
 Technology peripherals
AI
New DeepMind research: transformer can improve itself without human intervention
Technology peripherals
AI
New DeepMind research: transformer can improve itself without human intervention
New DeepMind research: transformer can improve itself without human intervention

Currently, Transformers have become a powerful neural network architecture for sequence modeling. A notable property of pretrained transformers is their ability to adapt to downstream tasks through cue conditioning or contextual learning. After pre-training on large offline datasets, large-scale transformers have been shown to efficiently generalize to downstream tasks in text completion, language understanding, and image generation.
Recent work has shown that transformers can also learn policies from offline data by treating offline reinforcement learning (RL) as a sequential prediction problem. Work by Chen et al. (2021) showed that transformers can learn single-task policies from offline RL data through imitation learning, and subsequent work showed that transformers can extract multi-task policies in both same-domain and cross-domain settings. These works all demonstrate a paradigm for extracting general multi-task policies, i.e. first collecting large-scale and diverse environmental interaction data sets, and then extracting policies from the data through sequential modeling. This method of learning policies from offline RL data through imitation learning is called offline policy distillation (Offline Policy Distillation) or policy distillation (Policy Distillation, PD).
PD offers simplicity and scalability, but one of its major drawbacks is that the generated policies do not progressively improve with additional interactions with the environment. For example, Google's generalist agent Multi-Game Decision Transformers learned a return-conditioned policy that can play many Atari games, while DeepMind's generalist agent Gato learned a solution to diverse problems through contextual task reasoning. Strategies for tasks in the environment. Unfortunately, neither agent can improve the policy in context through trial and error. Therefore, the PD method learns policies rather than reinforcement learning algorithms.
In a recent DeepMind paper, researchers hypothesized that the reason PD failed to improve through trial and error was that the data used for training could not show learning progress. Current methods either learn a policy from data that does not contain learning (e.g. fixed expert policy via distillation) or learn a policy from data that does contain learning (e.g. the replay buffer of an RL agent), but the context size of the latter (too Small) Failure to capture policy improvements.

##Paper address: https://arxiv.org/pdf/2210.14215.pdf
The researchers’ main observation is that the sequential nature of learning in the training of RL algorithms allows, in principle, to model reinforcement learning itself as a causal sequence prediction problem. Specifically, if the context of a transformer is long enough to include the policy improvements brought about by learning updates, then it should not only be able to represent a fixed policy, but also be able to represent a policy improvement algorithm by focusing on the states, actions, and rewards of previous episodes. son. This opens up the possibility that any RL algorithm can be distilled into sufficiently powerful sequence models such as transformers through imitation learning, and these models can be converted into contextual RL algorithms.
The researchers proposed Algorithm Distillation (AD), which is an improved operator for learning contextual strategies by optimizing the causal sequence prediction loss in the RL algorithm learning history. Methods. As shown in Figure 1 below, AD consists of two parts. A large multi-task dataset is first generated by saving the training history of an RL algorithm on a large number of individual tasks, and then the transformer model causally models actions by using the previous learning history as its context. Because the policy continues to improve during the training of the source RL algorithm, AD has to learn improved operators in order to accurately model the actions at any given point in the training history. Crucially, the transformer context must be large enough (i.e., across-episodic) to capture improvements in the training data.
