
 Technology peripherals
AI
The image preprocessing library CV-CUDA is open sourced, breaking the preprocessing bottleneck and increasing inference throughput by more than 20 times.
Technology peripherals
AI
The image preprocessing library CV-CUDA is open sourced, breaking the preprocessing bottleneck and increasing inference throughput by more than 20 times.
The image preprocessing library CV-CUDA is open sourced, breaking the preprocessing bottleneck and increasing inference throughput by more than 20 times.

In today's information age, images or visual content have long become the most important carrier of information in daily life. Deep learning models rely on their strong ability to understand visual content and can Various processing and optimization.
However, in the past development and application of visual models, we paid more attention to the optimization of the model itself to improve its speed and effect. On the contrary, for the pre- and post-processing stages of images, little serious thought is given to how to optimize them. Therefore, when the computational efficiency of the model is getting higher and higher, looking back at the pre-processing and post-processing of the image, I did not expect that they have become the bottleneck of the entire image task.
In order to solve such bottlenecks, NVIDIA has joined hands with the ByteDance machine learning team to open source many image preprocessing operator libraries CV-CUDA. They can run efficiently on the GPU, and the operator speed can reach the speed of OpenCV (running on the CPU) About a hundred times. If we use CV-CUDA as the backend to replace OpenCV and TorchVision, the throughput of the entire inference can reach more than 20 times the original. In addition, not only is the speed improved, but also in terms of effect, CV-CUDA has been aligned with OpenCV in terms of calculation accuracy, so training and inference can be seamlessly connected, greatly reducing the workload of engineers.
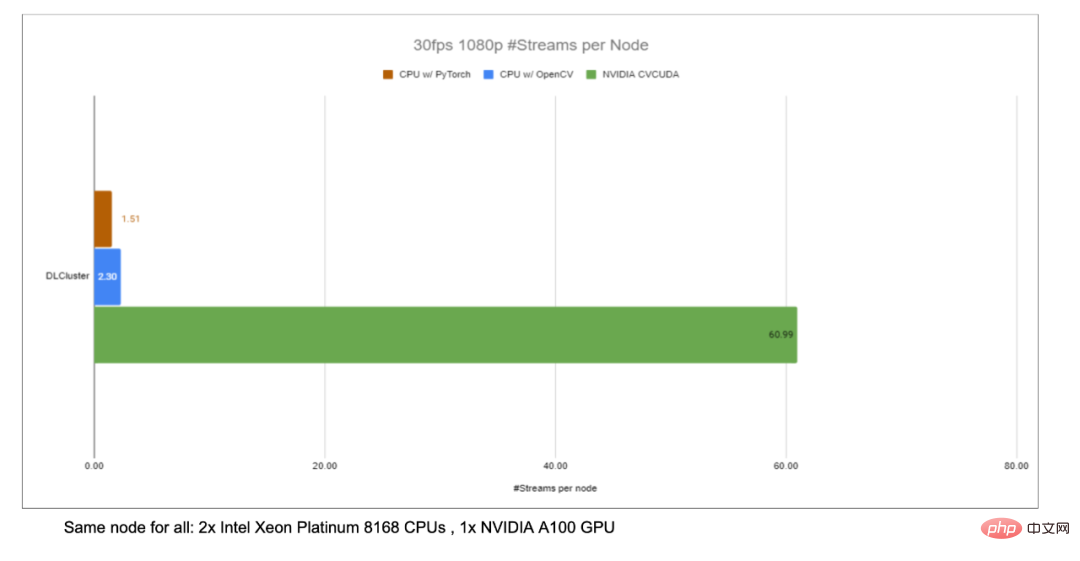
Taking the image background blur algorithm as an example, CV-CUDA replaces OpenCV as the backend for image pre/post-processing , the throughput of the entire reasoning process can be increased by more than 20 times.
#If you guys want to try a faster and better visual preprocessing library, you can try this open source tool. Open source address: https://github.com/CVCUDA/CV-CUDA
Image pre-/Post-processing has become CV Bottleneck
Many algorithm engineers involved in engineering and products know that although we often only discuss "cutting-edge research" such as model structure and training tasks, we actually need to In order to build a reliable product, you will encounter many engineering problems in the process, but model training is the easiest part.
