
 Technology peripherals
AI
The world's first truly open source ChatGPT large model Dolly 2.0, which can be modified at will for commercial use
Technology peripherals
AI
The world's first truly open source ChatGPT large model Dolly 2.0, which can be modified at will for commercial use
The world's first truly open source ChatGPT large model Dolly 2.0, which can be modified at will for commercial use

As we all know, OpenAI is not Open when it comes to ChatGPT. The Yangtuo series models open sourced from Meta are also "limited to academic research applications" due to issues such as data sets. People are still looking for bypasses. When it comes to restricting methods, here comes the big model that focuses on 100% open source.
On April 12, Databricks released Dolly 2.0, which is another new version of the ChatGPT-like human interactivity (instruction following) large language model (LLM) released two weeks ago .
Databricks says Dolly 2.0 is the industry’s first open source, directive-compliant LLM, fine-tuned on a transparent and freely available dataset that is also open source. Can be used for commercial purposes. This means Dolly 2.0 can be used to build commercial applications without paying for API access or sharing data with third parties.

- Project link: https://huggingface.co/databricks/dolly-v2-12b
- Dataset: https://github.com/databrickslabs/dolly/tree/master/data
According to Databricks CEO Ali Ghodsi, while there are other large models that can be used for commercial purposes, "they don't talk to you like Dolly 2.0." And based on the Dolly 2.0 model, users can modify and improve training data , as it is freely available under an open source license. So you can make your own version of Dolly.
Databricks also released the dataset on which Dolly 2.0 was fine-tuned, called databricks-dolly-15k. This is a corpus of more than 15,000 records generated by thousands of Databricks employees. Databricks calls it "the first open source, human-generated instruction corpus, specifically designed to enable large languages to demonstrate the magical interactivity of ChatGPT" ."
How Dolly 2.0 was born
In the past two months, the industry and academia have caught up with OpenAI and proposed a wave of ChatGPT-like tools that follow instructions. Models, these versions are considered open source by many definitions (or offer some degree of openness or limited access). Among them, Meta's LLaMA has attracted the most attention, which has led to a large number of further improved models, such as Alpaca, Koala, Vicuna, and Databricks' Dolly 1.0.
But on the other hand, many of these "open" models are under "industrial restrictions" because they are trained on datasets with terms designed to limit commercial use - For example, the 52,000 question and answer data set from the StanfordAlpaca project was trained on the output of OpenAI's ChatGPT. And OpenAI’s terms of use include a rule that you can’t use OpenAI’s services to compete with them.
Databricks thought about ways to solve this problem: the newly proposed Dolly 2.0 is a 12 billion parameter language model, which is based on the open source EleutherAI pythia model series and is specifically designed for small open source instruction record corpora Fine-tuned (databricks-dolly-15k), this dataset was generated by Databricks employees and licensed under terms that permit use, modification, and extension for any purpose, including academic or commercial applications.
Until now, models trained on the output of ChatGPT have been in a legal gray area. “The entire community has been tiptoeing around this problem, and everyone is releasing these models, but none of them are commercially available,” Ghodsi said. "That's why we're so excited." "Everyone else wants to go bigger, but we're actually interested in something smaller," Ghodsi said of Dolly of miniature scale. "Secondly, we looked through all the answers and it is of high quality."
Ghodsi said he believes Dolly 2.0 will start a "snowball" effect and allow other players in the field of artificial intelligence to People join in and come up with other alternatives. He explained that restrictions on commercial use were a big hurdle to overcome: "We're excited now because we finally found a way around it. I guarantee you're going to see people applying these 15,000 problems to the real world. Every model there is, they'll see how many of these models suddenly become a little bit magical and you can interact with them."
Hand Rubbing Dataset
To download the weights for the Dolly 2.0 model, simply visit the Databricks Hugging Face page and visit the Dolly repo of databricks-labs to download the databricks-dolly-15k dataset.
