

what is linux channel

Pipeline is a communication method between Linux processes. Two processes can transfer information through a shared memory area, and the data in the pipe can only flow in one direction, that is to say, there can only be fixed writing process and reading process. Currently, in any shell, you can use "|" to connect two commands. The shell will connect the input and output of the two processes with a pipe to achieve the purpose of inter-process communication.

#The operating environment of this tutorial: linux7.3 system, Dell G3 computer.
Pipes are the oldest inter-process communication method in the UNIX environment. This article mainly explains how to use pipes in the Linux environment.
What is a pipeline?
Pipe, English is pipe. Pipes are a communication method between Linux processes. Two processes can transfer information through a shared memory area, and the data in the pipe can only flow in one direction, which means that there can only be fixed writing processes and reading processes. .
The inventor of the pipeline is Douglas McElroy, who was also the inventor of the early shell on UNIX. After he invented the shell, he discovered that when executing commands in system operations, there was often a need to transfer the output of one program to another program for processing. This operation can be accomplished using input and output redirection and adding files, such as:
[zorro@zorro-pc pipe]$ ls -l /etc/ > etc.txt [zorro@zorro-pc pipe]$ wc -l etc.txt 183 etc.txt
But this seems too troublesome. Therefore, the concept of pipeline came into being. Currently in any shell, you can use "|" to connect two commands. The shell will connect the input and output of the two processes with a pipe to achieve the purpose of inter-process communication:
[zorro@zorro-pc pipe]$ ls -l /etc/ | wc -l 183
Compare the above In both methods, we can also understand that a pipe is essentially a file. The previous process opens the file in writing mode, and the subsequent process opens it in reading mode. In this way, after writing in front and reading later, communication is achieved. In fact, the design of the pipeline also follows the UNIX "everything is a file" design principle. It is essentially a file. The Linux system directly implements the pipeline into a file system, and uses VFS to provide operating interfaces for applications.
Although the implementation is a file, the pipeline itself does not occupy disk or other external storage space. In the Linux implementation, it occupies memory space. Therefore, a pipe on Linux is a memory buffer whose operation mode is a file.
Classification and use of pipes
There are two types of pipes on Linux:
Anonymous pipes
Named Pipes
These two types of pipes are also called named or unnamed pipes. The most common form of anonymous pipes is the "|" we most commonly use in shell operations. Its characteristic is that it can only be used in parent-child processes. The parent process must open a pipe file before spawning a child process, and then fork to spawn the child process. In this way, the child process obtains the descriptor of the same pipe file by copying the process address space of the parent process. , in order to achieve the purpose of using the same pipeline for communication. At this time, no one except the parent and child processes knows the descriptor of this pipe file, so the information in this pipe cannot be passed to other processes. This ensures the security of transmitted data, but of course also reduces the versatility of the pipe, so the system also provides named pipes.
We can use the mkfifo or mknod command to create a named pipe, which is no different from creating a file:
[zorro@zorro-pc pipe]$ mkfifo pipe [zorro@zorro-pc pipe]$ ls -l pipe prw-r--r-- 1 zorro zorro 0 Jul 14 10:44 pipe
You can see the created file type comparison Special, it is type p. Indicates that this is a pipeline file. With this pipe file, there is a global name for a pipe in the system, so any two unrelated processes can communicate through this pipe file. For example, let us now let a process write this pipe file:
[zorro@zorro-pc pipe]$ echo xxxxxxxxxxxxxx > pipe
At this time, the write operation will be blocked because no one is reading at the other end of the pipe. This is the kernel's default behavior for pipe file definitions. At this time, if there is a process reading this pipe, then the blocking of this write operation will be lifted:
[zorro@zorro-pc pipe]$ cat pipe xxxxxxxxxxxxxx
As you can observe, after we cat the file, the echo command on the other end Also returned. This is a named pipe.
