
 Technology peripherals
AI
Discuss the current status and development trends of autonomous driving trajectory prediction technology
Technology peripherals
AI
Discuss the current status and development trends of autonomous driving trajectory prediction technology
Discuss the current status and development trends of autonomous driving trajectory prediction technology

1 What is trajectory prediction
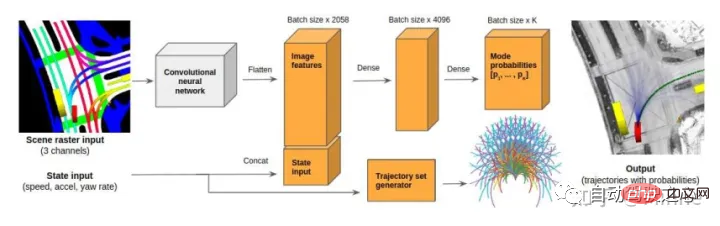
In autonomous driving, trajectory prediction is generally located at the back end of the perception module, and the front end of the control module is a connecting module. Input the state information and road structure information of the target track provided by the perception module, comprehensively consider high-precision map information, interaction information between targets, semantic information of the environment and intention information of the target, and make intentions for various perceived targets. Prediction (cut in/out, straight ahead) and trajectory prediction for a period of time in the future (ranging from 0-5s). As shown below.
ADAS system requires a certain cognitive ability of the surrounding environment information. The most basic level is to recognize the environment. The next level requires understanding the environment, and the next level requires Make predictions about the environment. After predicting the target, the controller can plan the path of the vehicle based on the predicted information, and make decisions to brake or issue warnings for possible dangerous situations. This is the significance of the trajectory prediction module.
2 Two challenges
## Trajectory prediction can be divided into short-term prediction and long-term prediction .
- Short-term prediction is generally based on the kinematic model (CV/CA/CTRV/CTRA) to predict the trajectory for a period of time in the future based on the current target state information. Generally
- Long-term forecasting is what the industry is currently doing. This kind of prediction is not suitable based only on the motion model. Generally, intention prediction is required and combined with some contextual information (map, interaction information between targets) to obtain good results. At this time, there are many different output forms in the industry, such as outputting the probability distribution of the trajectory, outputting multiple predicted trajectories, and outputting the most likely predicted trajectory.
There are two challenges for long-term trajectory prediction:
- Output a possible trajectory or output all possible trajectories The trajectories are all unreasonable. If you output a predicted trajectory, you may miss the real trajectory. If you output all possible trajectories, there will be false alarms. This is unacceptable for ADAS systems. Consideration should be given to limiting the predicted trajectories to a suitable subset.
- The more you do on trajectory prediction, the more assumptions you need to make. An extreme assumption is to assume that all objects on the road obey traffic rules. This is reasonable if used for traffic simulation functions, but is not suitable for ADAS systems, which need to be sensitive to potentially dangerous situations.
The uncertainty that affects long-term trajectory prediction mainly comes from three aspects:
- The output of the sensing module The target state estimate is uncertain.
- Uncertainty in driving intention prediction.
- The uncertainty between intent recognition and vehicle mobility changes.
3 Main considerations
Four issues that should be considered for the trajectory prediction system:
- Trajectory prediction must be sensitive to potential dangers, which is required by the meaning of trajectory prediction.
- It is necessary to consider both the running model and the information about the intention and surrounding environment.
- Consider the above uncertainties.
- Consider the number of output trajectories.