The "databricks-dolly-15k" dataset contains 15,000 high-quality human-generated prompt/reply pairs, by more than 5,000 Databricks employees in 2023 Written during March and April, is specifically designed to provide instructions for tuning large language models. These training recordings are natural, expressive and designed to represent a wide range of behaviors, from brainstorming and content generation to information extraction and summarization.
According to the license terms of this data set (Creative Commons Attribution-ShareAlike 3.0 Unported License), anyone can use, modify or extend this data set for any purpose, including commercial applications.
Currently, this dataset is the first open source, human-generated instruction dataset.
Why create such a data set? The team also explained why in a blog post.
A key step in creating Dolly 1.0, or any directive that follows LLM, is to train the model on a dataset of directive and reply pairs. Dolly 1.0 costs $30 to train and uses a dataset created by the Alpaca team at Stanford University using the OpenAI API.
After Dolly 1.0 was released, many people asked to try it out, and some users also wanted to use this model commercially.
But the training dataset contains the output of ChatGPT, and as the Stanford team points out, the terms of service try to prevent anyone from creating a model that competes with OpenAI.
Previously, all well-known directive compliance models (Alpaca, Koala, GPT4All, Vicuna) were subject to this restriction: commercial use was prohibited. To solve this problem, Dolly's team began looking for ways to create a new dataset without restrictions on commercial use.
Specifically, the team learned from a research paper published by OpenAI that the original InstructGPT model was trained on a data set consisting of 13,000 instruction-following behavior demonstrations. Inspired by this, they set out to see if they could achieve similar results, led by Databricks employees.
It turns out that generating 13,000 questions and answers was harder than imagined. Because every answer must be original and cannot be copied from ChatGPT or anywhere on the web, otherwise it will "pollute" the data set. But Databricks has more than 5,000 employees, and they were very interested in LLM. So the team conducted a crowdsourcing experiment that created a higher-quality dataset than what 40 annotators had created for OpenAI.
Of course, this work is time-consuming and labor-intensive. In order to motivate everyone, the team has set up a competition, and the top 20 annotators will receive surprise prizes. At the same time, they also listed 7 very specific tasks:
- Open Q&A: For example, "Why do people like comedy movies?" or "What is the capital of France?" In some cases, there is no one right answer, while in other cases, help is needed Knowledge about the entire world;
- Closed questions and answers: These questions can be answered using only one paragraph of information from a reference. For example, given a Wikipedia paragraph about atoms, one might ask: "What is the ratio of protons to neutrons in the nucleus?";
- Extracting information from Wikipedia: Here, the annotator copies a paragraph from Wikipedia and extracts entities or other factual information from the paragraph, such as weights or measurements;
- summarizes the information on Wikipedia: For this, annotators were provided with a passage from Wikipedia and asked to distill it into a short summary;
- Brainstorming: This task requires open-ended ideation , and lists the relevant possible options. For example "What fun activities can I do with my friends this weekend?";
- Classification: In this task, annotators are asked to make judgments about category membership (e.g., whether the items in the list are animals, minerals, or vegetables), or judging attributes of a short passage, such as the mood of a movie review;
- Creative Writing: This task will include writing a poem or A love letter and more.
Here are some examples:


## Initially, the team was skeptical about reaching 10,000 results. But with nightly leaderboard play, it managed to hit 15,000 results in one week.
The team then shut down the game due to concerns about "tying up staff productivity" (which makes sense).
Feasibility of commercializationAfter the data set was quickly created, the team began to consider commercial applications.
They wanted to make an open source model that could be used commercially. Although databricks-dolly-15k is much smaller than Alpaca (the dataset on which Dolly 1.0 was trained), the Dolly 2.0 model based on EleutherAI pythia-12b exhibits high-quality instruction following behavior.
In hindsight, this is not surprising. After all, many instruction tuning datasets released in recent months contain synthetic data, which often contain hallucinations and factual errors.
databricks-dolly-15k, on the other hand, is generated by professionals, is of high quality, and contains long-form answers to most tasks.
