
 Java
javaTutorial
What are the four major problems that the Java distributed cache system needs to solve?
Java
javaTutorial
What are the four major problems that the Java distributed cache system needs to solve?
What are the four major problems that the Java distributed cache system needs to solve?

The distributed cache system is an indispensable part of the three-high architecture, which greatly improves the concurrency and response speed of the entire project, but it also brings new problems that need to be solved, namely: Cache penetration , cache breakdown, cache avalanche and cache consistency issues.
Cache Penetration
The first big problem is cache penetration. This concept is easier to understand and is related to hit rate. If the hit rate is low, then the pressure will be concentrated on the database persistence layer.
If we can find relevant data, we can cache it. But the problem is that this request did not hit the cache or persistence layer. This situation is called cache penetration.
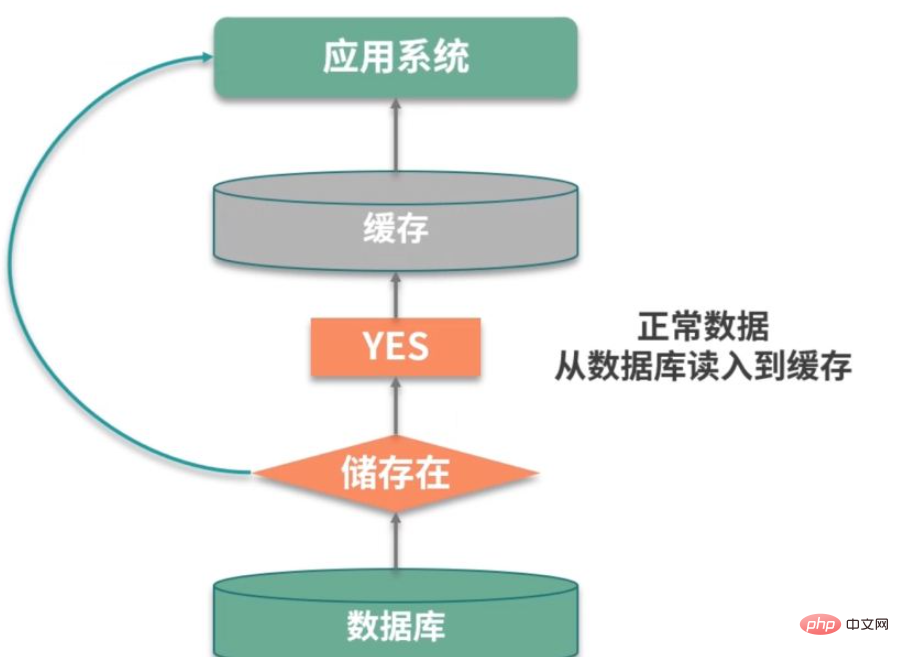
For example, as shown in the figure above, in a login system, there is an external attack, and it keeps trying to log in using non-existent users. These users are virtual and cannot It is effectively cached and will be queried in the database every time, which will eventually cause performance failure of the service.
There are many solutions to this problem, let’s briefly introduce them.
The first is to cache empty objects. Isn't it that the persistence layer cannot find the data? Then we can set the result of this request to null and put it in the cache. By setting a reasonable expiration time, the security of the back-end database can be ensured.
Caching empty objects will occupy additional cache space, and there will also be a time window for data inconsistency, so the second method is to use Bloom filters to process large amounts of regular key values. .
The existence or non-existence of a record is a Bool value, which can be stored using only 1 bit. Bloom filters can compress this yes and no operation into a data structure. For example, data such as mobile phone number and user gender are very suitable for using Bloom filters.
Cache breakdown
Cache breakdown refers to the situation where user requests fall on the database. In most cases, it is caused by the batch expiration of cache time.
We generally set an expiration time for the data in the cache. If a large amount of data is obtained from the database at a certain time and the same expiration time is set, they will expire at the same time, causing a cache breakdown.
For hot data, we can set it not to expire; or update its expiration time when accessing; for cached items stored in batches, try to allocate a relatively average expiration time to avoid Invalid at the same time.
Cache Avalanche
The word avalanche seems scary, but the actual situation is indeed more serious. Caching is used to accelerate the system, and the back-end database is only a backup of data, not a high-availability alternative.