Linux system uses the same file system operation behavior at the bottom layer for both named pipes and anonymous pipes. This file system is called pipefs. You can find out whether your system supports this file system in the /etc/proc/filesystems file:
[zorro@zorro-pc pipe]$ cat /proc/filesystems |grep pipefs nodev pipefs
观察完了如何在命令行中使用管道之后,我们再来看看如何在系统编程中使用管道。
PIPE
我们可以把匿名管道和命名管道分别叫做PIPE和FIFO。这主要因为在系统编程中,创建匿名管道的系统调用是pipe(),而创建命名管道的函数是mkfifo()。使用mknod()系统调用并指定文件类型为为S_IFIFO也可以创建一个FIFO。
使用pipe()系统调用可以创建一个匿名管道,这个系统调用的原型为:
#include <unistd.h> int pipe(int pipefd[2]);
这个方法将会创建出两个文件描述符,可以使用pipefd这个数组来引用这两个描述符进行文件操作。pipefd[0]是读方式打开,作为管道的读描述符。pipefd[1]是写方式打开,作为管道的写描述符。从管道写端写入的数据会被内核缓存直到有人从另一端读取为止。我们来看一下如何在一个进程中使用管道,虽然这个例子并没有什么意义:
[zorro@zorro-pc pipe]$ cat pipe.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
if (write(pipefd[1], STRING, strlen(STRING)) < 0) {
perror("write()");
exit(1);
}
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
exit(0);
}这个程序创建了一个管道,并且对管道写了一个字符串之后从管道读取,并打印在标准输出上。用一个图来说明这个程序的状态就是这样的:

一个进程自己给自己发送消息这当然不叫进程间通信,所以实际情况中我们不会在单个进程中使用管道。进程在pipe创建完管道之后,往往都要fork产生子进程,成为如下图表示的样子:
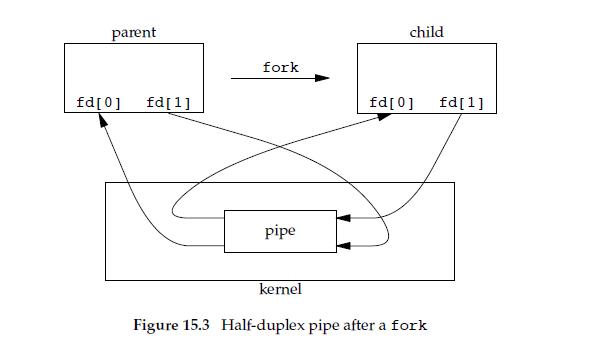
如图中描述,fork产生的子进程会继承父进程对应的文件描述符。利用这个特性,父进程先pipe创建管道之后,子进程也会得到同一个管道的读写文件描述符。从而实现了父子两个进程使用一个管道可以完成半双工通信。此时,父进程可以通过fd[1]给子进程发消息,子进程通过fd[0]读。子进程也可以通过fd[1]给父进程发消息,父进程用fd[0]读。程序实例如下:
[zorro@zorro-pc pipe]$ cat pipe_parent_child.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
bzero(buf, BUFSIZ);
snprintf(buf, BUFSIZ, "Message from child: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
} else {
/* this is parent */
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
sleep(1);
bzero(buf, BUFSIZ);
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
wait(NULL);
}
exit(0);
}父进程先给子进程发一个消息,子进程接收到之后打印消息,之后再给父进程发消息,父进程再打印从子进程接收到的消息。程序执行效果:
[zorro@zorro-pc pipe]$ ./pipe_parent_child Parent pid is: 8309 Child pid is: 8310 Message from parent: My pid is: 8309 Message from child: My pid is: 8310
从这个程序中我们可以看到,管道实际上可以实现一个半双工通信的机制。使用同一个管道的父子进程可以分时给对方发送消息。我们也可以看到对管道读写的一些特点,即:
在管道中没有数据的情况下,对管道的读操作会阻塞,直到管道内有数据为止。当一次写的数据量不超过管道容量的时候,对管道的写操作一般不会阻塞,直接将要写的数据写入管道缓冲区即可。
当然写操作也不会再所有情况下都不阻塞。这里我们要先来了解一下管道的内核实现。上文说过,管道实际上就是内核控制的一个内存缓冲区,既然是缓冲区,就有容量上限。我们把管道一次最多可以缓存的数据量大小叫做PIPESIZE。内核在处理管道数据的时候,底层也要调用类似read和write这样的方法进行数据拷贝,这种内核操作每次可以操作的数据量也是有限的,一般的操作长度为一个page,即默认为4k字节。我们把每次可以操作的数据量长度叫做PIPEBUF。POSIX标准中,对PIPEBUF有长度限制,要求其最小长度不得低于512字节。PIPEBUF的作用是,内核在处理管道的时候,如果每次读写操作的数据长度不大于PIPEBUF时,保证其操作是原子的。而PIPESIZE的影响是,大于其长度的写操作会被阻塞,直到当前管道中的数据被读取为止。