Here are some examples of Dolly 2.0 used for summarization and content generation:

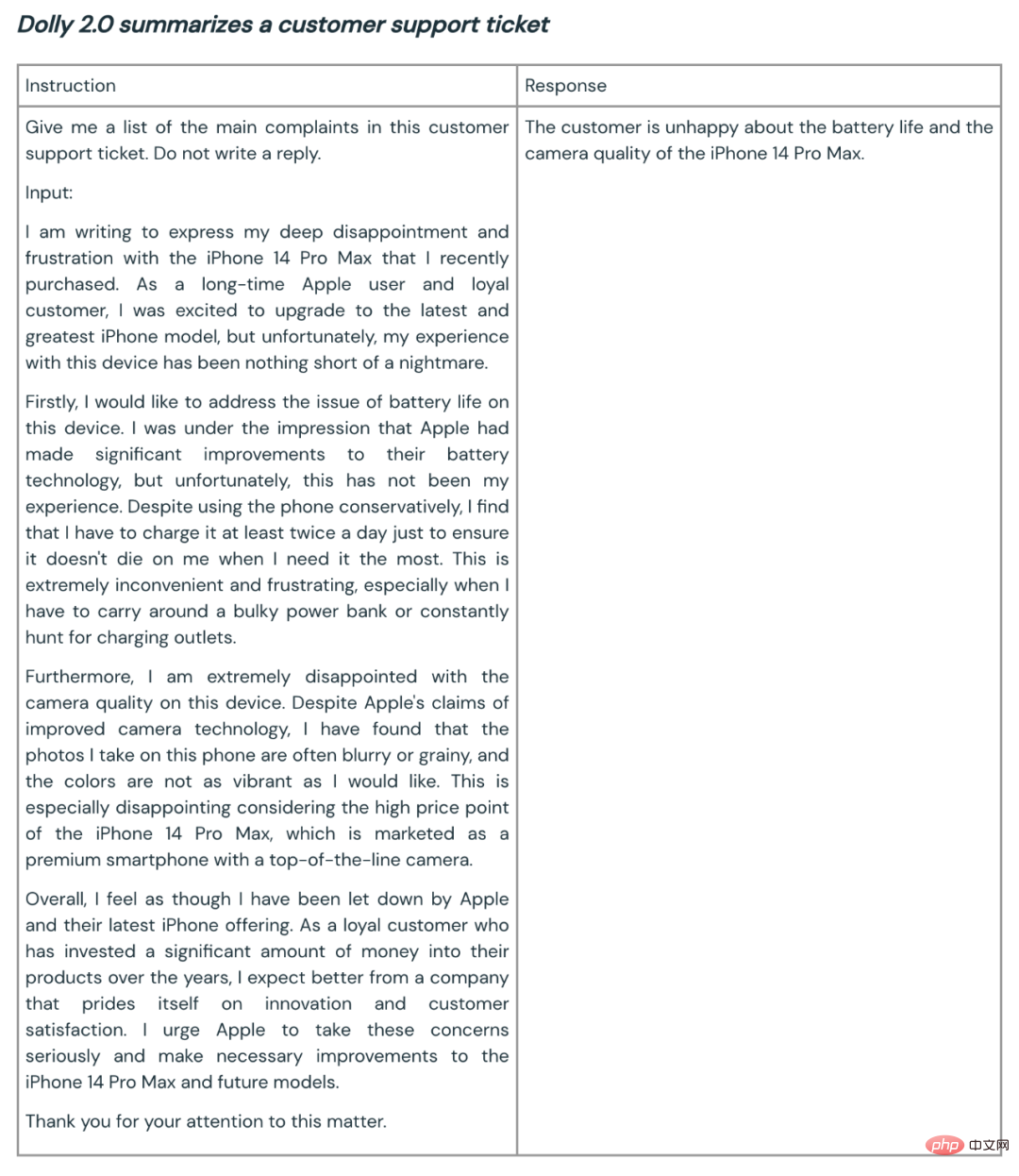

Based on initial customer feedback, the Dolly team says capabilities like this could have broad application across the enterprise. Because many companies want to have their own models to create higher-quality models for their own specific domain applications, rather than handing over their sensitive data to third parties.