Image preprocessing is such an engineering problem. We may simply call some APIs to perform geometric transformation, filtering, color transformation, etc. on the image during experiments or training, and we may not particularly care about it. But when we rethink the entire reasoning process, we find that image preprocessing has become a performance bottleneck, especially for visual tasks with complex preprocessing processes.
Such performance bottlenecks are mainly reflected in the CPU. Generally speaking, for conventional image processing processes, we will first perform preprocessing on the CPU, then put it on the GPU to run the model, and finally return to the CPU, and may need to do some post-processing.
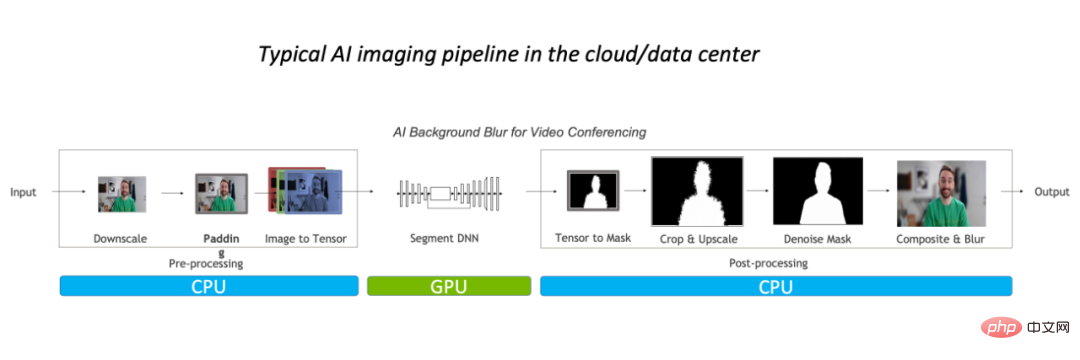
Take the image background blur algorithm as an example. In the conventional image processing process, prognosis processing is mainly completed on the CPU, occupying the entire 90% of the workload, it has become the bottleneck for the task.
So for complex scenes such as video applications or 3D image modeling, because the number of image frames or image information is large enough, the preprocessing process is complex enough, and If the latency requirement is low enough, optimizing the pre/post-processing operators is imminent. A better approach, of course, is to replace OpenCV with a faster solution.
Why OpenCV is still not good enough?
In CV, the most widely used image processing library is of course the long-maintained OpenCV. It has a very wide range of image processing operations and can basically meet various visual tasks. pre/post-processing required. However, as the load of image tasks increases, its speed has slowly been unable to keep up, because most of OpenCV's image operations are implemented by the CPU, lacking GPU implementation, or there are some problems with the GPU implementation.
In the research and development experience of NVIDIA and ByteDance algorithm students, they found that there are three major problems in the few operators implemented by GPU in OpenCV:
- The CPU and GPU result accuracy of some operators cannot be aligned;
- The GPU performance of some operators is weaker than the CPU performance;
- There are various CPU operators and various GPU operators at the same time. When the processing process needs to use both at the same time, additional space applications and requirements in memory and video memory are added. Data migration/data copy;
For example, the accuracy of the results of the first question cannot be aligned. NVIDIA and ByteDance algorithm students will find that when we During training, a certain operator of OpenCV uses the CPU, but due to performance issues during the inference phase, the GPU operator corresponding to OpenCV is used instead. Perhaps the accuracy of the CPU and GPU results cannot be aligned, resulting in accuracy anomalies in the entire inference process. When such a problem occurs, you either need to switch back to the CPU implementation, or you need to spend a lot of effort to realign the accuracy, which is a difficult problem to deal with.
Since OpenCV is still not good enough, some readers may ask, what about Torchvision? It will actually face the same problems as OpenCV. In addition, engineers deploying models are more likely to use C to implement the inference process for efficiency. Therefore, they will not be able to use Torchvision and need to turn to a C vision library such as OpenCV. This will bring Another dilemma: aligning the accuracy of Torchvision with OpenCV.
