

In recent years, driven by Transformer, machine learning is experiencing a renaissance. Over the past five years, neural architectures for natural language processing, computer vision, and other fields have been largely dominated by transformers.
However, there are many image-level generative models that remain unaffected by this trend. For example, diffusion models have achieved amazing results in image generation in the past year. Almost all of these models Use convolutional U-Net as the backbone. This is a bit surprising! The big story in deep learning over the past few years has been the dominance of Transformer across fields. Is there anything special about U-Net or convolutions that makes them perform so well in diffusion models?
The research that first introduced the U-Net backbone network into the diffusion model can be traced back to Ho et al. This design pattern inherits the autoregressive generation model PixelCNN with only slight changes. PixelCNN consists of convolutional layers, which contain many ResNet blocks. Compared with standard U-Net, PixelCNN's additional spatial self-attention block becomes a basic component in the transformer. Unlike others' studies, Dhariwal and Nichol et al. eliminate several architectural choices of U-Net, such as using adaptive normalization layers to inject condition information and channel counts into the convolutional layers.
In this article, William Peebles from UC Berkeley and Xie Saining from New York University wrote "Scalable Diffusion Models with Transformers". The goal is to uncover the significance of architectural choices in diffusion models and provide guidance for future Generative model studies provide empirical baselines. This study shows that U-Net inductive bias is not critical to the performance of diffusion models and can be easily replaced with standard designs such as transformers.
This finding suggests that diffusion models can benefit from architectural unification trends. For example, diffusion models can inherit best practices and training methods from other fields, retaining the scalability of these models. , robustness and efficiency. A standardized architecture will also open up new possibilities for cross-domain research.

This research focuses on a new class of Transformer-based diffusion models: Diffusion Transformers (DiTs for short). DiTs follow the best practices of Vision Transformers (ViTs), with some small but important tweaks. DiT has been shown to scale more efficiently than traditional convolutional networks such as ResNet.