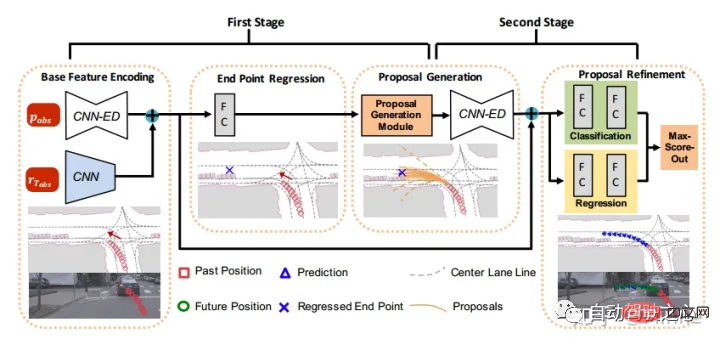
4 Industry method
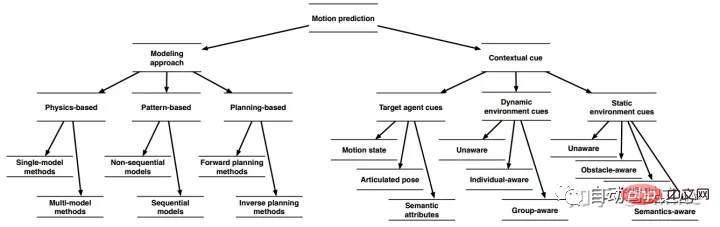
The following figure shows the classification method in the review paper [2] published by Bosch.
- If classified according to the different models used, trajectory prediction methods can be divided into methods using physical models, methods using learning, and methods using planning algorithms.
- If classified according to the information used, trajectory prediction methods can be divided into methods that use target information, methods that use dynamic target information in the environment, and methods that use static environment information.
What general algorithms are involved in trajectory prediction?
- Intention prediction: fuzzy theory, static BNs, DBN (HMM, JumpMM), DS evidence theory, classification algorithms in machine learning.
- Deep learning related, end-to-end output. CNN, LSTM, RNN, Attention.
#What specific information can be used for trajectory prediction?
- Target information: current/historical speed and position information. If it is pedestrian trajectory prediction, the orientation of the pedestrian's head, joint information, gender and age information can also be used. Human attention information.
- Dynamic target information in the environment: social force, attraction, group constraint information.
- Static environment information: free space, map, semantic information (road structure/traffic rules/current traffic lights).
#There are currently more and more papers on trajectory prediction in academia. The main reason is that there is no effective method in the industry.
The following are industry papers:
BMW: Physics Model intent prediction (learning-based). Heuristic methods are used to integrate expert knowledge, simplify the interaction model, and add game theory ideas to the classification model of intention prediction [3].
BENZ: Mainly related papers on intent prediction, using DBN[4] .
Uber: LaneRCNN[5].
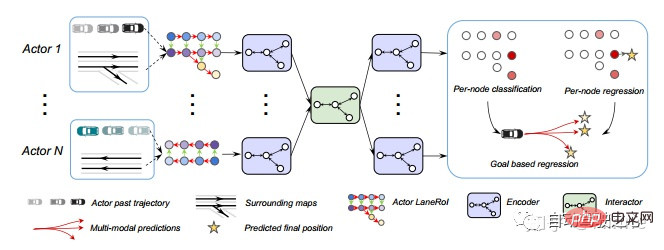
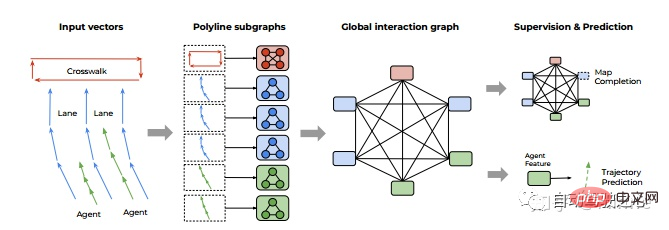
Google: VectorNet[6].
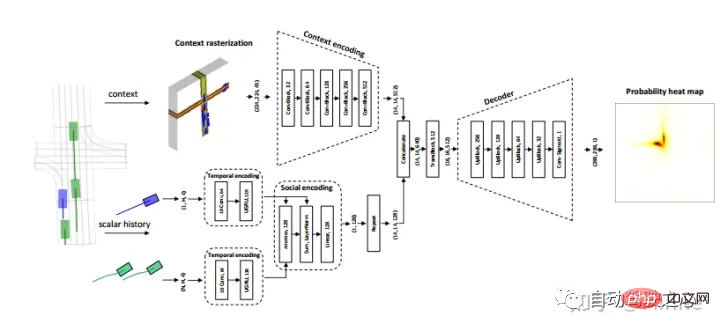
Huawei: HOME[7].
