
 Technology peripherals
AI
A Chinese team successfully developed AI to predict suitable drugs for cancer patients, and the results were published in the Nature sub-journal
Technology peripherals
AI
A Chinese team successfully developed AI to predict suitable drugs for cancer patients, and the results were published in the Nature sub-journal
A Chinese team successfully developed AI to predict suitable drugs for cancer patients, and the results were published in the Nature sub-journal

With just one AI, the clinical responses of 9,808 cancer patients to drugs can be fully predicted.
And the results are consistent with clinical observations.
This is the latest result CODE-AE (context-aware deconfounding autoencoder) brought by Lei Xie's team at the City University of New York.

It proposes a novel contextual autoencoding model that can predict the specific responses of different patients to drugs.
This will have a significant impact on new drug development and clinical trials.
You must know that under the traditional model, it takes nearly 10 years to develop, test, and fully market a new drug, and the funds consumed are unprecedentedly huge, easily reaching 1 billion U.S. dollars.
The cycle is so long because the reaction of new drugs in the human body is difficult to predict, and repeated trials are often required for testing.
If AI can use data to make predictions, it will significantly shorten the time to market for new drugs and reduce costs.
Currently, this research has been published in the Nature sub-journal "Nature Machine Intelligence".
Simply put, CODE-AE uses data from in vitro cell validation of new drugs to predict the response of the drug in the human body.
This avoids the dependence of AI model training on patient clinical data.
The biggest reason why AI has not been very effective in clinical response prediction in the past is that it is too difficult to collect massive and continuous clinical response data.
From a mechanism perspective, researchers divide drug biomarkers into source domain and target domain.
The source domain represents a different domain than the test sample, but has rich supervision information, which can be understood as in vitro cell verification data.
The target domain is the domain where the test sample is located. It has no labels or only a small number of labels, that is, patient data.
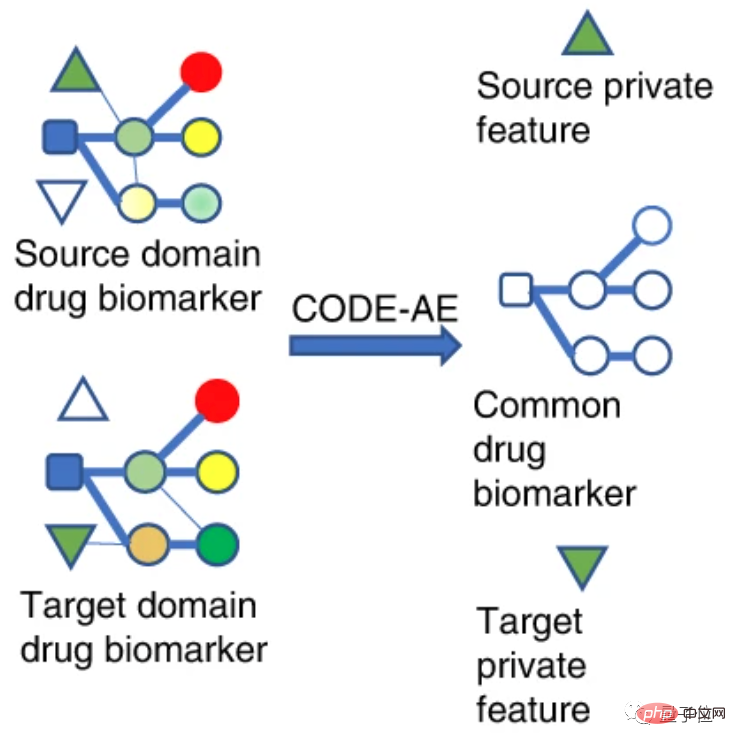
Map data features from different fields to the same feature space so that their distances in this space are as close as possible.
So the objective function trained on the source domain in the feature space can be transferred to the target domain to improve the accuracy in the target domain.
In the context of this research, the source domain and the target domain are both data characteristics of drug biomarkers, that is, data characteristics of drug targets.
Looking specifically at the model framework, it is mainly divided into three parts: pre-training, fine-tuning and inference.
Pre-training mainly uses self-supervised learning to build a feature encoding module to map the unlabeled gene expression profiles of in vitro cell data and patient data into the embedding space. In this way, some confounding factors can be eliminated and the latent distribution of the two data can be consistent to eliminate systematic bias.
The fine-tuning stage is to add a supervised model on the basis of pre-training and use labeled in vitro cell data for training.
Finally, in the inference stage, the patients obtained from pre-training are first disambiguated and embedded, and then the tuned model is used to predict the patient's response to the drug.

