

In mysql, phantom reading means that when the user reads a certain range of data rows, another transaction inserts a new row in the range. When the user reads the data rows in the range, You will find that there are new "phantom" rows. The so-called phantom read means that the data set queried through SELECT is not a real data set. The user queries through the SELECT statement that a certain record does not exist, but it may exist in the real table.

The operating environment of this tutorial: windows7 system, mysql8 version, Dell G3 computer.
Let’s first look at the isolation level of the transaction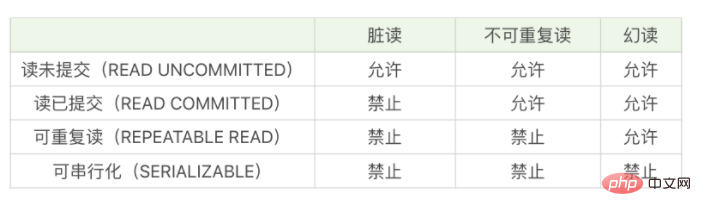
Then, let’s talk about phantom reading Before that, let me talk about my understanding of phantom reading:
The so-called phantom reading focuses on the word "phantom". It is very dreamy, very mysterious, and uncertain whether it is true or false, as if it is covered with a layer of fog. , you can't really see the other person, giving people an illusion. This is "illusion". The so-called phantom read means that the data set you query through SELECT is not a real data set. A certain record you query through the SELECT statement does not exist, but it may exist in the real table. .
This is how I understand phantom reading and non-repeatable reading:
Fantasy reading is about the question of whether it exists or not: it didn’t exist before, but now If it exists, it is a phantom readNon-repeatable read is about the problem of no change: it used to be A, but now it has become B, then it is a non-repeatable readFantasy reading, there are two theories that I understand so far:
The first statement: Transaction A obtained N pieces of data based on conditional query, but At this time, transaction B deletes or adds M pieces of data that meet the query conditions of transaction A. In this way, when transaction A queries again, the real data set has changed, but A cannot query this change, so an illusion occurs. read.
This statement emphasizes that phantom reading is caused by more or fewer data rows in a certain range. It emphasizes that different data sets lead to phantom reading.
Statement 2: Phantom reading does not mean that the result sets obtained by two reads are different. The focus of phantom reading is represented by the result of a certain select operation. The data status cannot support subsequent business operations. To be more specific: transaction A selects whether a certain record exists, and the result is that it does not exist. It is ready to insert this record, but when executing insert, it is found that this record already exists and cannot be inserted. At this time, a phantom read occurs. The reason for this is because another transaction inserted data into the table.
I personally prefer the first statement.
The second argument is also a phantom reading. The second argument is that the data set has changed, and the data set obtained by the query does not match the real data set.
Regarding statement 2: When performing INSERT, implicit reading is also required. For example, when inserting data, you need to read whether there is a primary key conflict, and then decide whether the insertion can be performed. If it is discovered that this record already exists, it cannot be inserted. Therefore, SELECT shows that it does not exist, but it is found to exist during INSERT, which means that the data rows that meet the conditions have changed, which is the case of phantom reading, while non-repeatable reading means that the content of the same record has been modified.
To illustrate with an example: The second statement talks about the following situation:
There are two transactions A and B. A transaction is opened first, and then A starts to query whether there is any data with id = 30 in the data set. Query The result shows that there is no data with id = 30 in the data. Immediately afterwards, another transaction B was opened. Transaction B inserted a piece of data with id = 30 into the table, and then submitted the transaction. Then A starts to insert the data with id = 30 into the table. Since transaction B has already inserted the data with id = 30, it cannot be inserted naturally. Then A queries again and finds that there is no data with id = 30 in the table. , transaction A is very confused, why can't data be inserted? After transaction A is submitted, query again and find that the data with id = 30 does exist in the table. But before transaction A was submitted, it couldn't be found out?
In fact, this is the role of repeatable reading.
The process is shown in the figure below:

The creation statement of the t table operated in the above figure is as follows:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) -- 创建索引 ) ENGINE=InnoDB; INSERT INTO t VALUES(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
InnoDB used by MySQL The default isolation level of the engine is Repeatable Read, which means that if you execute the same query twice in the same transaction, the result should be the same. Therefore, although transaction B added data to the table before transaction A ended, in order to maintain repeatable reading, the newly added data cannot be queried no matter how it is queried in transaction A. But for the real table, the data in the table has indeed increased.
A查询不到这个数据,不代表这个数据不存在。查询得到了某条数据,不代表它真的存在。这样是是而非的查询,就像是幻觉一样,似真似假,故为幻读。
产生幻读的原因归根到底是由于查询得到的结果与真实的结果不匹配。
幻读 VS 不可重复读
幻读重点在于数据是否存在。原本不存在的数据却真实的存在了,这便是幻读。在同一个事务中,第一次读取到结果集和第二次读取到的结果集不同。(对比上面的例子,当B事务INSERT以后,A事务中再进行插入,此次插入相当于一次隐式查询)。引起幻读的原因在于另一个事务进行了INSERT操作。不可重复读重点在于数据是否被改变了。在一个事务中对同一条记录进行查询,第一次读取到的数据和第二次读取到的数据不一致,这便是可重复读。引起不可重复读的原因在于另一个事务进行了UPDATE或者是DELETE操作。简单来说:幻读是说数据的条数发生了变化,原本不存在的数据存在了。不可重复读是说数据的内容发生了变化,原本存在的数据的内容发生了改变。
在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在 当前读 下才会出现。
什么是快照读,什么是当前读?
快照读读取的是快照数据。不加锁的简单的 SELECT都属于快照读,比如这样:
SELECT * FROM player WHERE ...
当前读就是读取最新数据,而不是历史版本的数据。加锁的 SELECT,或者对数据进行增删改都会进行当前读。这有点像是 Java 中的 volatile 关键字,被 volatile 修饰的变量,进行修改时,JVM 会强制将其写回内存,而不是放在 CPU 缓存中,进行读取时,JVM 会强制从内存读取,而不是放在 CPU 缓存中。这样就能保证其可见行,保证每次读取到的都是最新的值。如果没有用 volatile 关键字修饰,变量的值可能会被放在 CPU 缓存中,这就导致读取到的值可能是某次修改的值,不能保证是最新的值。
说多了,我们继续来看,如下的操作都会进行 当前读。
SELECT * FROM player LOCK IN SHARE MODE; SELECT * FROM player FOR UPDATE; INSERT INTO player values ... DELETE FROM player WHERE ... UPDATE player SET ...
说白了,快照读就是普通的读操作,而当前读包括了 加锁的读取 和 DML(DML只是对表内部的数据操作,不涉及表的定义,结构的修改。主要包括insert、update、deletet) 操作。
比如在可重复读的隔离条件下,我开启了两个事务,在另一个事务中进行了插入操作,当前事务如果使用当前读 是可以读到最新的数据的。

当隔离级别为可重复读的时候,事务只在第一次 SELECT 的时候会获取一次 Read View,而后面所有的 SELECT 都会复用这个 Read View。也就是说:对于A事务而言,不管其他事务怎么修改数据,对于A事务而言,它能看到的数据永远都是第一次SELECT时看到的数据。这显然不合理,如果其它事务插入了数据,A事务却只能看到过去的数据,读取不了当前的数据。
既然都说到 Read View 了,就不得不说 MVCC (多版本并发控制) 机制了。MVCC 其实字面意思还比较好理解,为了防止数据产生冲突,我们可以使用时间戳之类的来进行标识,不同的时间戳对应着不同的版本。比如你现在有1000元,你借给了张三 500 元, 之后李四给了你 500 元,虽然你的钱的总额都是 1000元,但是其实已经和最开始的 1000元不一样了,为了判断中途是否有修改,我们就可以采用版本号来区分你的钱的变动。
如下,在数据库的数据表中,id,name,type 这三个字段是我自己建立的,但是除了这些字段,其实还有些隐藏字段是 MySQL 偷偷为我们添加的,我们通常是看不到这样的隐藏字段的。
我们重点关注这两个隐藏的字段:
db_trx_id: The transaction ID that operates this row of data, that is, the last transaction ID that inserted or updated the data. Every time we start a transaction, we will get a transaction ID (that is, the transaction version number) from the database. This transaction ID is self-increasing. Through the ID size, we can judge the time sequence of the transaction.
db_roll_ptr: Rollback pointer, pointing to the Undo Log information of this record. What is Undo Log? It can be understood that when we need to modify a certain record, MySQL is worried that the modification may be revoked in the future and rolled back to the previous state. Therefore, before modifying, save the current data in a file and then modify it. Undo Log It can be understood as this archive file. This is just like when we play a game. After reaching a certain level, we save a file first, and then continue to challenge the next level. If we fail to challenge the next level, we go back to the previous save point instead of starting from scratch.
In the MVCC (Multiple Version Concurrency Control) mechanism, multiple transactions updating the same row record will generate multiple historical snapshots, and these historical snapshots are saved in Undo Log inside. As shown in the figure below, the rollback pointer recorded in the current row points to its previous state, and the rollback pointer of its previous state points to the previous state of the previous state. In this way, theoretically we can find any state of the row of data by traversing the rollback pointer.
Undo Log Schematic