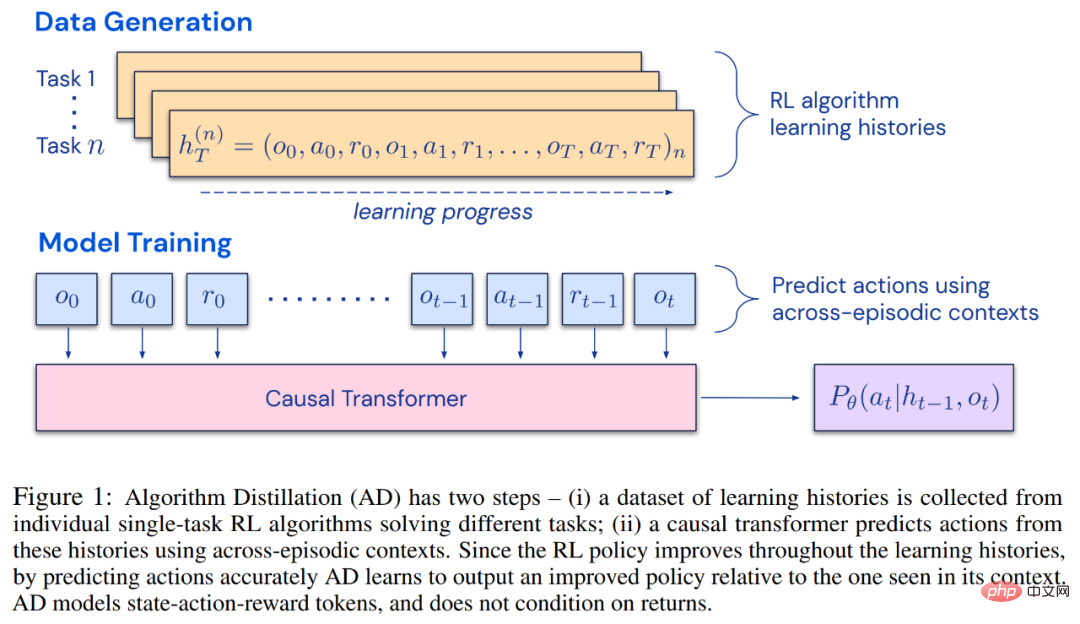
The researchers stated that by using a causal transformer with a large enough context to imitate the gradient-based RL algorithm, AD can fully strengthen new tasks in the context. study. We evaluated AD in a number of partially observable environments requiring exploration, including pixel-based Watermaze from DMLab, and showed that AD is capable of contextual exploration, temporal confidence assignment, and generalization. Additionally, the algorithm learned by AD is more efficient than the algorithm that generated the transformer training source data.
Finally, it is worth noting that AD is the first method to demonstrate contextual reinforcement learning by sequentially modeling offline data with imitation loss.
Method
During its lifetime, a reinforcement learning agent needs to perform well at performing complex actions. For an intelligent agent, regardless of its environment, internal structure and execution, it can be regarded as completed on the basis of past experience. It can be expressed in the following form:
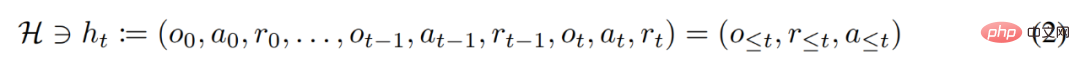
The researcher also regarded the "long history-conditioned" strategy as an algorithm and concluded:

where Δ(A) represents the probability distribution space on action space A. Equation (3) shows that the algorithm can be unfolded in the environment to generate sequences of observations, rewards, and actions. For the sake of simplicity, this study represents the algorithm as P and the environment (i.e. task) as  . The learning history is represented by the algorithm
. The learning history is represented by the algorithm  , so that for any given task
, so that for any given task 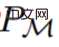 Generated. You can get
Generated. You can get
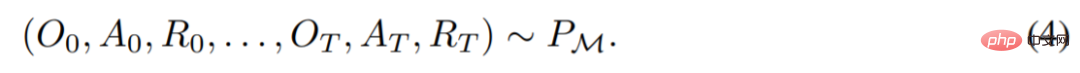
The researcher uses uppercase Latin letters to represent random variables, such as O, A, R and their corresponding lowercase forms o, α, r . By viewing algorithms as long-term history-conditioned policies, they hypothesized that any algorithm that generates a learning history can be converted into a neural network by performing behavioral cloning of actions. Next, the study proposes an approach that provides agents with lifetime learning of sequence models with behavioral clones to map long-term history to action distributions.
Practical implementation
In practice, this research implements algorithm distillation (AD) as a two-step process. First, a learning history dataset is collected by running individual gradient-based RL algorithms on many different tasks. Next, a sequence model with multi-episode context is trained to predict actions in history. The specific algorithm is as follows:

Experiment
The experiment requires that the environment used supports many tasks that cannot be obtained from Inferences are easily made from observations, and episodes are short enough to efficiently train cross-episode causal transformers. The main aim of this work was to investigate the extent to which AD reinforcement is learned in context relative to previous work. The experiment compared AD, ED (Expert Distillation), RL^2, etc.