When the cache system fails, traffic will be instantly transferred to the back-end database. Before long, the database will be overwhelmed by the heavy traffic and hang up. This cascading service failure can be vividly called an avalanche.
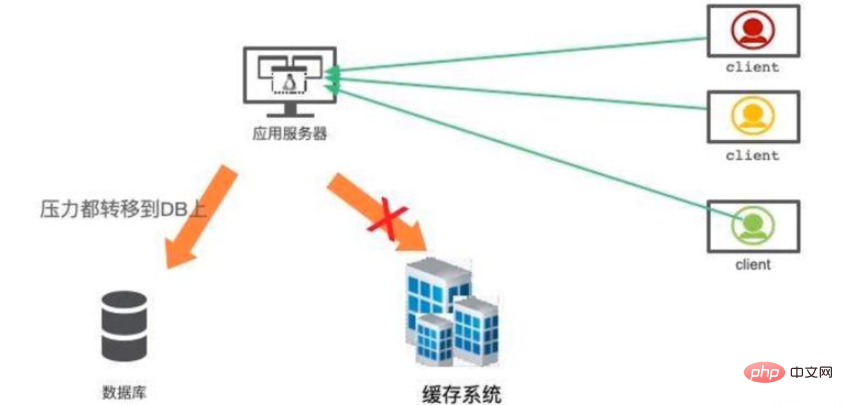
Highly available cache construction is very important. Redis provides master-slave and Cluster modes. The Cluster mode is simple to use, and each shard can also act as a master-slave independently, ensuring extremely high availability.
In addition, we have a general assessment of the performance bottlenecks of the database. If the cache system crashes, you can use the current limiting component to intercept requests flowing to the database.
Cache consistency
After the cache component is introduced, another difficult problem is cache consistency.
Let’s first look at how the problem occurred. For a cache item, there are four commonly used operations: write, update, read, and delete.
Writing: The cache and the database are two different components. As long as double writing is involved, there is a possibility that only one of the writes will succeed, resulting in data inconsistency.
Update: The update situation is similar and two different components need to be updated.
Read: Read to ensure that the information read from the cache is the latest and consistent with that in the database.
Delete: When deleting database records, how to delete the data in the cache?
Because business logic is relatively complex in most cases. The update operations are very expensive. For example, a user's balance is a number calculated by calculating a series of assets. If these associated assets have to refresh the cache every time they are changed, the code structure will be very confusing and impossible to maintain.
I recommend using the triggered cache consistency method, using the lazy loading method, which can make cache synchronization very simple:
When reading the cache At that time, if there is no relevant data in the cache, the relevant business logic is executed, the cache data is constructed and stored in the cache system;
When the resources related to the cache item change, the corresponding cache item is first deleted, then the resource is updated in the database, and finally the corresponding cache item is deleted.
In addition to the simple programming model, this operation has an obvious benefit. I only load this cache into the cache system when I use it. If resources are created and updated every time a modification is made, there will be a lot of cold data in the cache system. This actually implements the Cache-Aside Pattern, which loads data from the data storage to the cache on demand. The biggest effect is to improve performance and reduce unnecessary queries.
But there are still problems with this. The scenario introduced next is also a question often asked in interviews.
The database update action and cache deletion action we mentioned above are obviously not in the same transaction. It may cause the content of the database and the content in the cache to be inconsistent during the update process.
In the interview, as long as you point out this question, the interviewer will raise his thumbs.
You can use distributed locks to solve this problem. You can use locks to isolate database operations and cache operations from other cache read operations. Generally speaking, a read operation does not require locking. When it encounters a lock, it will retry and wait until it times out.
The above is the detailed content of What are the four major problems that the Java distributed cache system needs to solve?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Guide to TimeStamp to Date in Java. Here we also discuss the introduction and how to convert timestamp to date in java along with examples.
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 How to Run Your First Spring Boot Application in Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
How to Run Your First Spring Boot Application in Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifies the creation of robust, scalable, and production-ready Java applications, revolutionizing Java development. Its "convention over configuration" approach, inherent to the Spring ecosystem, minimizes manual setup, allo