In general, the current pre/post-processing of visual tasks on the CPU has become a bottleneck, but traditional tools such as OpenCV cannot handle it well. Therefore, migrating operations to the GPU, and using CV-CUDA, an efficient image processing operator library implemented entirely based on CUDA, has become a new solution.
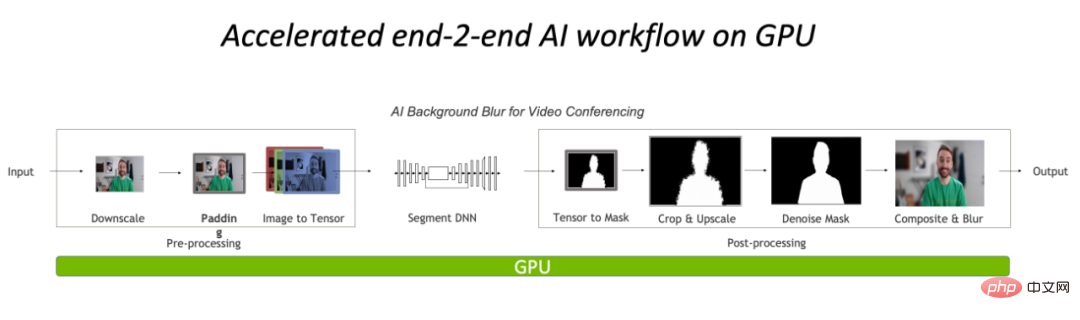
Performing pre-processing and post-processing entirely on the GPU will greatly reduce the CPU bottleneck in the image processing part.
GPU Image processing acceleration library: CV-CUDA
As a CUDA-based pre-processor / Post-processing operator library, algorithm engineers may look forward to three things most: fast enough, versatile enough, and easy to use. CV-CUDA, jointly developed by NVIDIA and ByteDance's machine learning team, can exactly meet these three points. It uses the parallel computing power of the GPU to improve operator speed, aligns OpenCV operation results to be versatile enough, and is easy to use with the C/Python interface.
speed of CV-CUDA
CV-CUDA The speed is first reflected in the efficient operator implementation. After all, it is written by NVIDIA. The CUDA parallel computing code must have undergone a lot of optimization. Secondly, it supports batch operations, which can make full use of the computing power of the GPU device. Compared with the serial execution of images on the CPU, batch operations are definitely much faster. Finally, thanks to the GPU architectures such as Volta, Turing, and Ampere that CV-CUDA is adapted to, the performance is highly optimized at the CUDA kernel level of each GPU to achieve the best results. In other words, the better the GPU card you use, the more exaggerated its acceleration capabilities will be.
As shown in the previous background blur throughput acceleration ratio chart, if CV-CUDA is used to replace the pre- and post-processing of OpenCV and TorchVision, the throughput of the entire inference process is increased by more than 20 times. Among them, preprocessing performs operations such as Resize, Padding, and Image2Tensor on the image, and postprocessing performs operations such as Tensor2Mask, Crop, Resize, and Denoise on the prediction results.