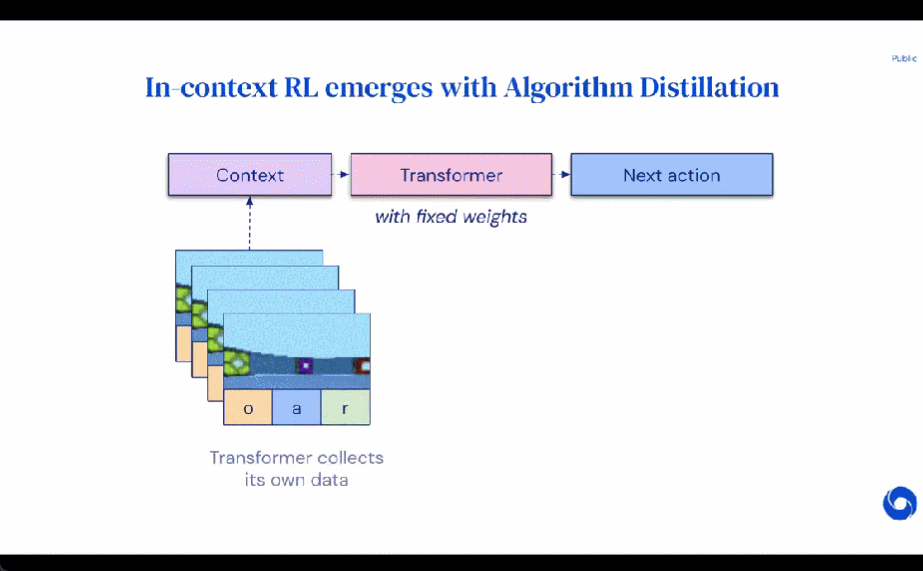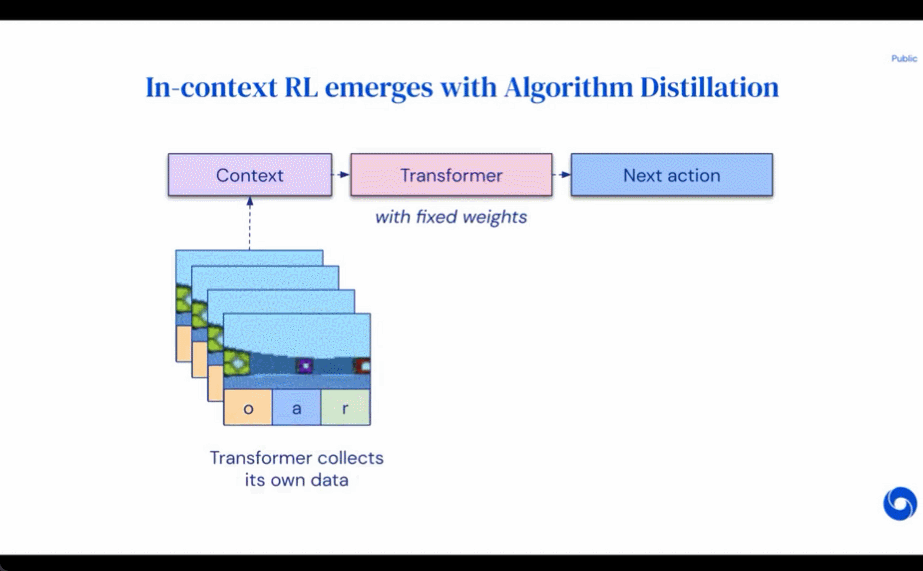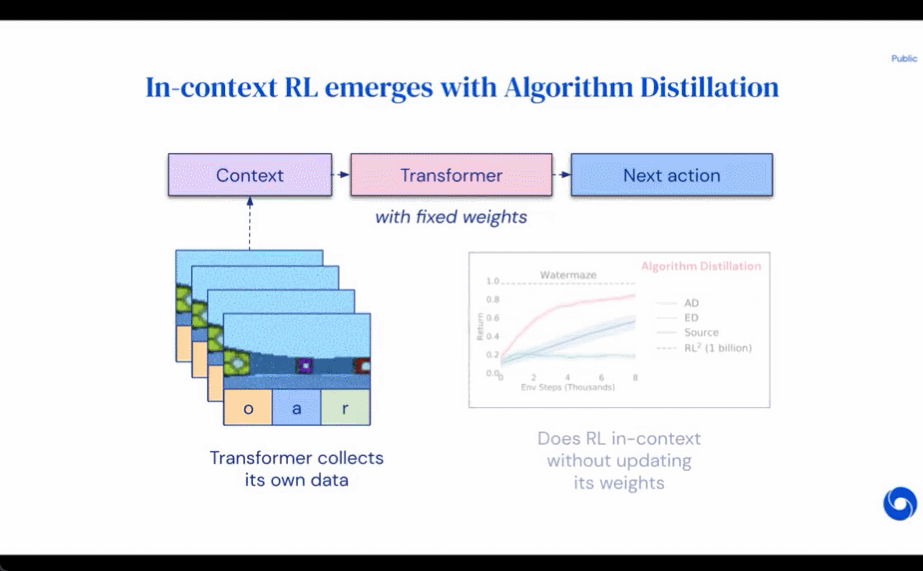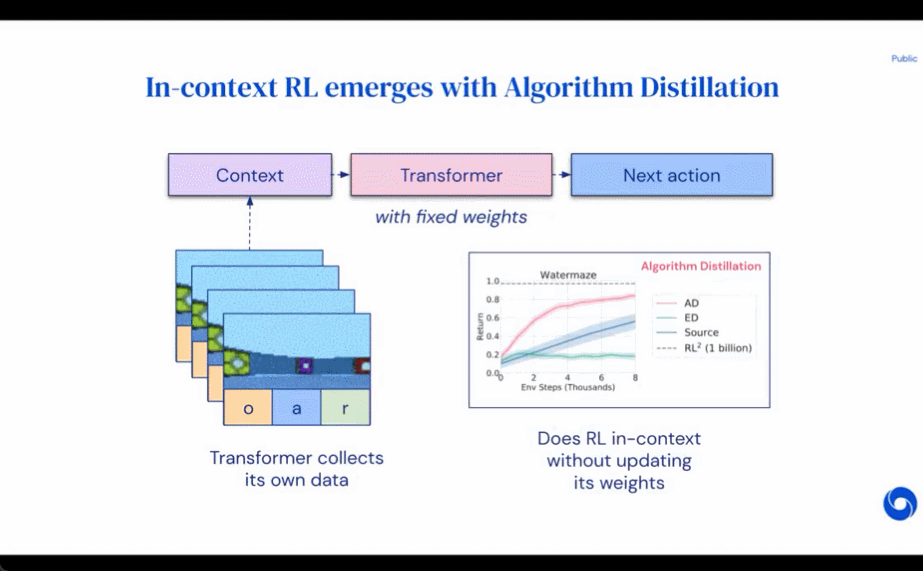
The results of evaluating AD, ED, and RL^2 are shown in Figure 3. The study found that both AD and RL^2 can learn contextually on tasks sampled from a training distribution, while ED cannot, although ED does do better than random guessing when evaluated within a distribution.