在Linux 2.6.11之前,PIPESIZE和PIPEBUF实际上是一样的。在这之后,Linux重新实现了一个管道缓存,并将它与写操作的PIPEBUF实现成了不同的概念,形成了一个默认长度为65536字节的PIPESIZE,而PIPEBUF只影响相关读写操作的原子性。从Linux 2.6.35之后,在fcntl系统调用方法中实现了F_GETPIPE_SZ和F_SETPIPE_SZ操作,来分别查看当前管道容量和设置管道容量。管道容量容量上限可以在/proc/sys/fs/pipe-max-size进行设置。
#define BUFSIZE 65536
......
ret = fcntl(pipefd[1], F_GETPIPE_SZ);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
printf("PIPESIZE: %d\n", ret);
ret = fcntl(pipefd[1], F_SETPIPE_SZ, BUFSIZE);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
......PIPEBUF和PIPESIZE对管道操作的影响会因为管道描述符是否被设置为非阻塞方式而有行为变化,n为要写入的数据量时具体为:
O_NONBLOCK关闭,n <= PIPE_BUF:
n个字节的写入操作是原子操作,write系统调用可能会因为管道容量(PIPESIZE)没有足够的空间存放n字节长度而阻塞。
O_NONBLOCK打开,n <= PIPE_BUF:
如果有足够的空间存放n字节长度,write调用会立即返回成功,并且对数据进行写操作。空间不够则立即报错返回,并且errno被设置为EAGAIN。
O_NONBLOCK关闭,n > PIPE_BUF:
对n字节的写入操作不保证是原子的,就是说这次写入操作的数据可能会跟其他进程写这个管道的数据进行交叉。当管道容量长度低于要写的数据长度的时候write操作会被阻塞。
O_NONBLOCK打开,n > PIPE_BUF:
如果管道空间已满。write调用报错返回并且errno被设置为EAGAIN。如果没满,则可能会写入从1到n个字节长度,这取决于当前管道的剩余空间长度,并且这些数据可能跟别的进程的数据有交叉。
以上是在使用半双工管道的时候要注意的事情,因为在这种情况下,管道的两端都可能有多个进程进行读写处理。如果再加上线程,则事情可能变得更复杂。实际上,我们在使用管道的时候,并不推荐这样来用。管道推荐的使用方法是其单工模式:即只有两个进程通信,一个进程只写管道,另一个进程只读管道。实现为:
[zorro@zorro-pc pipe]$ cat pipe_parent_child2.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
close(pipefd[1]);
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
} else {
/* this is parent */
close(pipefd[0]);
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
wait(NULL);
}
exit(0);
}这个程序实际上比上一个要简单,父进程关闭管道的读端,只写管道。子进程关闭管道的写端,只读管道。整个管道的打开效果最后成为下图所示:
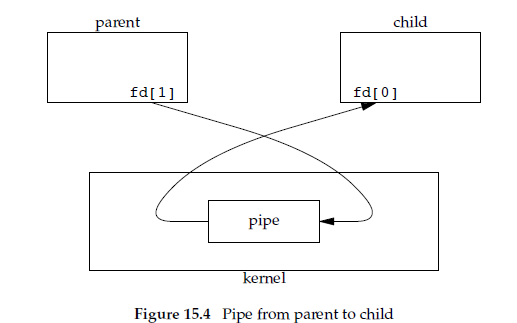
此时两个进程就只用管道实现了一个单工通信,并且这种状态下不用考虑多个进程同时对管道写产生的数据交叉的问题,这是最经典的管道打开方式,也是我们推荐的管道使用方式。另外,作为一个程序员,即使我们了解了Linux管道的实现,我们的代码也不能依赖其特性,所以处理管道时该越界判断还是要判断,该错误检查还是要检查,这样代码才能更健壮。
FIFO
命名管道在底层的实现跟匿名管道完全一致,区别只是命名管道会有一个全局可见的文件名以供别人open打开使用。再程序中创建一个命名管道文件的方法有两种,一种是使用mkfifo函数。另一种是使用mknod系统调用,例子如下:
[zorro@zorro-pc pipe]$ cat mymkfifo.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stderr, "Argument error!\n");
exit(1);
}
/*
if (mkfifo(argv[1], 0600) < 0) {
perror("mkfifo()");
exit(1);
}
*/
if (mknod(argv[1], 0600|S_IFIFO, 0) < 0) {
perror("mknod()");
exit(1);
}
exit(0);
}我们使用第一个参数作为创建的文件路径。创建完之后,其他进程就可以使用open()、read()、write()标准文件操作等方法进行使用了。其余所有的操作跟匿名管道使用类似。需要注意的是,无论命名还是匿名管道,它的文件描述都没有偏移量的概念,所以不能用lseek进行偏移量调整。
相关推荐:《Linux视频教程》
The above is the detailed content of what is linux channel. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 How to view the docker process
Apr 15, 2025 am 11:48 AM
How to view the docker process
Apr 15, 2025 am 11:48 AM
Docker process viewing method: 1. Docker CLI command: docker ps; 2. Systemd CLI command: systemctl status docker; 3. Docker Compose CLI command: docker-compose ps; 4. Process Explorer (Windows); 5. /proc directory (Linux).