We did not expect that what we saw might be just one piece of data, but MySQL stored multiple versions of that piece of data behind the scenes. , a lot of files have been saved for this data. Then the question comes. When we start a transaction, we want to query a certain piece of data in the transaction, but each piece of data corresponds to many versions. At this time, which version of the row record do we need to read?
At this time, we need to use the Read View mechanism, which helps us solve the row visibility problem. Read View saves a list of all active (not yet committed) transactions when the current transaction is opened.
There are several important attributes in Read VIew:
As we said before, there is a hidden field db_trx_id in each row of records, which represents the transaction ID of operating this row of data, and Transaction ID is self-increasing. Through the ID size, we can judge the time sequence of the transaction.
After we start the transaction and prepare to query a certain record, we find that the record's db_trx_id < up_limit_id, what does this mean? It means that this record must have been submitted before this transaction was started. For the current transaction, this is historical data and can be seen. Therefore, we can definitely find this record through select.
But if found, the db_trx_id > up_limit_id of the record to be queried. What does this mean? It means that when I opened the transaction, this record must not have existed yet. It was created later and should not be seen by the current transaction. At this time, we can return through The roll pointer Undo Log finds the historical version of the record and returns it to the current transaction. In this article What is phantom reading? An example given in this chapter. When transaction A is started, there is no record (30, 30, 30) in the database. After transaction A is started, transaction B inserts the record (30, 30, 30) into the database. At this time, transaction A uses select without locking When reading from the snapshot, this newly inserted record cannot be queried, which is in line with our expectations. For transaction A, the db_trx_id of this record (30, 30, 30) must be greater than the up_limit_id when transaction A is started, so this record should not be seen by transaction A.
If thetrx_id of the record to be queried satisfies the condition up_limit_id < trx_id < low_limit_id, Indicate that the transaction trx_id where this row is recorded may still be active when the current creator_trx_id transaction is created, so we need to do it in the trx_ids collection Traversal, if trx_id exists in the trx_ids collection, it proves that the transaction trx_id is still active and invisible. If the record has an Undo Log, we can pass The rollback pointer is traversed to query the historical version data of the record. If trx_id does not exist in the trx_ids collection, it proves that the transaction trx_id has been submitted and the row record is visible.
从图中你能看到回滚指针将数据行的所有快照记录都通过链表的结构串联了起来,每个快照的记录都保存了当时的 db_trx_id,也是那个时间点操作这个数据的事务 ID。这样如果我们想要找历史快照,就可以通过遍历回滚指针的方式进行查找。
最后,再来强调一遍:事务只在第一次 SELECT 的时候会获取一次 Read View
因此,如下图所示,在 可重复读 的隔离条件下,在该事务中不管进行多少次 以WHERE heigh > 2.08为条件 的查询,最终结果得到都是一样的,尽管可能会有其它事务对这个结果集进行了更改。