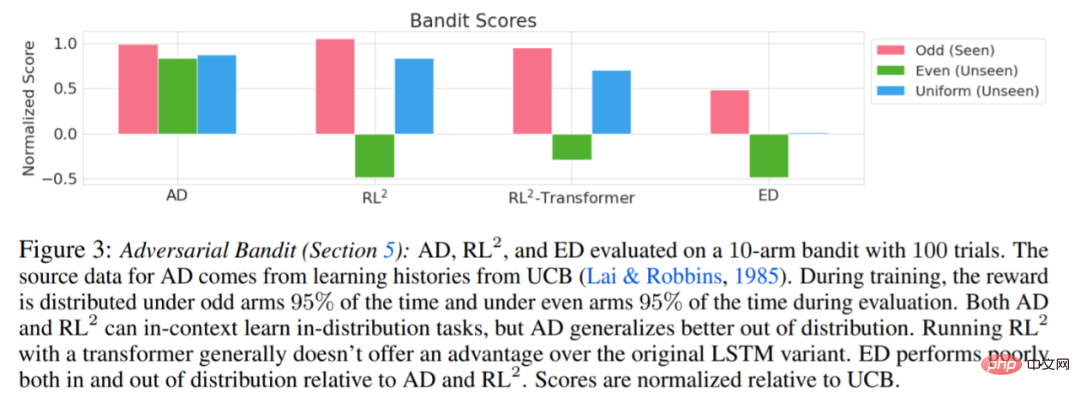
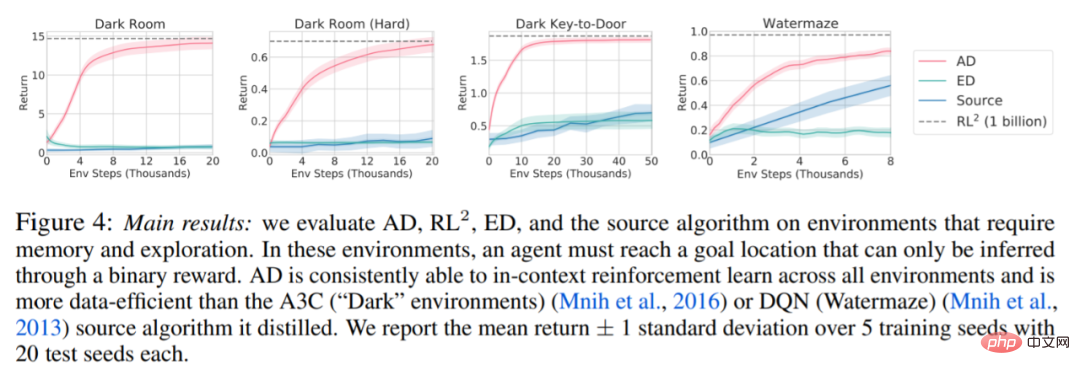
Regarding Figure 4 below, the researcher answered a series of questions. Does AD exhibit contextual reinforcement learning? The results show that AD contextual reinforcement learning can learn in all environments, in contrast, ED cannot explore and learn in context in most situations.
