

Is the network structure of computer vision about to undergo another innovation?
From convolutional neural networks to visual Transformers with attention mechanisms, neural network models treat the input image as a grid or patch sequence, but this method cannot capture the changes or complexity. object.
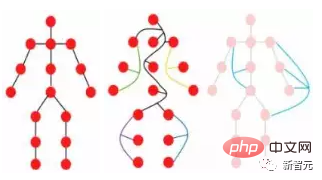
For example, when people observe a picture, they will naturally divide the entire picture into multiple objects, and establish spatial and other positional relationships between the objects. In other words, the entire picture is very important to the human brain. It is actually a graph, and objects are nodes on the graph.
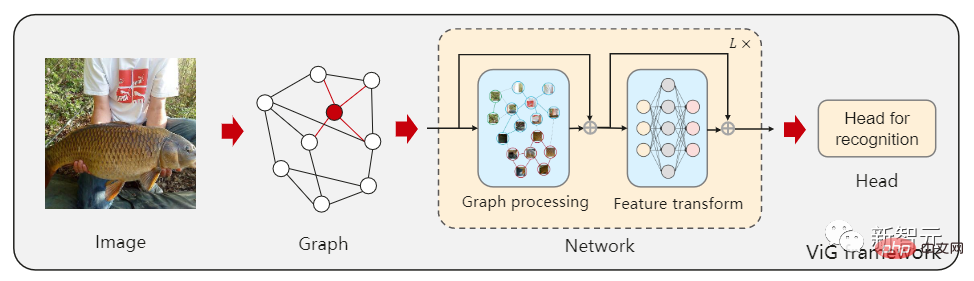
Recently, researchers from the Institute of Software of the Chinese Academy of Sciences, Huawei's Noah's Ark Laboratory, Peking University, and the University of Macau jointly proposed a new model architecture Vision GNN (ViG) can extract graph-level features from images for vision tasks.

Paper link: https://arxiv.org/pdf/2206.00272.pdf
First, the image needs to be divided into several patches as in the figure nodes, and build a graph by connecting nearest neighbor patches, and then use the ViG model to transform and exchange the information of all nodes in the entire graph.
ViG consists of two basic modules. The Grapher module uses graph convolution to aggregate and update graph information, and the FFN module uses two linear layers to transform node features.
Experiments conducted on image recognition and object detection tasks have also proven the superiority of the ViG architecture. The pioneering research of GNN on general vision tasks will provide useful inspiration and experience for future research.
The author of the paper is Professor Wu Enhua, a doctoral supervisor at the Institute of Software, Chinese Academy of Sciences, and an honorary professor at the University of Macau. He graduated from the Department of Engineering Mechanics and Mathematics of Tsinghua University in 1970 and his PhD from the Department of Computer Science at the University of Manchester in the UK in 1980. The main research areas are computer graphics and virtual reality, including: virtual reality, photorealistic graphics generation, physics-based simulation and real-time computing, physics-based modeling and rendering, image and video processing and modeling, visual computing and machines study.
Network structure is often the most critical factor in improving performance. As long as the quantity and quality of data can be guaranteed, changing the model from CNN to ViT will result in a better performance model.
But different networks treat input images differently. CNN slides the window on the image and introduces translation invariance and local features.
ViT and multi-layer perceptron (MLP) convert the image into a patch sequence, such as dividing a 224×224 image into several 16×16 patches, and finally form an input with a length of 196 sequence.
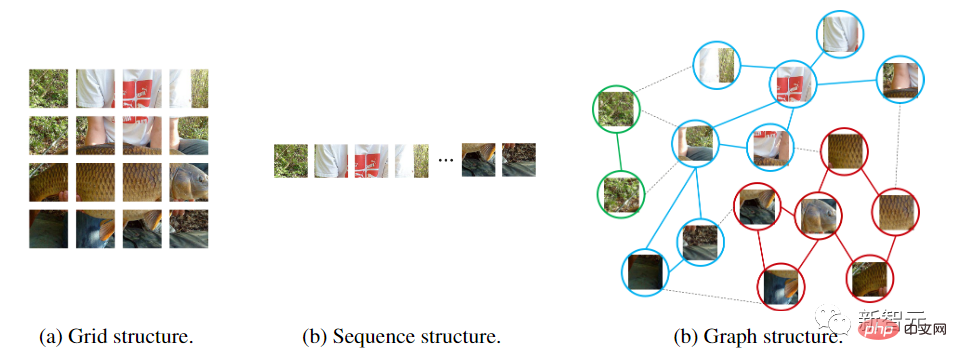
Graph neural networks are more flexible. For example, in computer vision, a basic task is to identify objects in images. Since objects are usually not quadrilateral and may have irregular shapes, the grid or sequence structures commonly used in previous networks such as ResNet and ViT are redundant and inflexible to handle.
An object can be viewed as consisting of multiple parts. For example, a person can be roughly divided into head, upper body, arms and legs.
These parts connected by joints naturally form a graphic structure. By analyzing the diagram, we can finally identify that the object may be a human.