Specifically, this article studies the scaling behavior of Transformer in terms of network complexity and sample quality. It is shown that by constructing and benchmarking the DiT design space under the latent diffusion model (LDM) framework, where the diffusion model is trained within the latent space of VAE, it is possible to successfully replace the U-Net backbone with a transformer. This paper further shows that DiT is a scalable architecture for diffusion models: there is a strong correlation between network complexity (measured by Gflops) and sample quality (measured by FID). By simply extending DiT and training an LDM with a high-capacity backbone (118.6 Gflops), state-of-the-art results of 2.27 FID are achieved on the class-conditional 256 × 256 ImageNet generation benchmark.
DiTs is a new architecture for diffusion models that aims to be as faithful as possible to the standard transformer architecture in order to retain its scalability. DiT retains many of the best practices of ViT, and Figure 3 shows the complete DiT architecture.
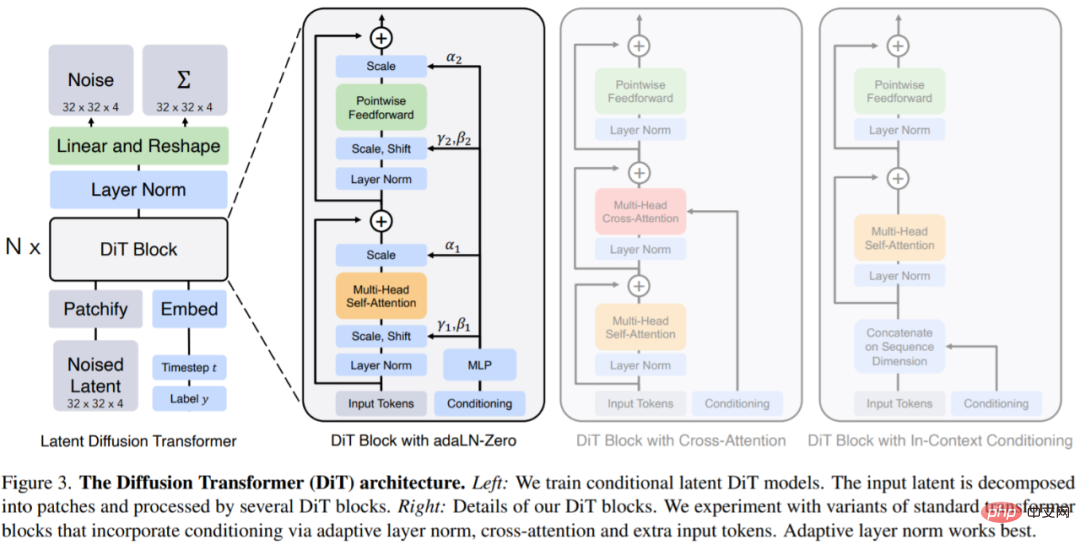
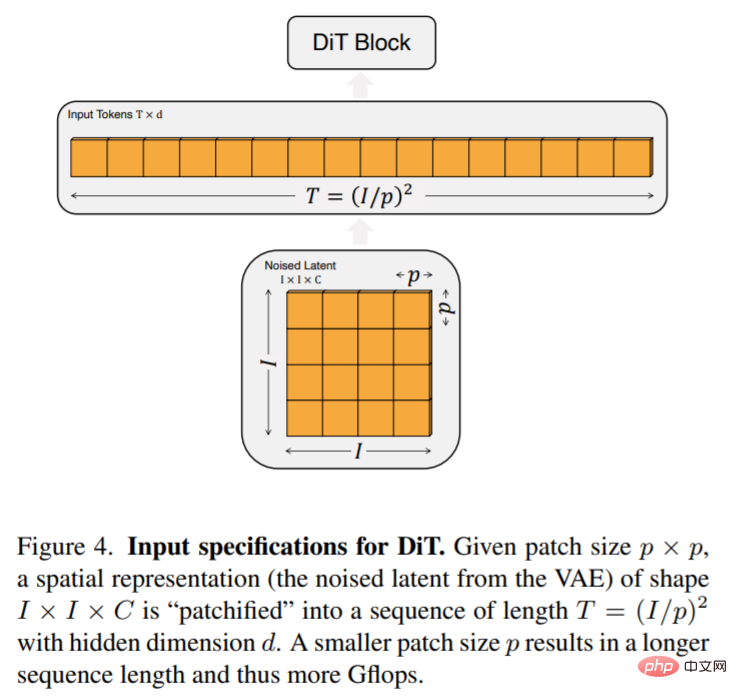
The input to DiT is a spatial representation z (for a 256 × 256 × 3 image, z has a shape of 32 × 32 × 4). The first layer of DiT is patchify, which converts the spatial input into a sequence of T tokens by linearly embedding each patch into the input. After patchify, we apply standard ViT frequency-based positional embeddings to all input tokens.
The number of tokens T created by patchify is determined by the patch size hyperparameter p. As shown in Figure 4, halving p quadruples T and therefore at least quadruples the transformer Gflops. This article adds p = 2,4,8 to the DiT design space.
DiT block design: After patchify, the input token is processed by a series of transformer blocks. In addition to noisy image input, diffusion models sometimes handle additional conditional information, such as noise time step t, class label c, natural language, etc. This article explores four transformer block variations that handle conditional input in different ways. These designs feature minor but significant modifications to the standard ViT block design. The design of all modules is shown in Figure 3.
This article tried four configurations that vary by model depth and width: DiT-S, DiT-B, DiT-L, and DiT-XL. These model configurations range from 33M to 675M parameters and Gflops from 0.4 to 119.
The researchers trained four DiT-XL/2 models with the highest Gflop, each using a different block design - in-context (119.4 Gflops), cross-attention (137.6Gflops), adaptive layer norm (adaLN, 118.6Gflops) or adaLN-zero (118.6Gflops). The FID was then measured during training, and Figure 5 shows the results.
