

I recently saw an example of using multi-threading to download files. I found it very interesting. I explored it and tried to use multi-threading to copy files locally. After finishing writing, I found that the two are actually very similar. Whether it is local file copying or network multi-threaded downloading, the use of streams is the same. For the local file system, the input stream is obtained from a file in the local file system. For network resources, it is obtained from a file on the remote server.
Note: Although many people have written this multi-threaded download code, not everyone may understand it. I will write it again here, ha. .
An obvious benefit of using multi-threading is: Use the idle CPU to speed up. But note that the more threads, the better. Although it seems that n threads download together, each thread downloads a small part, and the download time will become 1/n. This is a very simple understanding, just like it takes 100 days for one person to build a house, but it only takes 1/10 day for 10,000 people? (This is an exaggeration, haha!)
Switching between threads also requires system overhead, and the number of threads must be controlled within a reasonable range.
This class is relatively unique. It can read data from the file and write data to the file. But it is not a subclass of OutputStream and InputStream, it is a class that implements these two interfaces DataOutput and DataInput.
Introduction in API:
Instances of this class support reading and writing random access files. Randomly accessing a file behaves like a large number of bytes stored in the file system. There is a type of cursor, or index into an implicit array, called a file pointer; input operations read bytes starting at the file pointer and extend the file pointer past the bytes read. The output operation is also available if the random access file is created in read/write mode; the output operation writes bytes starting at the file pointer and advances the file pointer to the bytes written. Output operations writing to the current side of an implicit array cause the array to be expanded. The file pointer can be read by the getFilePointer method and set by the seek method .
So, the most important thing about this class is the seek method. Using the seek method, you can control the writing position, so it is much easier to implement multi-threading. Therefore, whether it is local file copying or network multi-thread downloading, this class is needed.
The specific idea is: First use RandomAccessFile to create a File object, and then set the size of the file. (Yes, it can set the file size directly.) Set this file to be the same as the file you want to copy or download. (Although we have not written data to this file, this file has been created.) Divide the file into several parts and use threads to copy or download the contents of each part.
This is somewhat similar to file overwriting. If an existing file starts writing data from the head of the file and writes to the end of the file, then the original file will no longer exist and becomes New file written.
Set the file size:
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
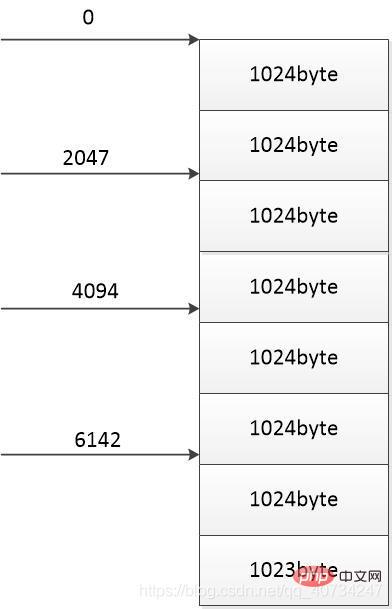
}Use pictures to illustrate: This picture represents a file with a size of 8191 bytes: The size of each part is: 8191 / 4 = 2047 bytes
Divide this file into four parts, each part is copied or downloaded using a thread, and each arrow represents the starting download position of a thread. I intentionally left the last part not set to 1024 bytes because files are rarely exactly divisible by 1024 bytes. (The reason why I use 1024 byte is because I will read 1024 byte each time. If 1024 byte is read, otherwise the corresponding number of bytes read will be written).
According to this diagram, each thread downloads 2047 bytes, then the total number of bytes downloaded is: 2047 * 4 = 8188 bytes < 8191 bytes (total size of the file) So this creates a problem. The number of bytes downloaded is less than the total number of bytes. This is a problem, so the number of bytes downloaded must be greater than the total number of bytes. ( It doesn’t matter if there are more, because the parts that are downloaded will be overwritten by the later parts, so there will be no problem. )
So the size of each part should be: 8191 / 4 1 = 2048 bytes. (In this way, the sum of the sizes of the four parts exceeds the total size, and data loss will not occur.)
