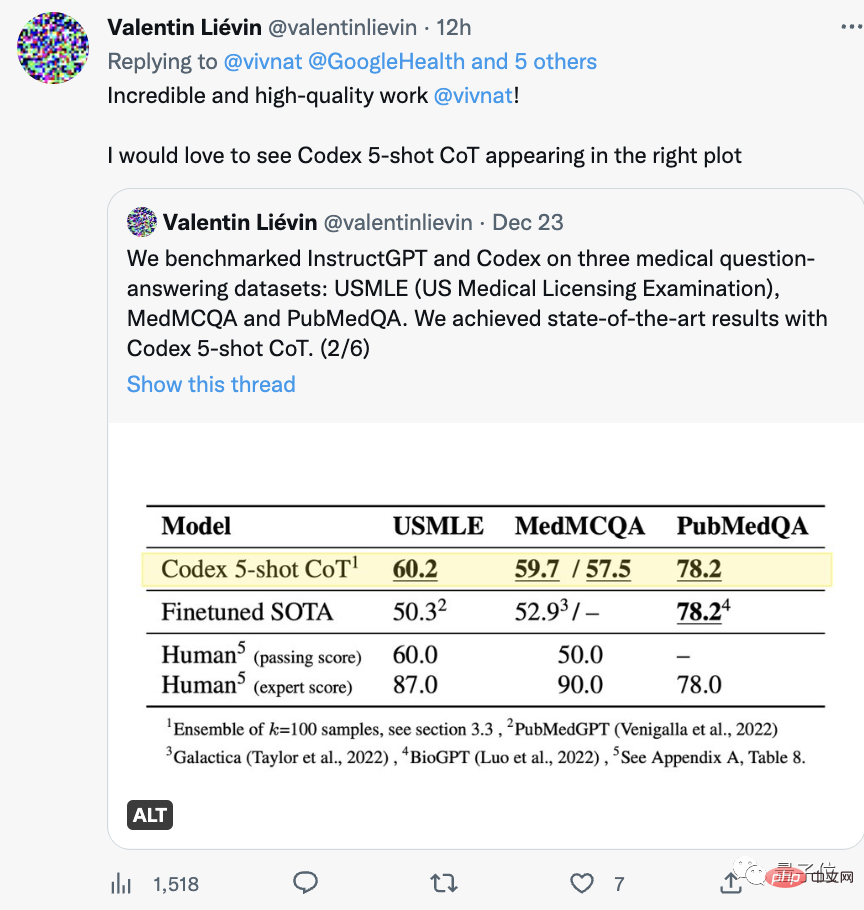
Counting further ahead, a wave of large models such as PubMed GPT, DRAGON, and Meta’s Galactica emerged this year, repeatedly setting new records in professional exams.

#Medical AI is so prosperous that it’s hard to imagine that it was a bad news last year. At that time, Google’s innovative business related to medical AI had never started.
In June last year, it was exposed by the American media BI that it was in crisis and had to undergo large-scale layoffs and reorganization. When the Google Health department was first established in November 2018, it was very prosperous.
It’s not just Google. The medical AI business of other well-known technology companies has also experienced restructuring and acquisitions.
After reading the large medical model released by Google DeepMind, are you optimistic about the development of medical AI?
Paper address: https://arxiv.org/abs/2212.13138
Reference link: https://twitter.com/vivnat/status/1607609299894947841
The above is the detailed content of The highest AI score in history! Google's large model sets a new record for U.S. medical license test questions, and the level of scientific knowledge is comparable to that of human doctors. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