In addition, graph is a general data structure, and grid and sequence can be regarded as a special case of graph. Thinking of an image as a graph is more flexible and efficient for visual perception.
Using the graph structure requires dividing the input image into several patches and treating each patch as a node. If each pixel is treated as a node, it will lead to too many nodes in the graph ( >10K).
# After establishing the graph, first aggregate the features between adjacent nodes through a graph convolutional neural network (GCN) and extract the representation of the image.
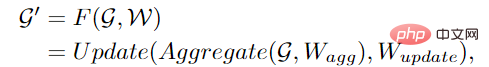
In order to allow GCN to obtain more diverse features, the author applies multi-head operation to graph convolution. The aggregated features are updated by heads with different weights. The final stage The connection is an image representation.
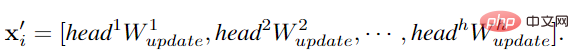
Previous GCNs usually reused several graph convolutional layers to extract aggregate features of graph data, while the over-smoothing phenomenon in deep GCNs will reduce the uniqueness of node features, resulting in The performance of visual recognition is degraded.
# To alleviate this problem, researchers introduced more feature transformations and nonlinear activation functions in the ViG block.
First apply a linear layer before and after graph convolution to project node features into the same domain to increase feature diversity. Inserting a non-linear activation function after graph convolution to avoid layer collapse.
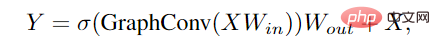
In order to further improve the feature conversion capability and alleviate the over-smoothing phenomenon, it is also necessary to use a feedforward network (FFN) on each node. The FFN module is a simple multi-layer perceptron with two fully connected layers.
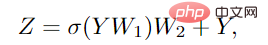
In the Grapher and FFN modules, batch normalization is performed after each fully connected layer or graph convolution layer. The stack of the Grapher module and the FFN module constitutes a ViG Blocks are also the basic unit for building large networks.
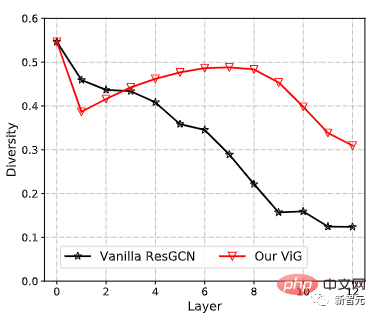
Compared with the original ResGCN, the newly proposed ViG can maintain the diversity of features. As more layers are added, the network can also learn stronger representations.
In computer vision network architecture, commonly used Transformer models usually have an isotropic structure (such as ViT), while CNN prefers to use a pyramid structure (such as ResNet).
In order to compare with other types of neural networks, the researchers established two network architectures for ViG: isotropic and pyramid.
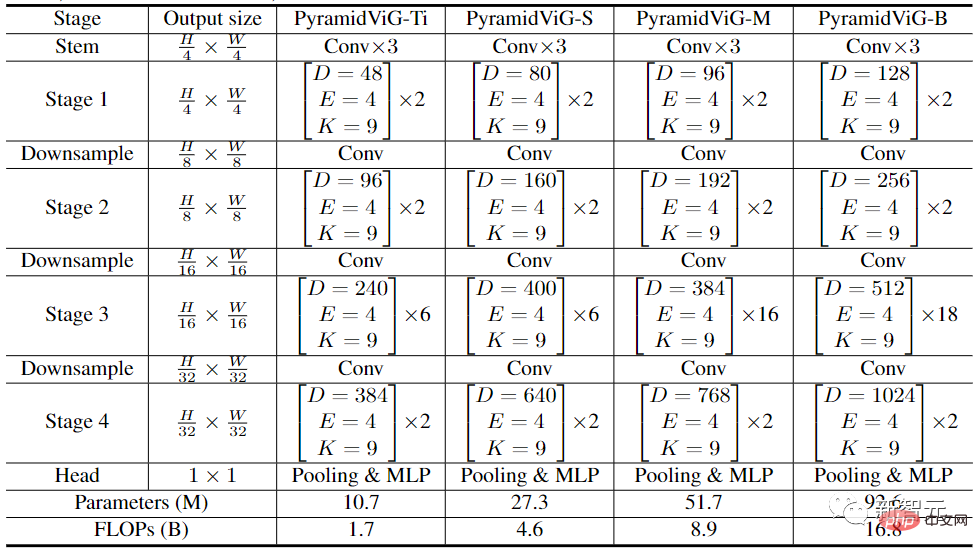
In the experimental comparison stage, the researchers selected the ImageNet ILSVRC 2012 data set in the image classification task, which contains 1000 categories, 120M training images and 50K verification images.
In the target detection task, the COCO 2017 data set with 80 target categories was selected, including 118k training images and 5000 verification set images.