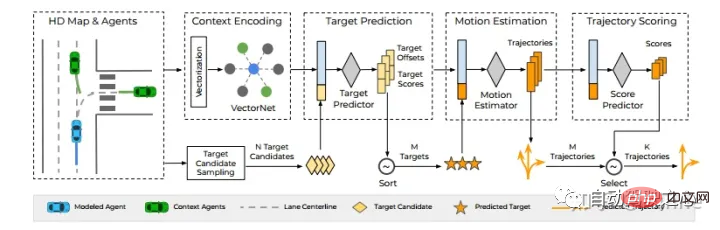
Waymo: TNT[8].
Aptive: Covernet[9].
NEC: R2P2[10].
SenseTime: TPNet[11].
Meituan: StarNet[12]. pedestrian.
Aibee: Sophie[13]. pedestrian.
MIT: Social lstm[14]. pedestrian.
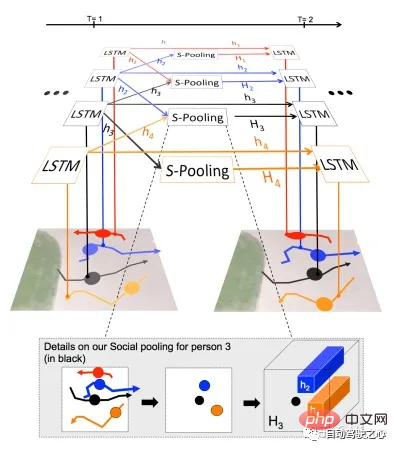
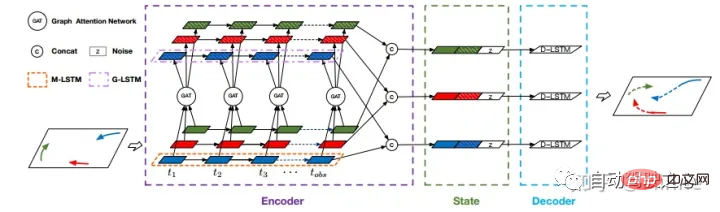
USTC: STGAT[15]. pedestrian.
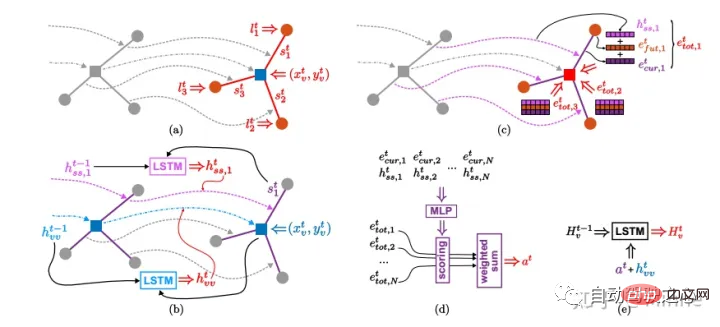
baidu: Lane-Attention[16].
##Apollo: You can read the following blog for reference.
https://www.cnblogs.com/liuzubing/p/11388485.html
Apollo’s prediction module receives perception, Positioning and map module input.
1. First, the scene was split into two scenes: ordinary cruising road and intersection.
2. Then divide the importance of the perceived targets into targets that can be ignored (will not affect your own car) and targets that need to be handled with caution (may affect your own car). rook) and normal targets (somewhere in between).
3. Then enter the Evaluator, which is essentially an intention prediction.

4. Finally enter the predictor, which is used to predict trajectory generation. Perform different operations for different scenarios such as stationary targets, driving along the road, freeMove, and intersections.

5 Dataset
(1) NGSIM
This data set is highway driving data collected by FHWA in the United States, including the driving status of all vehicles on US101, I-80 and other roads in a time period. The data is acquired using a camera and then processed into track point records one by one. Its data set is a CSV file. The data doesn't have much noise.