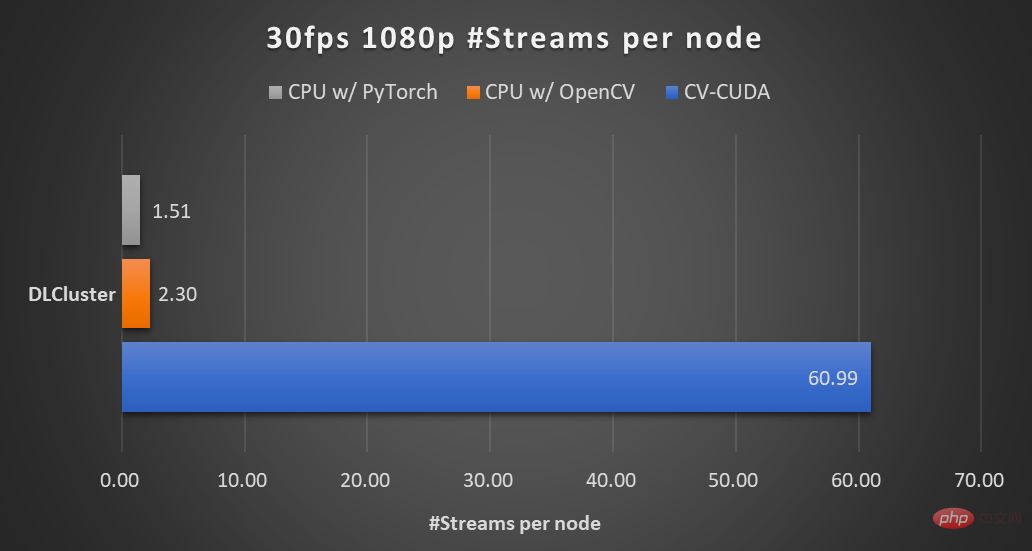
On the same compute node (2x Intel Xeon Platinum 8168 CPUs, 1x NVIDIA A100 GPU), Processes 1080p video at 30fps, using the maximum number of parallel streams supported by different CV libraries. The test used 4 processes, each process batchSize is 64. Regarding the performance of a single operator, NVIDIA and ByteDance’s partners have also conducted performance tests. The throughput of many operators on the GPU can reach a hundred times that of the CPU. .
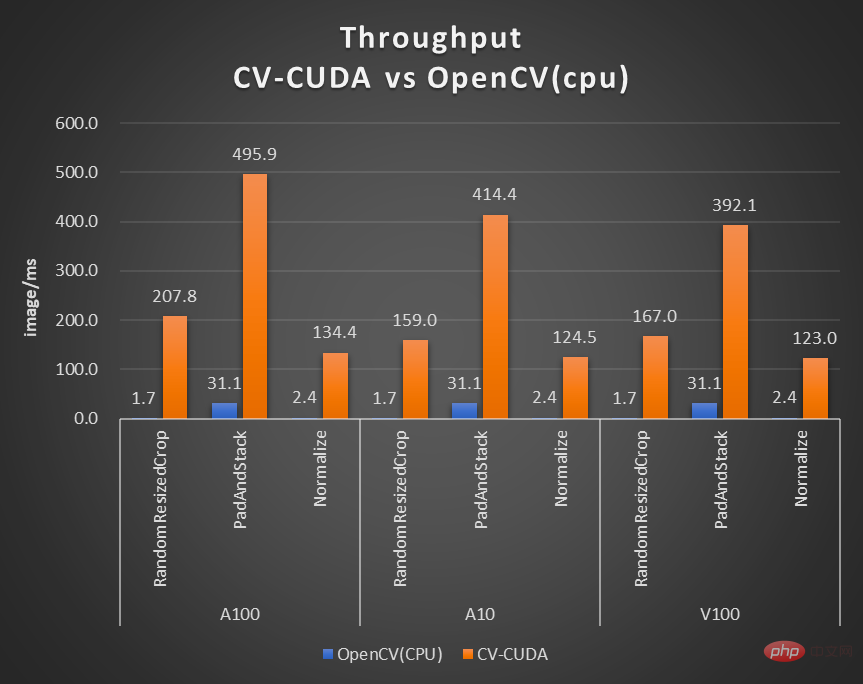
The image size is 480*360, the CPU is Intel(R) Core(TM) i9-7900X, the BatchSize size is 1, and the number of processes is 1
Although many pre/post-processing operators are not simple matrix multiplication and other operations, in order to achieve the above-mentioned efficient performance, CV-CUDA has actually done a lot of optimization at the operator level. For example, a large number of kernel fusion strategies are adopted to reduce the access time of kernel launch and global memory; memory access is optimized to improve data reading and writing efficiency; all operators are processed asynchronously to reduce the time of synchronous waiting, etc.