即便是给每行数据都加上行锁,也无法解决幻读,行锁只能阻止修改,无法阻止数据的删除。而且新插入的数据,自然是数据库中不存在的数据,原本不存在的数据自然无法对其加锁,因此仅仅使用行锁是无法阻止别的事务插入数据的。
为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (Gap Lock)。顾名思义,间隙锁,锁的就是两个值之间的空隙。比如文章开头的表 t,初始化插入了 6 个记录,这就产生了 7 个间隙。
表 t 主键索引上的行锁和间隙锁
也就是说这时候,在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。现在你知道了,数据行是可以加上锁的实体,数据行之间的间隙,也是可以加上锁的实体。但是间隙锁跟我们之前碰到过的锁都不太一样。
SELECT * FEOM t FOR UPDATE要把整个表所有记录锁起来,就形成了 7 个 next-key lock,分别是 (负无穷,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, 正无穷]。怎么加间隙锁呢?使用写锁(又叫排它锁,X锁)时自动生效,也就是说我们执行 SELECT * FEOM t FOR UPDATE时便会自动触发间隙锁。会给主键加上上图所示的锁。
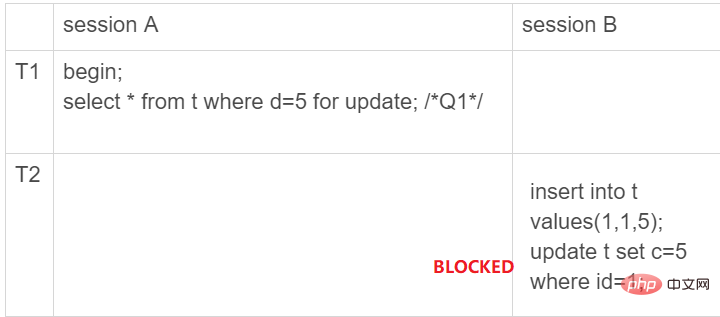
如下图所示,如果在事务A中执行了SELECT * FROM t WHERE d = 5 FOR UPDATE以后,事务B则无法插入数据了,因此就避免了产生幻读。
数据表的创建语句如下
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) -- 创建索引 ) ENGINE=InnoDB; INSERT INTO t VALUES(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
需要注意的是,由于创建数据表的时候仅仅只在c字段上创建了索引,因此使用条件WHERE id = 5查找时是会扫描全表的。因此,SELECT * FROM t WHERE d = 5 FOR UPDATE实际上锁住了整个表,如上图所示,产生了七个间隙,这七个间隙都不允许数据的插入。
因此当B想插入一条数据(1, 1, 1)时就会被阻塞住,因为它的主键位于位于(0, 5]这个区间,被禁止插入。
还需要注意的一点是,间隙锁和间隙锁是不会产生冲突的。读锁(又称共享锁,S锁)和写锁会冲突,写锁和写锁也会产生冲突。但是间隙锁和间隙锁是不会产生冲突的
如下:
A事务对id = 5的数据加了读锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁则会成功。读锁和读锁可以兼容,读锁和写锁则不能兼容。
A事务对id = 5的数据加了写锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁同样也会失败。
在加了间隙锁以后,当A事务开启以后,并对(5, 10]这个区间加了间隙锁,那么B事务则无法插入数据了。

但是当A事务对(5, 10]加了间隙锁以后,B事务也可以对这个区间加间隙锁。
The purpose of the gap lock is to prevent data from being inserted into this interval. Therefore, after transaction A is added, transaction B continues to add gap locks. This is not contradictory. But it is different for write locks and read locks.
A write lock does not allow other transactions to read or write, while a read lock allows writing, so there is a semantic conflict. Naturally, you cannot add these two locks at the same time.
The same is true for write locks and write locks. Write locks do not allow reading or writing. Think about it, transaction A adds a write lock to the data, which means that it does not want other transactions to operate on the data. Then if other data can Adding a write lock to this data is equivalent to performing an operation on the data, which violates the meaning of the write lock and is naturally not allowed.
[Related recommendations: mysql video tutorial]
The above is the detailed content of What is mysql phantom reading?. For more information, please follow other related articles on the PHP Chinese website!




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