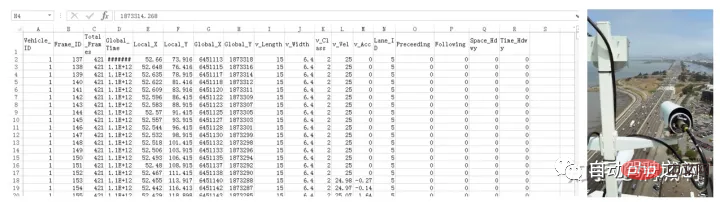
is more information at the overall dispatch level, such as road planning, lane setting, traffic flow adjustment, etc. The vehicle kinematic state needs to be further extracted. The processing code can be used on github below.
https://github.com/nachiket92/conv-social-pooling
##(2) INTERACTION
This dataset was created for the UC Berkeley Mechanical Systems Control Laboratory (MSC Lab) with collaborators from the Karlsruhe Institute of Technology (KIT) and the École Nationale Supérieure de Mines Paris (MINES ParisTech). International, adversarial, collaborative data set (INTERACTION). It can accurately reproduce a large number of interactive behaviors of road users (such as vehicles and pedestrians) in various driving scenarios in different countries.

##http://www.interaction-dataset.com/
(3)apolloscape
This is Apollo’s public autonomous driving data set, which contains data provided for trajectory prediction. The internal file is a 1min data sequence of 2fps. The data structure includes frame number ID, target ID, target category, position xyz, length, width, and height information, and heading. The target category includes small cars, large cars, pedestrians, bicycles/electric vehicles, and others.
https://apolloscape.auto/trajectory.html
(4) TRAF
This data set focuses on high-density traffic conditions. This condition can help the algorithm better focus on analyzing human driver behavior in uncertain environments. Each frame of data contains approximately 13 motor vehicles, 5 pedestrians and 2 bicycles
https://gamma.umd.edu/researchdirections/autonomousdriving/ad
There are many trajectory prediction projects using this dataset in the link.
(5) nuScenes
The big news is coming. This data set was proposed in April 2020. It collected 1,000 driving scenes in Boston and Singapore, two cities with heavy traffic and challenging driving conditions. Its data set has related papers, you can take a look to get a better understanding of this data set.
https://arxiv.org/abs/1903.11027
There are prediction-related competitions in this data set, you can pay attention to them.

https://www.nuscenes.org/prediction?externalData=all&mapData=all&modalities=Any
6 Evaluation Index
The currently mainly used evaluation index is the geometric metric.
Geometric measurement has many indicators, the main ones used are ADE, FDE, and MR.
ADE is the normalized Euclidean distance. FDE is the Euclidean distance between the final prediction points. MR is the miss rate. There are many different names. The main thing is to set a threshold. If the Euclidean distance between the predicted points is lower than this prediction, it will be recorded as a hit. If it is higher than this threshold, it will be recorded as a miss. Finally, a percentage will be calculated.
Geometric metric is an important indicator to measure the similarity between the predicted trajectory and the actual trajectory, and can well represent the accuracy. But for the purpose of trajectory prediction, it is meaningless to just evaluate the accuracy. There should also be probabilistic measures to evaluate uncertainty, especially for multi-modal output distributions; there should also be task-level measures, robustness measures, and efficiency evaluations.
Probability measure: KL divergence, predicted probability, and cumulative probability can be used as probability measure. For example, NLL, KDE-based NLL [17]. Task-level metrics: Evaluate the impact of trajectory prediction on back-end regulation (piADE, piFDE) [18]. Robustness: Consider the length or duration of the observed part of the trajectory before prediction; the size of the training data; input data sampling frequency and sensor noise; neural network generalization, overfitting and input utilization analysis; perception module If there is a problem with the input input, whether the function is guaranteed to be normal and other factors. Efficiency: Consider computing power.
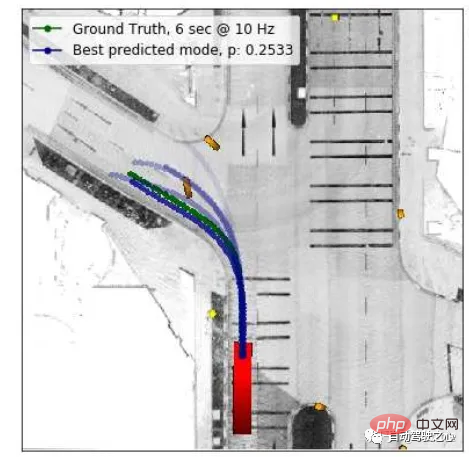
As shown in the figure below, the main consideration of this paper is that based on the true value (blue), the purple and green trajectories predicted by the gray target car have the same ADE and FDE if geometric metrics are used, but different The prediction method will have an impact on the planning of the own car, and there is currently no such metric for evaluating the task level, so they proposed piADE and piFDE to do this.