##CV-CUDA’s universal and flexible
operations The stability of the results is very important for actual projects. For example, the common Resize operation, OpenCV, OpenCV-gpu and Torchvision are implemented in different ways, so from training to deployment, there will be a lot more work to align the results. At the beginning of the design of CV-CUDA, it was considered that many engineers are accustomed to using the CPU version of OpenCV in the current image processing library. Therefore, when designing operators, whether it is function parameters or image processing results, align OpenCV as much as possible CPU version of the operator. Therefore, when migrating from OpenCV to CV-CUDA, only a few changes are needed to obtain consistent computing results, and the model does not need to be retrained.
In addition, CV-CUDA is designed from the operator level, so no matter what the pre/post-processing process of the model is, it can be freely combined and has high flexibility.
The ByteDance machine learning team stated that there are many models trained within the enterprise, and the required preprocessing logic is also diverse, with many customized preprocessing logic requirements. The flexibility of CV-CUDA can ensure that each OP supports the incoming of stream objects and video memory objects (Buffer and Tensor classes, which store video memory pointers internally), so that corresponding GPU resources can be configured more flexibly. When designing and developing each op, we not only take into account versatility, but also provide customized interfaces on demand, covering various needs for image preprocessing.
CV-CUDA’s ease of use
may be a lot Engineers will think, CV-CUDA involves the underlying CUDA operator, so it should be more difficult to use? But this is not the case. Even if it does not rely on higher-level APIs, the bottom layer of CV-CUDA itself will provide structures such as and the Allocator class, so it is not troublesome to adjust it in C. In addition, going to the upper level, CV-CUDA provides data conversion interfaces for PyTorch, OpenCV and Pillow, so engineers can quickly replace and call operators in a familiar way. In addition, because CV-CUDA has both a C interface and a Python interface, it can be used in both training and service deployment scenarios. The Python interface is used to quickly verify model capabilities during training, and the C interface is used for more efficient deployment. predict. CV-CUDA avoids the cumbersome preprocessing result alignment process and improves the efficiency of the overall process.
CV-CUDA C interface for Resize
Practical combat,CV-CUDAHow to use
If we use the Python interface of CV-CUDA during the training process, it will actually be very simple to use. , it only takes a few simple steps to migrate all preprocessing operations originally performed on the CPU to the GPU. Taking image classification as an example, basically we need to decode the image into a tensor in the preprocessing stage and crop it to fit the model input size. After cropping, we need to convert the pixel value into a floating point data type and After normalization, it can be passed to the deep learning model for forward propagation. Below we will use some simple code blocks to experience how CV-CUDA preprocesses images and interacts with Pytorch.

Conventional image recognition pre-processing process, using CV-CUDA will unify the pre-processing process and model calculation Run on GPU.
As follows, after using the torchvision API to load images to the GPU, the Torch Tensor type can be directly converted into the CV-CUDA object nvcvInputTensor through as_tensor, so that the API of the CV-CUDA preprocessing operation can be directly called. Various transformations of images are completed in the GPU.
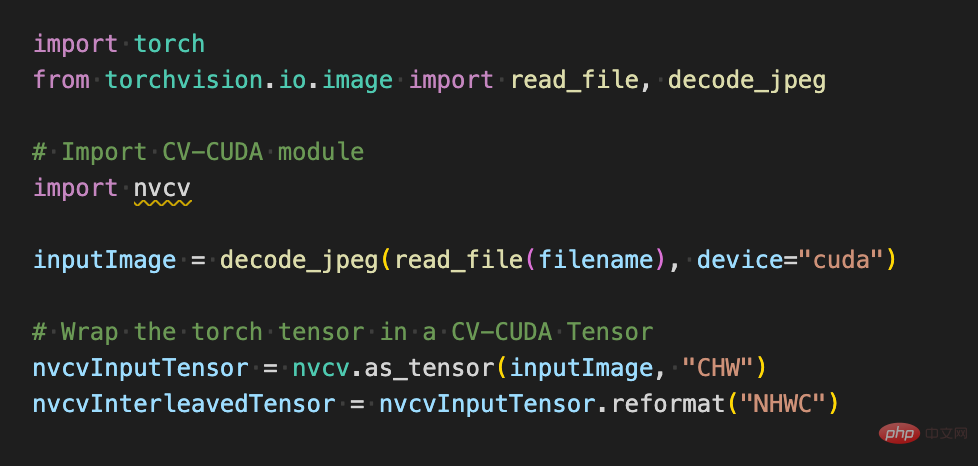
##The following lines of code will use CV-CUDA to complete the preprocessing process of image recognition in the GPU: crop the image and Normalize the pixels. Among them, resize() converts the image tensor into the input tensor size of the model; convertto() converts the pixel value into a single-precision floating point value; normalize() normalizes the pixel value to make the value range more suitable for the model. train. CV-CUDA The use of various preprocessing operations will not be much different from those in OpenCV or Torchvision. It is just a simple adjustment of the method, and the operation has already been completed on the GPU behind it.