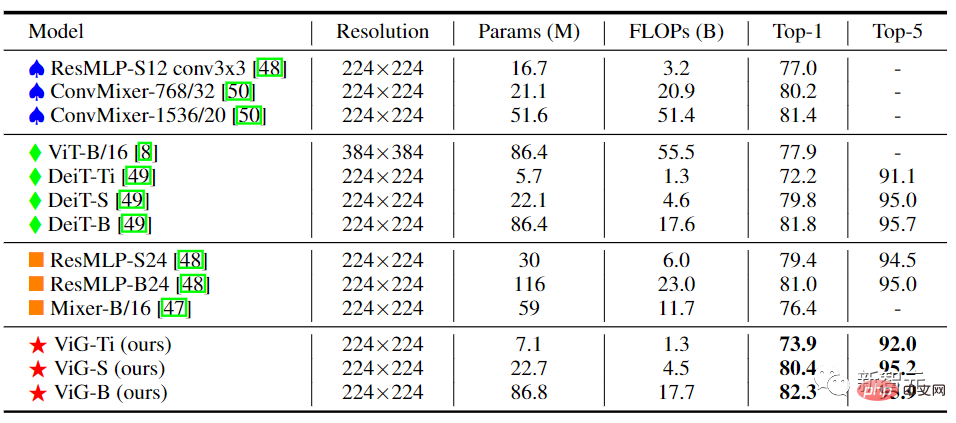
In the isotropic ViG architecture, the feature size can be kept unchanged during its main calculation process, which is easy to expand and friendly to hardware acceleration. After comparing it with existing isotropic CNNs, Transformers, and MLPs, we can see that ViG performs better than other types of networks. Among them, ViG-Ti achieved a top-1 accuracy of 73.9%, which is 1.7% higher than the DeiT-Ti model, while the computational cost is similar.
In the pyramid-structured ViG, as the network deepens, the spatial size of the feature map is gradually reduced, and the scale invariant characteristics of the image are used to generate multi-scale features at the same time.
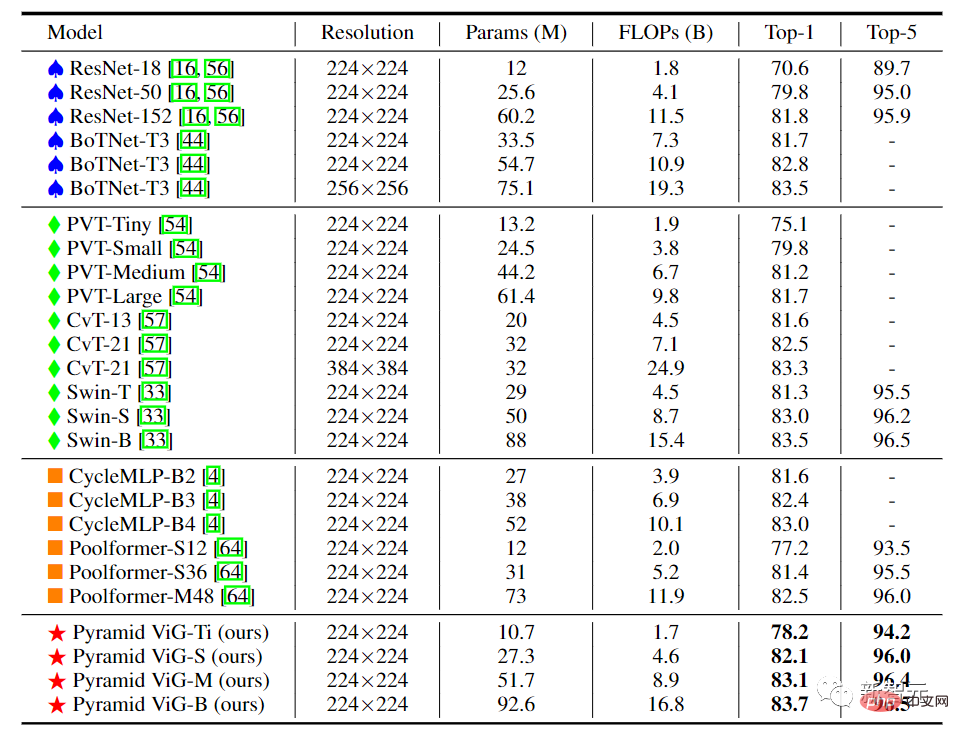
High-performance networks mostly use pyramid structures, such as ResNet, Swin Transformer and CycleMLP. After comparing Pyramid ViG with these representative pyramid networks, it can be seen that the Pyramid ViG series can surpass or rival the state-of-the-art pyramid networks including CNN, MLP, and Transformer.
The results show that graph neural networks can complete visual tasks well and may become a basic component in computer vision systems.
In order to better understand the workflow of the ViG model, the researchers visualized the graph structure built in ViG-S. Plots of samples at two different depths (blocks 1 and 12). The pentagram is the central node and nodes with the same color are its neighbors. Only the two central nodes are visualized because drawing all the edges would look cluttered.

It can be observed that the ViG model can select content-related nodes as first-order neighbors. At shallow levels, neighbor nodes are often selected based on low-level and local features, such as color and texture. At deep levels, the neighbors of the central node are more semantic and belong to the same category. The ViG network can gradually connect nodes through their content and semantic representation, helping to better identify objects.
The above is the detailed content of The Chinese Academy of Sciences Software released a new CV model ViG that surpasses ViT in performance. Will it become a representative of graph neural networks in the future?. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