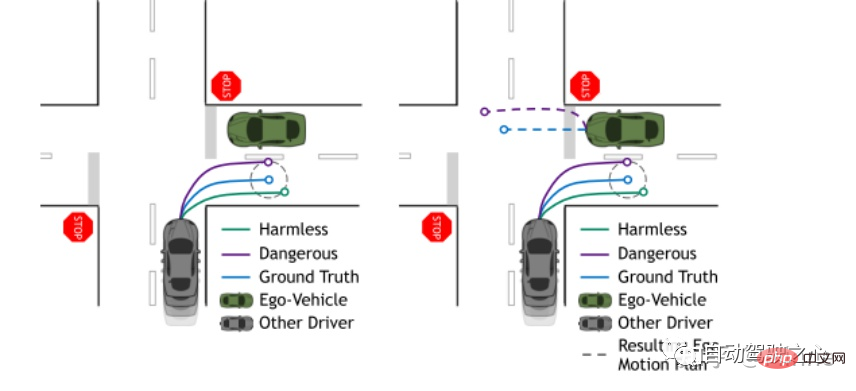
7 Three questions
Question 1: Three different trajectory prediction methods : Where are the application scenarios of physical model-based, learning-based, and planning-based? What are the advantages and disadvantages?
Different modeling methods can combine and exploit different types of contextual information. All modeling methods can be expanded by using the target's contextual clues and dynamic and static environments. However, different modeling methods exhibit different levels of complexity and efficiency in combining different categories of semantic information.
1. Physical model-based method
Applicable scenarios: targets, static environments, and dynamic simulations can be Explicit transfer equation modeling.
Advantages:
- Physically model-based methods can be easily applied across environments by selecting appropriate transfer equations, while No training data is required, although some data for parameter estimation is useful. In the paper, a simple CV model also produces reasonable results.
- The physical model-based method can be easily extended by combining it with target agent cues.
Disadvantages:
- This approach to explicit modeling may not capture the complexity of the real world well .
- The transfer equation lacks global information in space and time, resulting in the possibility of obtaining a local optimal solution.
#Such shortcomings limit the use of physical methods to short-term prediction or obstacle-free environments.
2. Learning-based method
Applicable scenarios: Suitable for current environments with complex unknown information (such as Common areas with rich semantics), and this information can be used for a relatively large prediction range.
Advantages:
- Learning-based methods can potentially handle all types of contextual information encoded in the collected data set. Some of them are map-based, and others can be used to further extend context information.
Disadvantages:
- Needs to collect enough data at a specific location for training.
- Contextual information expansion may lead to involved learning, data efficiency, and generalization issues.
- Tends to be used in non-safety critical components. In ADAS, interpretability is more important, which cannot be achieved based on learning methods.
3. Planning-based method
Applicable scenario: The end point is determined and the environment map is Available scenes, well represented.
Advantages:
- If the above two conditions are met, it can achieve better accuracy than physical methods and better than learning-based methods The method has better generalization ability.
shortcoming:
- Traditional planning algorithms: Dijkstra, Fast Marching Method, optimal sampling-based motion planners will grow exponentially as the number of targets, the size of the environment, and the prediction range increase.
- Compared with simple physics-based models, the parameters of context-cue-based planning methods (such as reward functions for inverse programming and models for forward programming) are trivial and generally easier to learn , but in terms of reasoning, it is less efficient for high-dimensional (target) agent states.
Planning-based methods are essentially map-aware and abstacle-aware, and naturally extend using semantic clues. Typically, they encode situational complexity into the goal/reward equation, but this may not properly integrate dynamic line inputs. Therefore, the authors had to design specific modifications to incorporate dynamic input into the prediction algorithm (Jump Markov Processes, local adaptations of the predicted trajectory, game-theoretic). Unlike learning-based methods, target inputs can be easily merged because both forward and backward planning processes are based on the same target dynamic model.