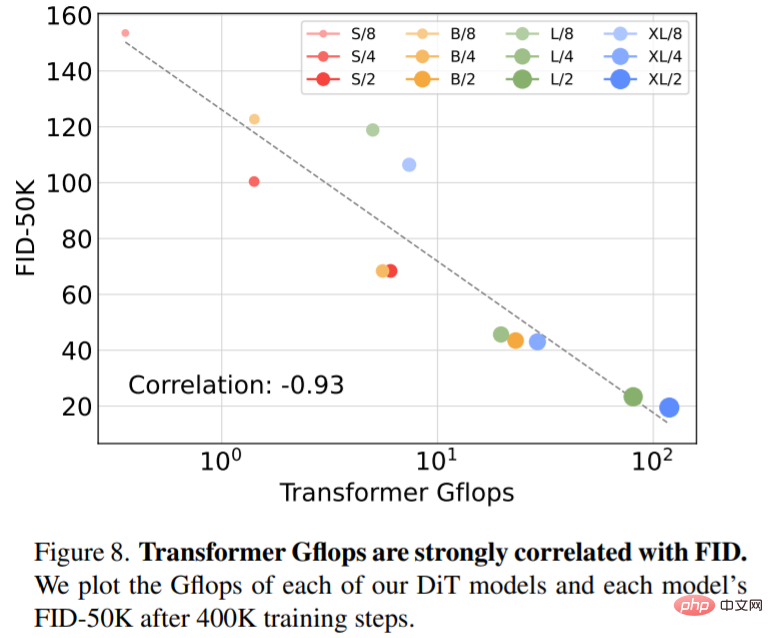
Expand model size and patch size. Figure 2 (left) gives an overview of Gflops for each model and their FID at 400K training iterations. It can be seen that increasing the model size and reducing the patch size produce considerable improvements in the diffusion model.
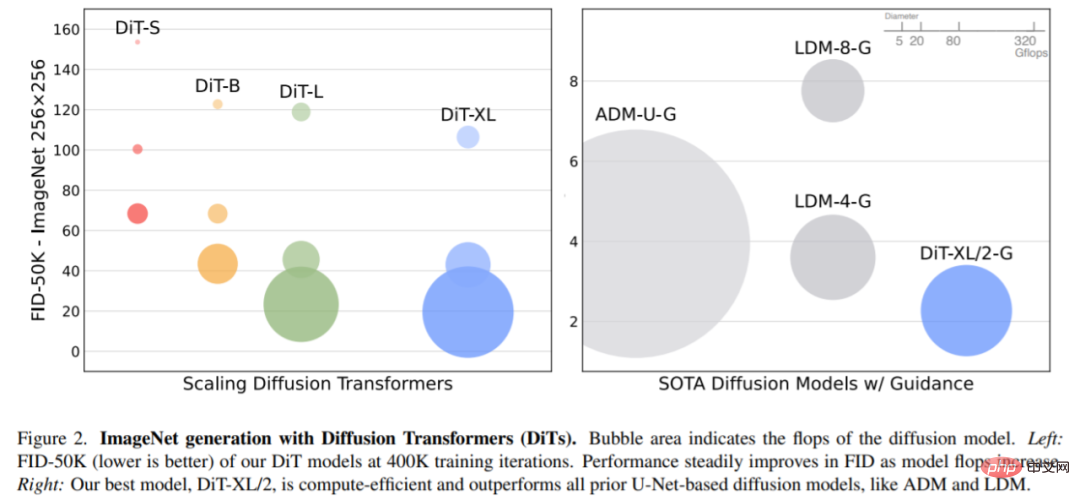
Figure 6 (top) shows how FID changes as the model size increases and the patch size remains constant. Across the four settings, significant improvements in FID are obtained at all stages of training by making the Transformer deeper and wider. Likewise, Figure 6 (bottom) shows the FID when the patch size is reduced and the model size remains constant. The researchers again observed that FID improved considerably by simply expanding the number of tokens processed by DiT and keeping the parameters roughly fixed throughout the training process.