The open source of Dolly 2 is a good start for building a better large model ecosystem. Open source datasets and models encourage commentary, research, and innovation, helping to ensure that everyone benefits from advances in AI technology. The Dolly team expects the new model and open-source dataset will serve as the seeds for much subsequent work, helping to lead to more powerful language models.
The above is the detailed content of The world's first truly open source ChatGPT large model Dolly 2.0, which can be modified at will for commercial use. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Text annotation is the work of corresponding labels or tags to specific content in text. Its main purpose is to provide additional information to the text for deeper analysis and processing, especially in the field of artificial intelligence. Text annotation is crucial for supervised machine learning tasks in artificial intelligence applications. It is used to train AI models to help more accurately understand natural language text information and improve the performance of tasks such as text classification, sentiment analysis, and language translation. Through text annotation, we can teach AI models to recognize entities in text, understand context, and make accurate predictions when new similar data appears. This article mainly recommends some better open source text annotation tools. 1.LabelStudiohttps://github.com/Hu
 15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
Image annotation is the process of associating labels or descriptive information with images to give deeper meaning and explanation to the image content. This process is critical to machine learning, which helps train vision models to more accurately identify individual elements in images. By adding annotations to images, the computer can understand the semantics and context behind the images, thereby improving the ability to understand and analyze the image content. Image annotation has a wide range of applications, covering many fields, such as computer vision, natural language processing, and graph vision models. It has a wide range of applications, such as assisting vehicles in identifying obstacles on the road, and helping in the detection and diagnosis of diseases through medical image recognition. . This article mainly recommends some better open source and free image annotation tools. 1.Makesens
 Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Face detection and recognition technology is already a relatively mature and widely used technology. Currently, the most widely used Internet application language is JS. Implementing face detection and recognition on the Web front-end has advantages and disadvantages compared to back-end face recognition. Advantages include reducing network interaction and real-time recognition, which greatly shortens user waiting time and improves user experience; disadvantages include: being limited by model size, the accuracy is also limited. How to use js to implement face detection on the web? In order to implement face recognition on the Web, you need to be familiar with related programming languages and technologies, such as JavaScript, HTML, CSS, WebRTC, etc. At the same time, you also need to master relevant computer vision and artificial intelligence technologies. It is worth noting that due to the design of the Web side
 The source code of 25 AI agents is now public, inspired by Stanford's 'Virtual Town' and 'Westworld'
Aug 11, 2023 pm 06:49 PM
The source code of 25 AI agents is now public, inspired by Stanford's 'Virtual Town' and 'Westworld'
Aug 11, 2023 pm 06:49 PM
Audiences familiar with "Westworld" know that this show is set in a huge high-tech adult theme park in the future world. The robots have similar behavioral capabilities to humans, and can remember what they see and hear, and repeat the core storyline. Every day, these robots will be reset and returned to their initial state. After the release of the Stanford paper "Generative Agents: Interactive Simulacra of Human Behavior", this scenario is no longer limited to movies and TV series. AI has successfully reproduced this scene in Smallville's "Virtual Town" 》Overview map paper address: https://arxiv.org/pdf/2304.03442v1.pdf
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
 Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Let me introduce to you the latest AIGC open source project-AnimagineXL3.1. This project is the latest iteration of the anime-themed text-to-image model, aiming to provide users with a more optimized and powerful anime image generation experience. In AnimagineXL3.1, the development team focused on optimizing several key aspects to ensure that the model reaches new heights in performance and functionality. First, they expanded the training data to include not only game character data from previous versions, but also data from many other well-known anime series into the training set. This move enriches the model's knowledge base, allowing it to more fully understand various anime styles and characters. AnimagineXL3.1 introduces a new set of special tags and aesthetics
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