Question 2: Has the problem of trajectory prediction been solved now?
#The need for trajectory prediction largely depends on the application domain and the specific use case scenarios therein. It may not be said that the problem of trajectory prediction has been solved in the short term. Take the automotive industry as an example. Because there are special standards and regulations that define maximum speeds, traffic rules, distribution of pedestrian speeds and accelerations, and specifications for comfortable acceleration/deceleration rates of vehicles, it seems to be the most powerful in formulating requirements and proposing solutions. Mature. It can be said that for the AEB function of smart cars, the solution has reached a performance level that allows industrial production of consumer products, and its required use cases have been solved. As for other use cases, more standardization and clear articulation of requirements will be needed in the near future. And robustness and stability still need to evolve.
So before answering the question of whether trajectory prediction has solved this problem, we should at least set the standard.
Currently in the field of robotics
- methods based on physical models and learning can be implemented in a short time (1-2s) Higher accuracy. It is very suitable for local motion planning and collision avoidance of crowds. The simplest CV model has a good effect on the local planning of the robot. If you consider the interaction between pedestrians and the impact of the presence of robots on pedestrian movements, there are many advanced algorithms.
- There are great challenges for global path planning that requires prediction of 15-20 seconds. The requirements can be relaxed appropriately, and it becomes very important to understand the dynamic and static context input (which affects the operation in the long term, reasoning on the environment map, and the intention inference of the target). For local and global path planning, position-independent methods are best suited for predicting motion in various environments.
- The current robot predicts that the ADE in 4.8s is 0.19-0.4m. A simple velocity model can also achieve an ADE of 0.53m. 9s predicts an ADE of 1.4-2m.
Currently in the field of autonomous driving:
- Most work considers pedestrians crossing the road : Start walking, keep walking, stop walking.
- Bicycle: A cyclist approaches an intersection with up to five different directions of road behind them.
# Question 3: Are current evaluation techniques for measuring trajectory prediction performance good enough?
There is currently a lack of systematic approaches to prediction algorithms, especially for trajectory prediction methods that consider contextual inputs and predict an arbitrary number of targets.
Now most authors only use geometric measures (AED, FDE) as an indicator to measure the quality of an algorithm. For long-term predictions, however, the predictions are often multimodal and associated with uncertainty, and performance evaluation of such methods should use metrics that take this into account, such as the negative log-likelihood or logarithm obtained from KLD loss.
There is also a need for probabilistic measures that better reflect the randomness of human motion and the uncertainty involved in perceptual imperfections.
There is also robustness evaluation, which needs to consider the stability of the system when detection errors, tracking defects, self-positioning uncertainty or map changes occur on the sensing side.
At the same time, although the currently used data sets include very comprehensive scenarios, these data sets are usually semi-automatically annotated, and therefore can only provide incomplete and noisy true value estimates. Furthermore, trajectory length is often insufficient in some application areas where long-term predictions are required. Finally, the interaction between targets in the data set is usually limited. For example, in a sparse environment, it is difficult for targets to influence each other.
In summary: In order to evaluate the prediction quality, researchers should choose more complex data sets (including non-convex obstacles, long trajectories and complex interactions) and complete metrics (geometric probability). A better method is to set different accuracy requirements based on different prediction times, different observation periods, and different scene complexities. And there should be robustness evaluation and real-time evaluation. In addition, there should be relevant indicators that can measure the impact of ADAS systems on the backend [18] and indicators that measure sensitivity to hazardous scenarios [1].
8 Future Directions
From the discussion in [2], quoted here.
The current trend is to use more complex methods to go beyond using a single model KF method
Direction:
- Use enhanced contextual information: Deeper semantic information can be used, which should provide a better understanding of static environments. And the current use of semantic features for trajectory prediction still needs to be developed
- Regarding socially-aware scenarios: ① Most current methods assume that the behaviors of all observed people are similar , their movements can be predicted by the same model and the same features, while the capture and reasoning of high-level social attributes are still in the early stages of development. ② Most feasible methods are based on the assumption that cooperative behavior between people, and real people may be more inclined to optimize individual goals rather than joint strategies, so methods combined with traditional AI game theory are very promising.