Can AD learn from pixel-based observations? The results show that AD maximizes episodic regression via contextual RL, while ED fails to learn.
AD Is it possible to learn an RL algorithm that is more efficient than the algorithm that generated the source data? The results show that the data efficiency of AD is significantly higher than the source algorithms (A3C and DQN).
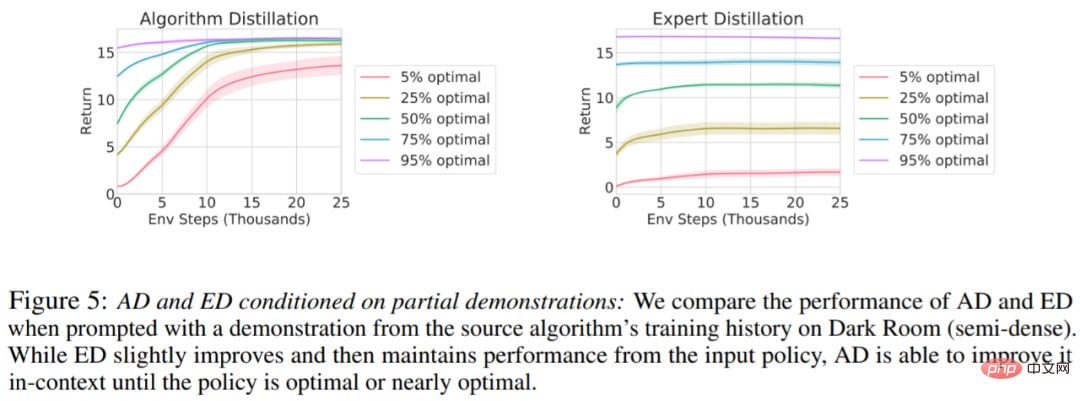
Is it possible to speed up AD by demo? To answer this question, this study retains the sampling strategy at different points along the history of the source algorithm in the test set data, then, uses this strategy data to pre-populate the context of AD and ED, and runs both methods in the context of Dark Room, The results are plotted in Figure 5. While ED maintains the performance of the input policy, AD improves each policy in context until it is close to optimal. Importantly, the more optimized the input strategy is, the faster AD improves it until it reaches optimality.
For more details, please refer to the original paper.
The above is the detailed content of New DeepMind research: transformer can improve itself without human intervention. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
If you need to know how to use filtering with multiple criteria in Excel, the following tutorial will guide you through the steps to ensure you can filter and sort your data effectively. Excel's filtering function is very powerful and can help you extract the information you need from large amounts of data. This function can filter data according to the conditions you set and display only the parts that meet the conditions, making data management more efficient. By using the filter function, you can quickly find target data, saving time in finding and organizing data. This function can not only be applied to simple data lists, but can also be filtered based on multiple conditions to help you locate the information you need more accurately. Overall, Excel’s filtering function is a very practical
 DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
DeepMind robot plays table tennis, and its forehand and backhand slip into the air, completely defeating human beginners
Aug 09, 2024 pm 04:01 PM
But maybe he can’t defeat the old man in the park? The Paris Olympic Games are in full swing, and table tennis has attracted much attention. At the same time, robots have also made new breakthroughs in playing table tennis. Just now, DeepMind proposed the first learning robot agent that can reach the level of human amateur players in competitive table tennis. Paper address: https://arxiv.org/pdf/2408.03906 How good is the DeepMind robot at playing table tennis? Probably on par with human amateur players: both forehand and backhand: the opponent uses a variety of playing styles, and the robot can also withstand: receiving serves with different spins: However, the intensity of the game does not seem to be as intense as the old man in the park. For robots, table tennis
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