So, it is necessary to add 1 here.
long size = len / FileCopyUtil.THREAD_NUM + 1;
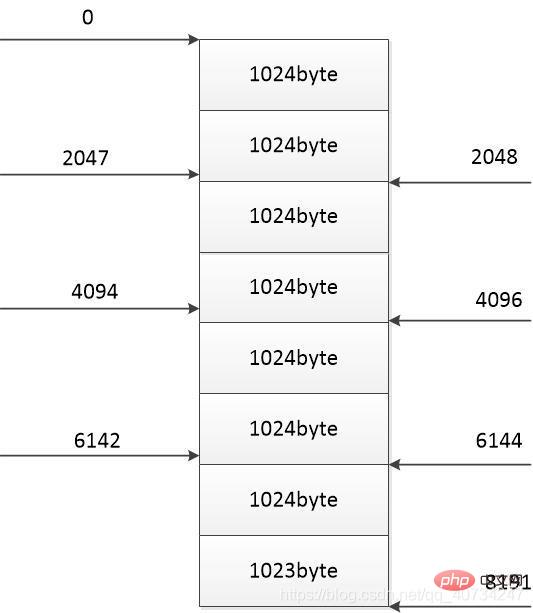
The position where each thread completes the download (right side) Each thread only copies its own part of the download, so no need All content has been downloaded, so an additional judgment will be added to the part where file data is read and written to the file.
这里增加一个计数器:curlen。它表示是当前复制或者下载的长度,然后每次读取后和 size(每部分的大小)进行比较,如果 curlen 大于 size 就表示相应的部分下载完成了(当然了,这些都要在数据没有读取完的条件下判断)。
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position);
raf.seek(position);
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
还有需要注意的是,每个线程下载的时候都要: 1. 输出流设置文件指针的位置。 2. 输入流跳过不需要读取的字节。
这是很重要的一步,应该是很好理解的。
bis.skip(position); raf.seek(position);
package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
/**
* 用于进行文件复制,但不是常规的文件复制 。
* 准备仿照疯狂Java,写一个多线程的文件复制工具。
* 即可以本地复制和网络复制
* */
/**
* 设计思路:
* 获取目标文件的大小,然后设置复制文件的大小(这样做是有好处的),
* 然后使用将文件分为 n 分,使用 n 个线程同时进行复制(这里我将 n 取为 4)。
*
* 可以进一步拓展:
* 加强为断点复制功能,即程序中断以后,
* 仍然可以继续从上次位置恢复复制,减少不必要的重复开销
* */
public class FileCopyUtil {
//设置一个常量,复制线程的数量
private static final int THREAD_NUM = 4;
private FileCopyUtil() {}
/**
* @param targetPath 目标文件的路径
* @param outputPath 复制输出文件的路径
* @throws IOException
* */
public static void transferFile(String targetPath, String outputPath) throws IOException {
File targetFile = new File(targetPath);
File outputFilePath = new File(outputPath);
if (!targetFile.exists() || targetFile.isDirectory()) { //目标文件不存在,或者是一个文件夹,则抛出异常
throw new FileNotFoundException("目标文件不存在:"+targetPath);
}
if (!outputFilePath.exists()) { //如果输出文件夹不存在,将会尝试创建,创建失败,则抛出异常。
if(!outputFilePath.mkdir()) {
throw new FileNotFoundException("无法创建输出文件:"+outputPath);
}
}
long len = targetFile.length();
File outputFile = new File(outputFilePath, "copy"+targetFile.getName());
createOutputFile(outputFile, len); //创建输出文件,设置好大小。
long[] position = new long[4];
//每一个线程需要复制文件的起点
long size = len / FileCopyUtil.THREAD_NUM + 1;
for (int i = 0; i < FileCopyUtil.THREAD_NUM; i++) {
position[i] = i*size;
copyThread(i, position[i], size, targetFile, outputFile);
}
}
//创建输出文件,设置好大小。
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
}
private static void copyThread(int i, long position, long size, File targetFile, File outputFile) {
int n = i; //Lambda 表达式的限制,无法使用变量。
new Thread(()->{
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position); //跳过不需要读取的字节数,注意只能先后跳
raf.seek(position); //跳到需要写入的位置,没有这句话,会出错,但是很难改。
int hasRead = 0;
byte[] b = new byte[1024];
/**
* 注意,每个线程只是读取一部分数据,不能只以 -1 作为循环结束的条件
* 循环退出条件应该是两个,即写入的字节数大于需要读取的字节数 或者 文件读取结束(最后一个线程读取到文件末尾)
*/
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.net.URL;
import java.net.URLConnection;
/*
* 多线程下载文件:
* 通过一个 URL 获取文件输入流,使用多线程技术下载这个文件。
* */
public class FileDownloadUtil {
//下载线程数
private static final int THREAD_NUM = 4;
/**
* @param url 资源位置
* @param output 输出路径
* @throws IOException
* */
public static void transferFile(String url, String output) throws IOException {
init(output);
URL resource = new URL(url);
URLConnection connection = resource.openConnection();