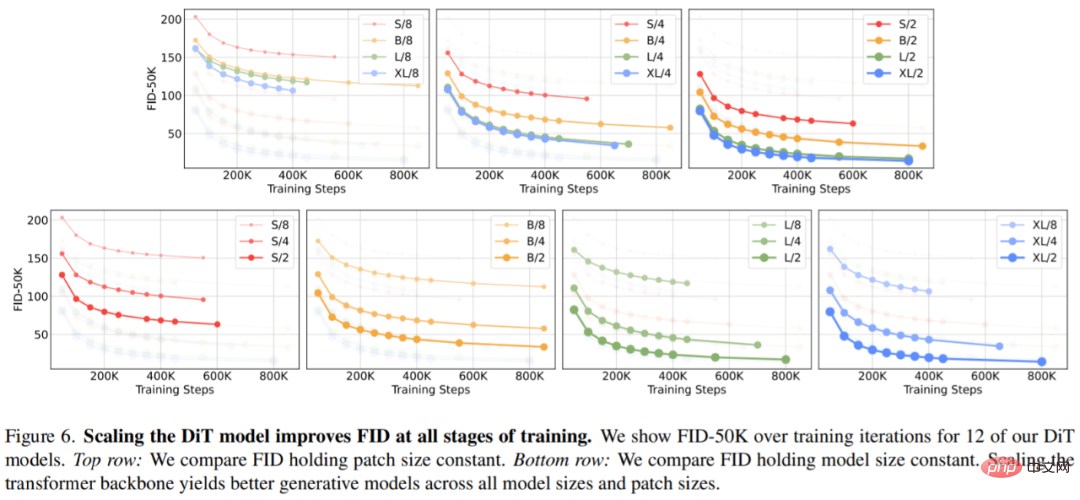
Figure 8 shows the comparison between FID-50K and model Gflops under 400K training steps:
SOTA diffusion model 256×256 ImageNet. After the extended analysis, the researchers continued to train the highest Gflop model, DiT-XL/2, with a step count of 7M. Figure 1 shows a sample of this model and compares it to the category conditional generation SOTA model, and the results are shown in Table 2.

When using no classifier guidance, DiT-XL/2 outperforms all previous diffusion models, surpassing the 3.60 previously achieved by LDM Best FID-50K dropped to 2.27. As shown in Figure 2 (right), compared to latent space U-Net models such as LDM-4 (103.6 Gflops), DiT-XL/2 (118.6 Gflops) is much more computationally efficient than ADM (1120 Gflops). ) or ADM-U (742 Gflops), pixel-space U-Net models are much more efficient.
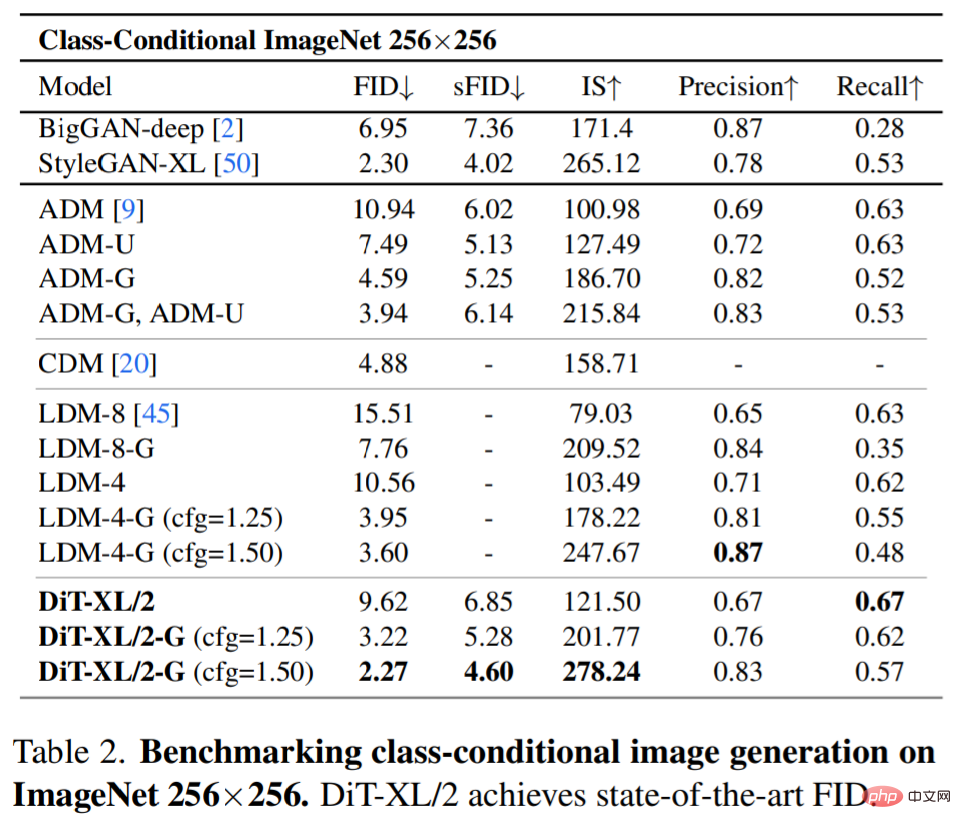
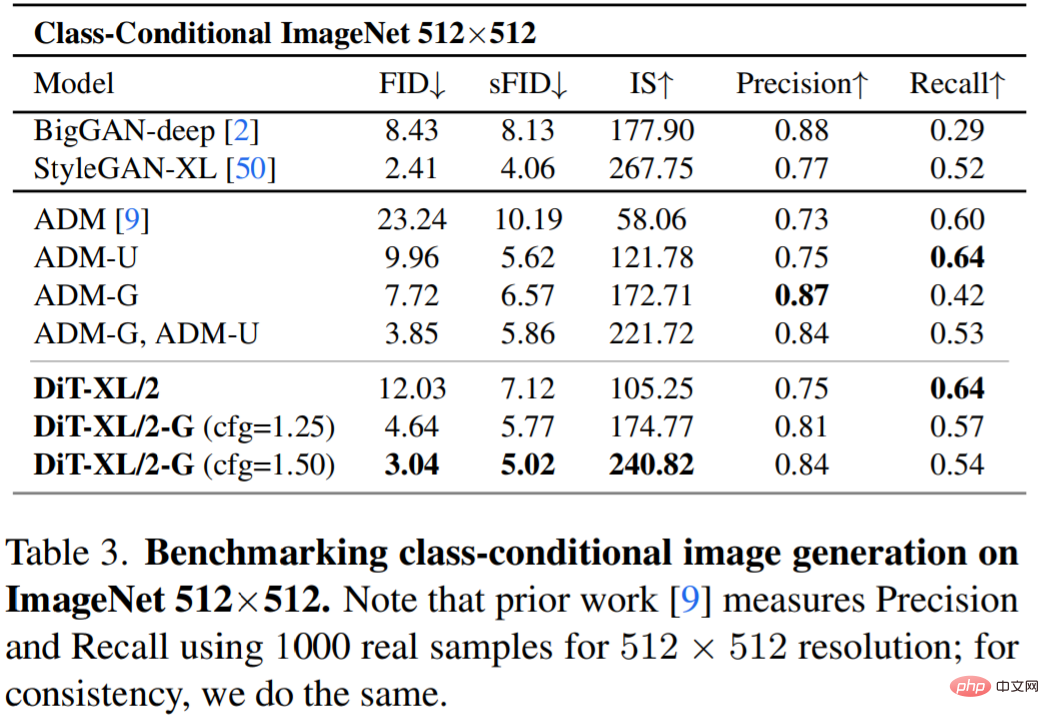
Table 3 shows the comparison with the SOTA approach. XL/2 again outperforms all previous diffusion models at this resolution, improving ADM's previous best FID of 3.85 to 3.04.
For more research details, please refer to the original paper.
The above is the detailed content of From U-Net to DiT: Application of Transformer Technology in Dominance Diffusion Model. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