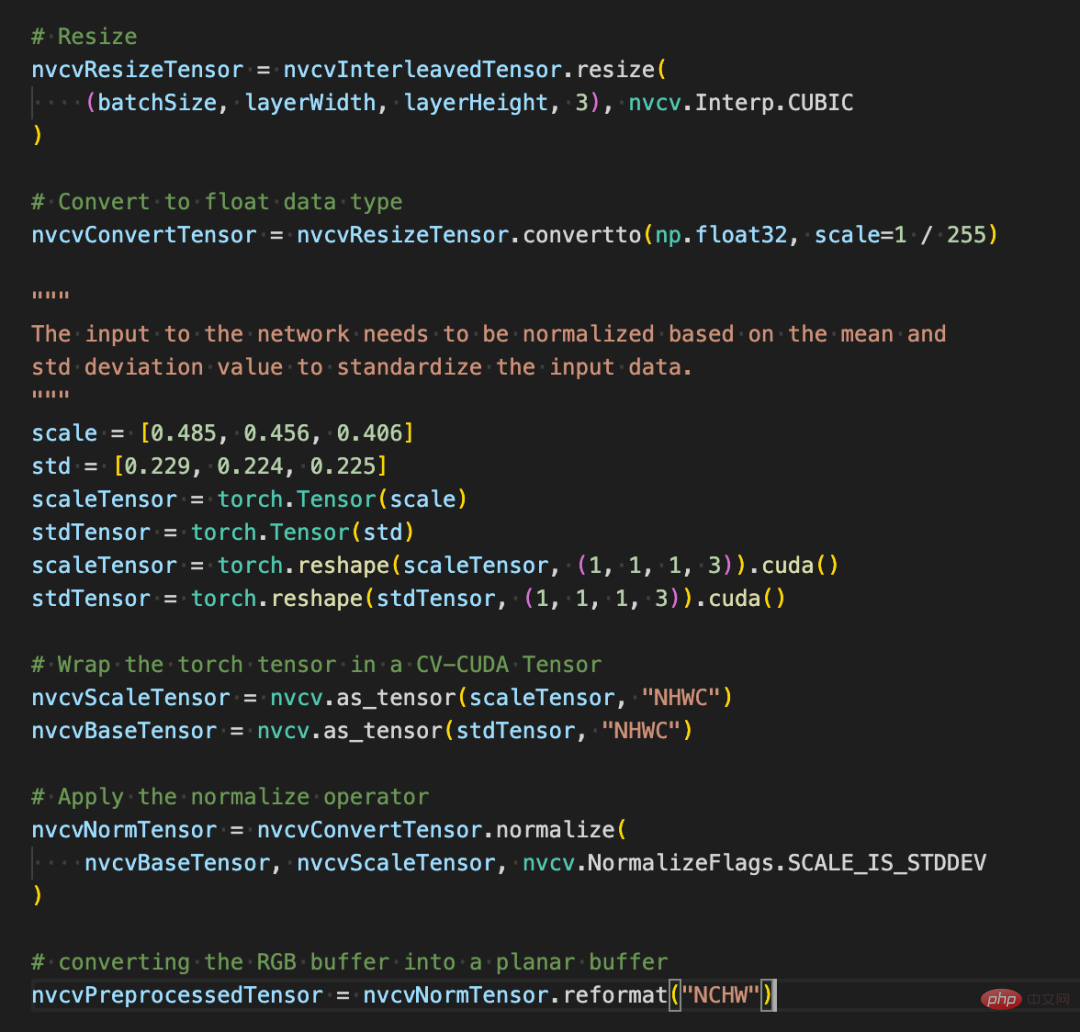
Now with the help of various APIs of CV-CUDA, the preprocessing of the image classification task has been completed. It can efficiently complete parallel computing on GPU and be easily integrated into the modeling process of mainstream deep learning frameworks such as PyTorch. For the rest, you only need to convert the CV-CUDA object nvcvPreprocessedTensor into the Torch Tensor type to feed it to the model. This step is also very simple. The conversion only requires one line of code:
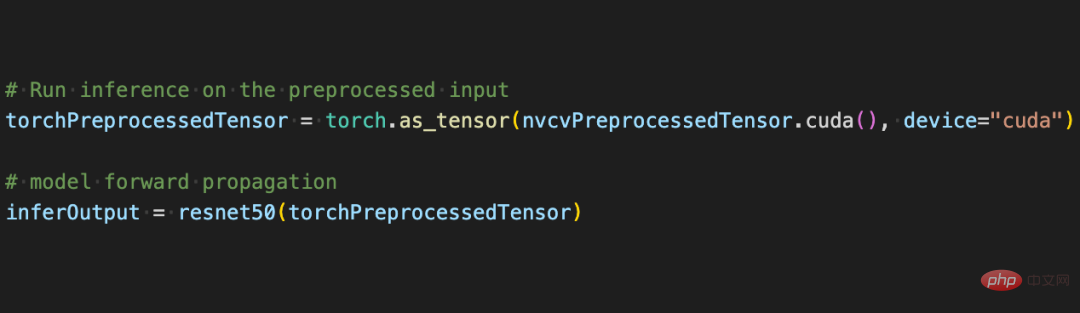
Through this simple example, it is easy to find that CV-CUDA is indeed easily embedded into normal model training logic. If readers want to know more usage details, they can still check the open source address of CV-CUDA mentioned above.
CV-CUDAImprovement of actual business
CV-CUDA has actually gone through actual business improvements test. In visual tasks, especially tasks with relatively complex image pre-processing processes, using the huge computing power of the GPU for pre-processing can effectively improve the efficiency of model training and inference. CV-CUDA is currently used in multiple online and offline scenarios within Douyin Group, such as multi-modal search, image classification, etc. The ByteDance machine learning team stated that the internal use of CV-CUDA can significantly improve the performance of training and inference. For example, in terms of training, ByteDance is a video-related multi-modal task. The pre-processing part includes the decoding of multi-frame videos and a lot of data enhancement, making this part of the logic very complicated. Complex preprocessing logic causes the multi-core performance of the CPU to still not keep up during training. Therefore, CV-CUDA is used to migrate all preprocessing logic on the CPU to the GPU, and the overall training speed is accelerated by 90%. Note that this is an increase in overall training speed, not just in the preprocessing part.