//获取文件类型
String type = connection.getContentType();
if (type != null) {
type = "."+type.split("/")[1];
} else {
type = "";
}
//创建文件,并设置长度。
long len = connection.getContentLength();
String filename = System.currentTimeMillis()+type;
try (RandomAccessFile raf = new RandomAccessFile(new File(output, filename), "rw")){
raf.setLength(len);
}
//为每一个线程分配相应的下载其实位置
long size = len / THREAD_NUM + 1;
long[] position = new long[THREAD_NUM];
File downloadFile = new File(output, filename);
//开始下载文件: 4个线程
download(url, downloadFile, position, size);
}
private static void download(String url, File file, long[] position, long size) throws IOException {
//开始下载文件: 4个线程
for (int i = 0 ; i < THREAD_NUM; i++) {
position[i] = i * size; //每一个线程下载的起始位置
int n = i; // Lambda 表达式的限制,无法使用变量
new Thread(()->{
URL resource = null;
URLConnection connection = null;
try {
resource = new URL(url);
connection = resource.openConnection();
} catch (IOException e) {
e.printStackTrace();
}
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream());
RandomAccessFile raf = new RandomAccessFile(file, "rw")){ //每个流一旦关闭,就不能打开了
raf.seek(position[n]); //跳到需要下载的位置
bis.skip(position[n]); //跳过不需要下载的部分
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position[n]+" "+curlen+" "+size);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}) .start();
}
}
private static void init(String output) throws FileNotFoundException {
File path = new File(output);
if (!path.exists()) {
if (!path.mkdirs()) {
throw new FileNotFoundException("无法创建输出路径:"+output);
}
} else if (path.isFile()) {
throw new FileNotFoundException("输出路径不是一个目录:"+output);
}
}
}因为这个多线程文件复制和多线程下载是很相似的,所以就放在一起测试了。我也想将两个写在一个类里面,这样可以做成方法的重载调用。 文件复制的第一个参数可以是 String 或者 URI。 使用这个作为目标文件的参数。
public File(URI uri)
网络文件下载的第一个参数,可以使用 String 或者是 URL。 不过,因为先写的这个文件复制,后写的多线程下载,就没有做这部分。不过现在这样功能也达到了,可以进行本地文件的复制(多线程)和网络文件的下载(多线程)。
package dragon;
import java.io.IOException;
public class FileCopyTest {
public static void main(String[] args) throws IOException {
//复制文件
long start = System.currentTimeMillis();
try {
FileCopyUtil.transferFile("D:\\DB\\download\\timg.jfif", "D:\\DBC");
} catch (IOException e) {
e.printStackTrace();
}
long time = System.currentTimeMillis()-start;
System.out.println("time: "+time);
//下载文件
start = System.currentTimeMillis();
FileDownloadUtil.transferFile("https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1578151056184&di=594a34f05f3587c31d9377a643ddd72e&imgtype=0&src=http%3A%2F%2Fn.sinaimg.cn%2Fsinacn%2Fw1600h2000%2F20180113%2F0bdc-fyqrewh6850115.jpg", "D:\\DB\\download");
System.out.println("time: "+(System.currentTimeMillis()-start));
}
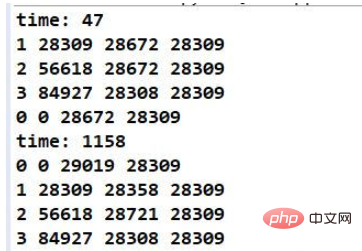
}运行截图: 注意:这里这个时间并不是复制和下载需要的时间,实际上它没有这个功能!
注意:虽然两部分代码是相同的,但是第三列数字,却不是完全相同的,这个似乎是因为本地和网络得区别吧。但是最后得文件是完全相同的,没有问题得。(我本地文件复制得是网络下载得那张图片,使用图片进行测试有一个好处,就是如果错了一点(字节数目不对),这个图片基本上就会产生问题。)
产生错误之后的图片: 图片无法正常显示,会出现很多的问题,这就说明一定是代码写错了。
The above is the detailed content of Application scenarios and techniques of Java multi-threading and IO streams. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