- For long-term predictions, contextual information becomes particularly important as intent is considered based on context and surrounding circumstances. Many current learning-based methods treat individuals as particles and use them to learn to transfer information to determine the direction of future movement. Extending these models with more intent-driven predictions, similar to human goal-directed behavior, will benefit long-term predictions.
- Most planning-based methods rely on a given set of goals, which makes them unusable or inappropriate without prior knowledge of the destinations or where the number of destinations may be too high. accurate. This makes automatic inference of destination endpoints based on semantic information important. Or it can dynamically identify possible destinations in the environment and perform trajectory prediction based on this. This allows planning-based methods to be used in unknown environments.
- Current methods focus on solving a specific type of task, such as when there is an obvious movement pattern in the environment, or when the spatial structure of the environment and the destination of the target agent When known in advance. Trajectory prediction methods need to be able to adapt to undefined/changing environments and handle unexpected situations. This requires transfer learning and some methods of coping with new environments, where learning and reasoning about basic immutable rules, or general pedestrian behavior or collision avoidance is not appropriate. Domain adaptation can be used to learn generalization models.
- Another direction to pay attention to: robustness and integrability.
To sum up: To put it simply, the context information should be used more deeply, it is best to have different behavioral models and game theory for different goals, and make more decisions based on more information. Excellent intent prediction, automatic inference of endpoints, generalization problems to new environments, robustness and integrability.
The above is the detailed content of Discuss the current status and development trends of autonomous driving trajectory prediction technology. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 CUDA's universal matrix multiplication: from entry to proficiency!
Mar 25, 2024 pm 12:30 PM
CUDA's universal matrix multiplication: from entry to proficiency!
Mar 25, 2024 pm 12:30 PM
General Matrix Multiplication (GEMM) is a vital part of many applications and algorithms, and is also one of the important indicators for evaluating computer hardware performance. In-depth research and optimization of the implementation of GEMM can help us better understand high-performance computing and the relationship between software and hardware systems. In computer science, effective optimization of GEMM can increase computing speed and save resources, which is crucial to improving the overall performance of a computer system. An in-depth understanding of the working principle and optimization method of GEMM will help us better utilize the potential of modern computing hardware and provide more efficient solutions for various complex computing tasks. By optimizing the performance of GEMM
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Huawei's Qiankun ADS3.0 intelligent driving system will be launched in August and will be launched on Xiangjie S9 for the first time
Jul 30, 2024 pm 02:17 PM
Huawei's Qiankun ADS3.0 intelligent driving system will be launched in August and will be launched on Xiangjie S9 for the first time
Jul 30, 2024 pm 02:17 PM
On July 29, at the roll-off ceremony of AITO Wenjie's 400,000th new car, Yu Chengdong, Huawei's Managing Director, Chairman of Terminal BG, and Chairman of Smart Car Solutions BU, attended and delivered a speech and announced that Wenjie series models will be launched this year In August, Huawei Qiankun ADS 3.0 version was launched, and it is planned to successively push upgrades from August to September. The Xiangjie S9, which will be released on August 6, will debut Huawei’s ADS3.0 intelligent driving system. With the assistance of lidar, Huawei Qiankun ADS3.0 version will greatly improve its intelligent driving capabilities, have end-to-end integrated capabilities, and adopt a new end-to-end architecture of GOD (general obstacle identification)/PDP (predictive decision-making and control) , providing the NCA function of smart driving from parking space to parking space, and upgrading CAS3.0
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Which version of Apple 16 system is the best?
Mar 08, 2024 pm 05:16 PM
Which version of Apple 16 system is the best?
Mar 08, 2024 pm 05:16 PM
The best version of the Apple 16 system is iOS16.1.4. The best version of the iOS16 system may vary from person to person. The additions and improvements in daily use experience have also been praised by many users. Which version of the Apple 16 system is the best? Answer: iOS16.1.4 The best version of the iOS 16 system may vary from person to person. According to public information, iOS16, launched in 2022, is considered a very stable and performant version, and users are quite satisfied with its overall experience. In addition, the addition of new features and improvements in daily use experience in iOS16 have also been well received by many users. Especially in terms of updated battery life, signal performance and heating control, user feedback has been relatively positive. However, considering iPhone14