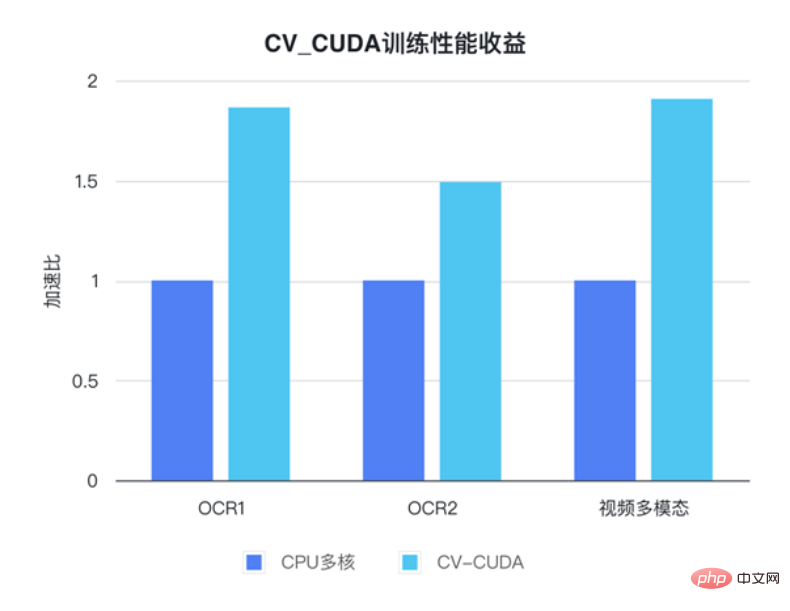
##In Bytedance OCR and video multi-modal tasks, by using CV-CUDA, the overall training speed can be Improved by 1 to 2 times (note: it is an increase in the overall training speed of the model)
The same is true in the inference process. The ByteDance machine learning team stated that in a After using CV-CUDA in the search multi-modal task, the overall online throughput has been improved by more than 2 times compared with using CPU for preprocessing. It is worth noting that the CPU baseline results here have been highly optimized for multi-core, and the preprocessing logic involved in this task is relatively simple, but the acceleration effect is still very obvious after using CV-CUDA. The speed is efficient enough to break the preprocessing bottleneck in visual tasks, and it is also simple and flexible to use. CV-CUDA has proven that it can greatly improve model reasoning and training effects in actual application scenarios, so if Readers' visual tasks are also limited by preprocessing efficiency, so try the latest open source CV-CUDA.
The above is the detailed content of The image preprocessing library CV-CUDA is open sourced, breaking the preprocessing bottleneck and increasing inference throughput by more than 20 times.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
Image annotation is the process of associating labels or descriptive information with images to give deeper meaning and explanation to the image content. This process is critical to machine learning, which helps train vision models to more accurately identify individual elements in images. By adding annotations to images, the computer can understand the semantics and context behind the images, thereby improving the ability to understand and analyze the image content. Image annotation has a wide range of applications, covering many fields, such as computer vision, natural language processing, and graph vision models. It has a wide range of applications, such as assisting vehicles in identifying obstacles on the road, and helping in the detection and diagnosis of diseases through medical image recognition. . This article mainly recommends some better open source and free image annotation tools. 1.Makesens
 Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Text annotation is the work of corresponding labels or tags to specific content in text. Its main purpose is to provide additional information to the text for deeper analysis and processing, especially in the field of artificial intelligence. Text annotation is crucial for supervised machine learning tasks in artificial intelligence applications. It is used to train AI models to help more accurately understand natural language text information and improve the performance of tasks such as text classification, sentiment analysis, and language translation. Through text annotation, we can teach AI models to recognize entities in text, understand context, and make accurate predictions when new similar data appears. This article mainly recommends some better open source text annotation tools. 1.LabelStudiohttps://github.com/Hu
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Face detection and recognition technology is already a relatively mature and widely used technology. Currently, the most widely used Internet application language is JS. Implementing face detection and recognition on the Web front-end has advantages and disadvantages compared to back-end face recognition. Advantages include reducing network interaction and real-time recognition, which greatly shortens user waiting time and improves user experience; disadvantages include: being limited by model size, the accuracy is also limited. How to use js to implement face detection on the web? In order to implement face recognition on the Web, you need to be familiar with related programming languages and technologies, such as JavaScript, HTML, CSS, WebRTC, etc. At the same time, you also need to master relevant computer vision and artificial intelligence technologies. It is worth noting that due to the design of the Web side
 Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Let me introduce to you the latest AIGC open source project-AnimagineXL3.1. This project is the latest iteration of the anime-themed text-to-image model, aiming to provide users with a more optimized and powerful anime image generation experience. In AnimagineXL3.1, the development team focused on optimizing several key aspects to ensure that the model reaches new heights in performance and functionality. First, they expanded the training data to include not only game character data from previous versions, but also data from many other well-known anime series into the training set. This move enriches the model's knowledge base, allowing it to more fully understand various anime styles and characters. AnimagineXL3.1 introduces a new set of special tags and aesthetics
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