 What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 vscode cannot install extension
Apr 15, 2025 pm 07:18 PM
vscode cannot install extension
Apr 15, 2025 pm 07:18 PM
The reasons for the installation of VS Code extensions may be: network instability, insufficient permissions, system compatibility issues, VS Code version is too old, antivirus software or firewall interference. By checking network connections, permissions, log files, updating VS Code, disabling security software, and restarting VS Code or computers, you can gradually troubleshoot and resolve issues.
 Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
VS Code is available on Mac. It has powerful extensions, Git integration, terminal and debugger, and also offers a wealth of setup options. However, for particularly large projects or highly professional development, VS Code may have performance or functional limitations.
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
 What is the main purpose of Linux?
Apr 16, 2025 am 12:19 AM
What is the main purpose of Linux?
Apr 16, 2025 am 12:19 AM
The main uses of Linux include: 1. Server operating system, 2. Embedded system, 3. Desktop operating system, 4. Development and testing environment. Linux excels in these areas, providing stability, security and efficient development tools.
 How to run java code in notepad
Apr 16, 2025 pm 07:39 PM
How to run java code in notepad
Apr 16, 2025 pm 07:39 PM
Although Notepad cannot run Java code directly, it can be achieved by using other tools: using the command line compiler (javac) to generate a bytecode file (filename.class). Use the Java interpreter (java) to interpret bytecode, execute the code, and output the result.
 How to use VSCode
Apr 15, 2025 pm 11:21 PM
How to use VSCode
Apr 15, 2025 pm 11:21 PM
Visual Studio Code (VSCode) is a cross-platform, open source and free code editor developed by Microsoft. It is known for its lightweight, scalability and support for a wide range of programming languages. To install VSCode, please visit the official website to download and run the installer. When using VSCode, you can create new projects, edit code, debug code, navigate projects, expand VSCode, and manage settings. VSCode is available for Windows, macOS, and Linux, supports multiple programming languages and provides various extensions through Marketplace. Its advantages include lightweight, scalability, extensive language support, rich features and version