In this mode, CODE-AE has two characteristics.
First, it can extract common biological signals and private representations in incoherent samples, thereby eliminating interference caused by different data patterns.
Second, after separating the drug response signal and confounding factors, local alignment can also be achieved.
To summarize, CODE-AE can be understood as the process of selecting unique features in the incoherent data pattern embedding space of labeled and unlabeled data.
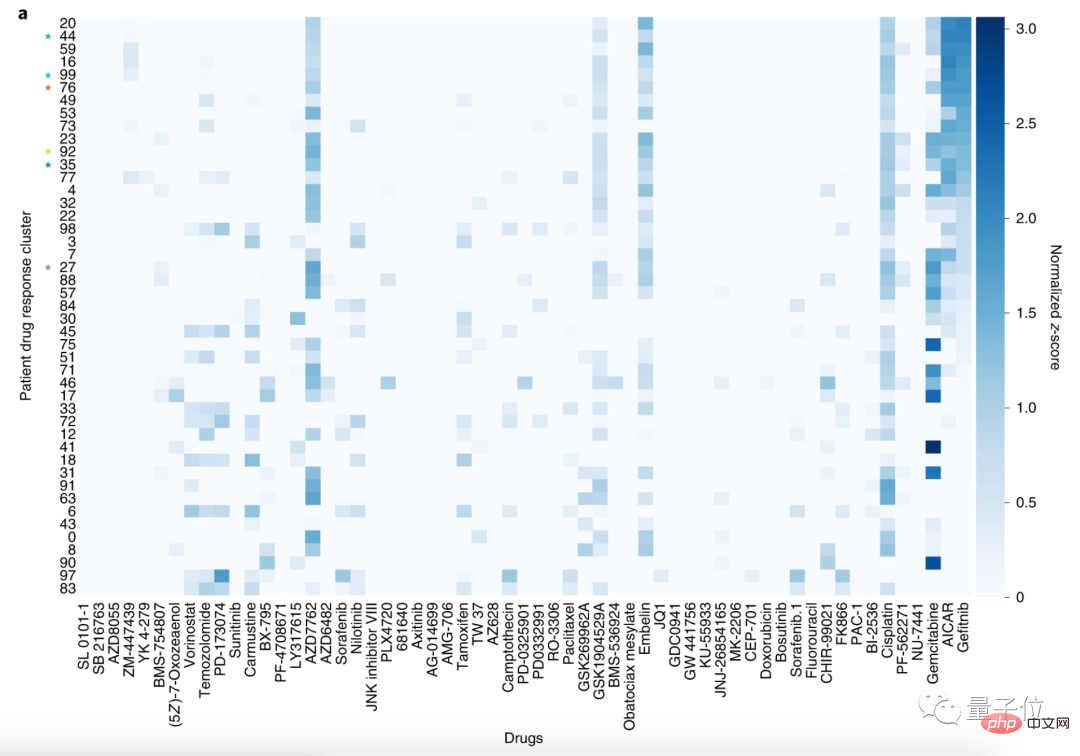
To demonstrate the effectiveness of the model, the researchers predicted the drug suitability of 9,808 cancer patients.
If the site results predicted by the model for the patient's condition are related to the drug target he uses, it proves that the prediction is correct.
The researchers then divided the patients into 100 clusters and the 59 drugs into 30 clusters.
Through this analysis method, patients with similar drug response profiles can be grouped together.
Here, we take the clustering of patients with lung squamous cell carcinoma (LSCC) and non-small cell lung cancer (NSCLC) as an example.
Among the 59 drugs, the most sensitive drugs for LSCC are gefitinib, AICAR and gemcitabine.
The targets of gefitinib and AICAR are both epidermal growth factor receptors (EGFR), and gemcitabine is often used to treat non-small cell lung cancer without EGFR mutations.
The paper stated that, consistent with the action modes of these drugs, CODE-AE found that patients using gefitinib and AICAR had similar drug response profiles.
In other words, CODE-AE has discovered the correct target for patient treatment, that is, it can predict applicable drugs.
The above research team is from the City University of New York.
The corresponding author is Lei Xie, who graduated from the University of Science and Technology of China in polymer physics.
He graduated with a master's degree in computer science from Rutgers University; his doctorate was also from Rutgers University, but with a degree in chemistry.

It is understood that the next step of the research team will be to develop the CODE-AE prediction function for the concentration and metabolism of the clinical response of new drugs.
The researchers said that the AI model may also be adapted to predict the side effects of drugs on the human body.
It is worth mentioning that the Nature sub-journal "Nature Machine Intelligence" specializes in interdisciplinary applied research in artificial intelligence and life sciences, and the average number of papers included every year is about 60.
Paper address: https://www.nature.com/articles/s42256-022-00541-0
Reference link: https://phys.org/news/2022-10 -ai-accurately-human-response-drug.html
The above is the detailed content of A Chinese team successfully developed AI to predict suitable drugs for cancer patients, and the results were published in the Nature sub-journal. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
This article describes how to adjust the logging level of the ApacheWeb server in the Debian system. By modifying the configuration file, you can control the verbose level of log information recorded by Apache. Method 1: Modify the main configuration file to locate the configuration file: The configuration file of Apache2.x is usually located in the /etc/apache2/ directory. The file name may be apache2.conf or httpd.conf, depending on your installation method. Edit configuration file: Open configuration file with root permissions using a text editor (such as nano): sudonano/etc/apache2/apache2.conf
 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
 Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
The steps to install an SSL certificate on the Debian mail server are as follows: 1. Install the OpenSSL toolkit First, make sure that the OpenSSL toolkit is already installed on your system. If not installed, you can use the following command to install: sudoapt-getupdatesudoapt-getinstallopenssl2. Generate private key and certificate request Next, use OpenSSL to generate a 2048-bit RSA private key and a certificate request (CSR): openss
 How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
Managing Hadoop logs on Debian, you can follow the following steps and best practices: Log Aggregation Enable log aggregation: Set yarn.log-aggregation-enable to true in the yarn-site.xml file to enable log aggregation. Configure log retention policy: Set yarn.log-aggregation.retain-seconds to define the retention time of the log, such as 172800 seconds (2 days). Specify log storage path: via yarn.n
